

一文搞懂 Linux 內(nèi)核的 4 大 IO 調(diào)度算法
Linux 內(nèi)核包含4個IO調(diào)度器,分別是 Noop IO scheduler、Anticipatory IO scheduler、Deadline IO scheduler 與 CFQ IO scheduler。
anticipatory, 預(yù)期的;提早發(fā)生的;期待著的
通常磁盤的讀寫影響是由磁頭到柱面移動造成了延遲,解決這種延遲內(nèi)核主要采用兩種策略:緩存和IO調(diào)度算法來進行彌補.
調(diào)度算法概念
-
當(dāng)向設(shè)備寫入數(shù)據(jù)塊或是從設(shè)備讀出數(shù)據(jù)塊時,請求都被安置在一個隊列中等待完成. -
每個塊設(shè)備都有它自己的隊列. -
I/O調(diào)度程序負責(zé)維護這些隊列的順序,以更有效地利用介質(zhì).I/O調(diào)度程序?qū)o序的I/O操作變?yōu)橛行虻腎/O操作. -
內(nèi)核必須首先確定隊列中一共有多少個請求,然后才開始進行調(diào)度. 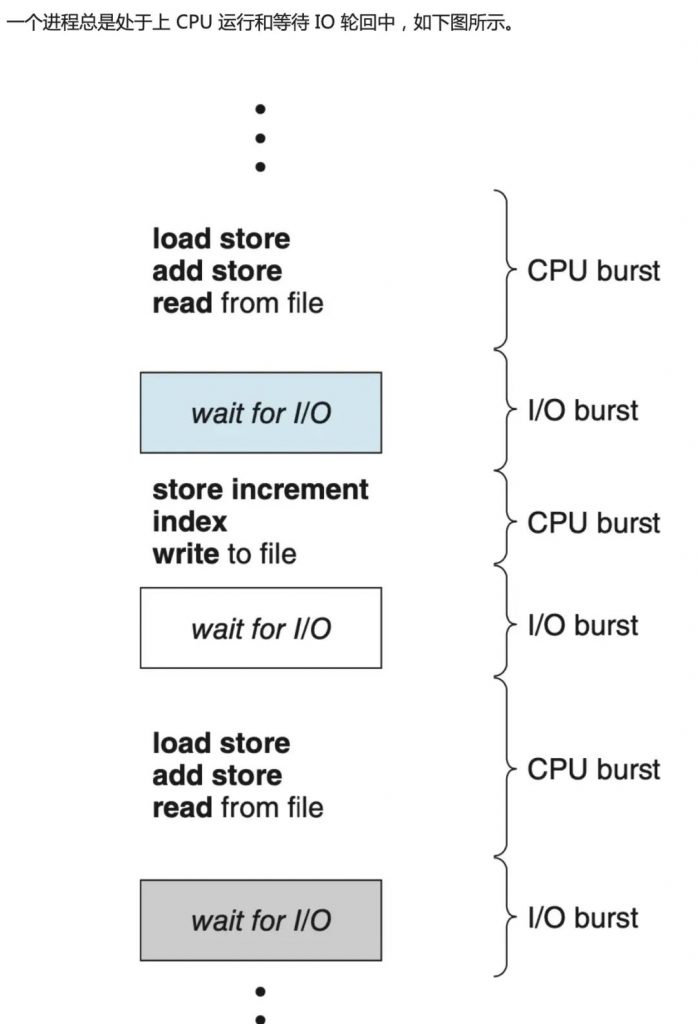

IO調(diào)度器(IO Scheduler)
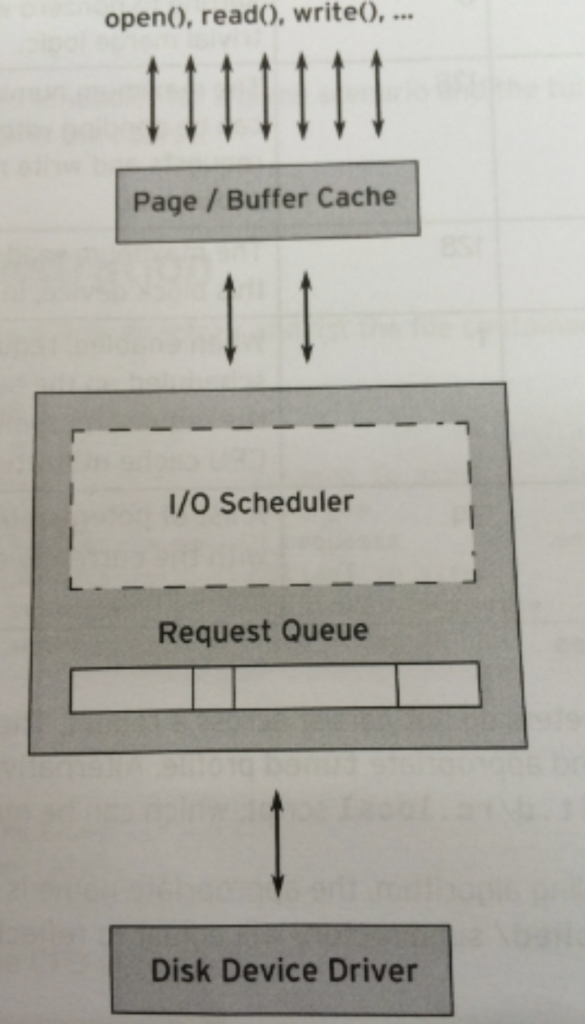
IO調(diào)度器(IO Scheduler)是操作系統(tǒng)用來決定塊設(shè)備上IO操作提交順序的方法。存在的目的有兩個,一是提高IO吞吐量,二是降低IO響應(yīng)時間。
然而IO吞吐量和IO響應(yīng)時間往往是矛盾的,為了盡量平衡這兩者,IO調(diào)度器提供了多種調(diào)度算法來適應(yīng)不同的IO請求場景。其中,對數(shù)據(jù)庫這種隨機讀寫的場景最有利的算法是DEANLINE。
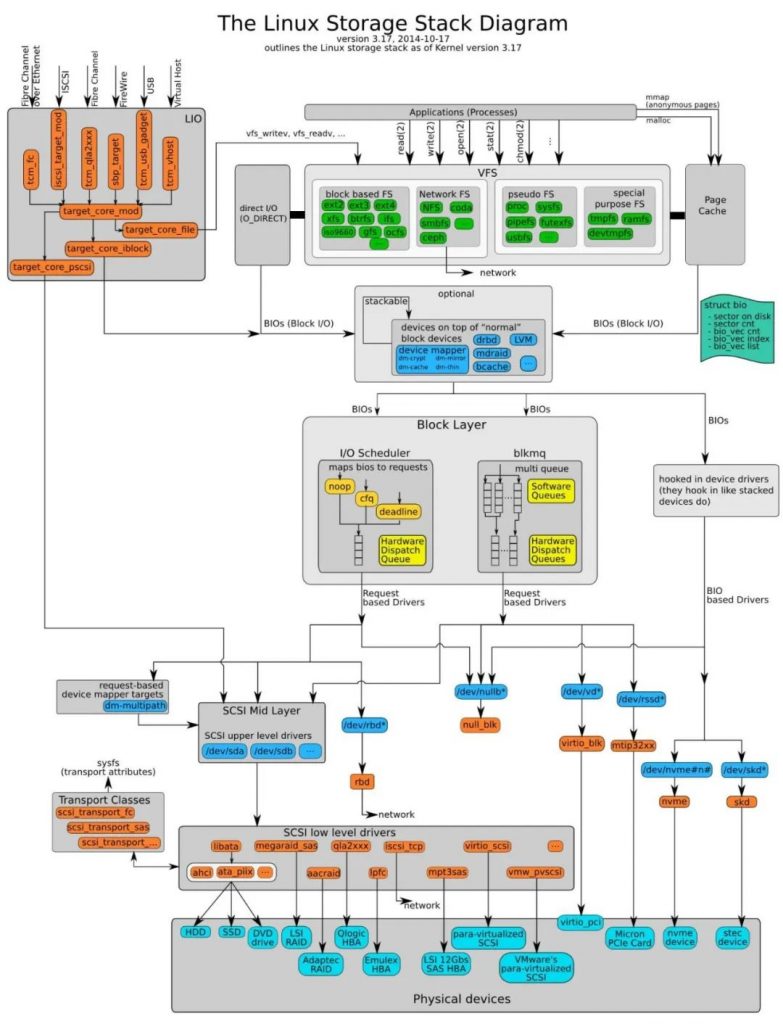
IO調(diào)度器在內(nèi)核棧中所處位置如下:
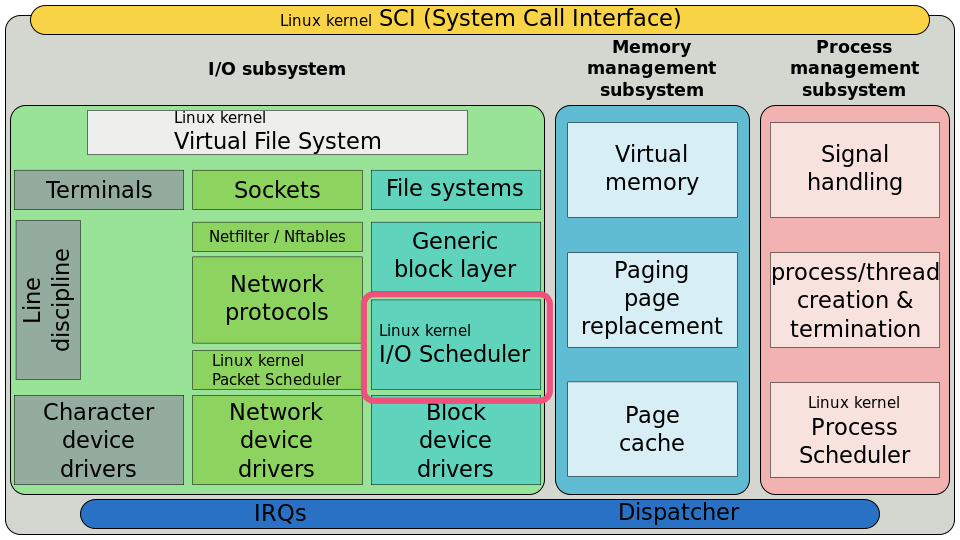
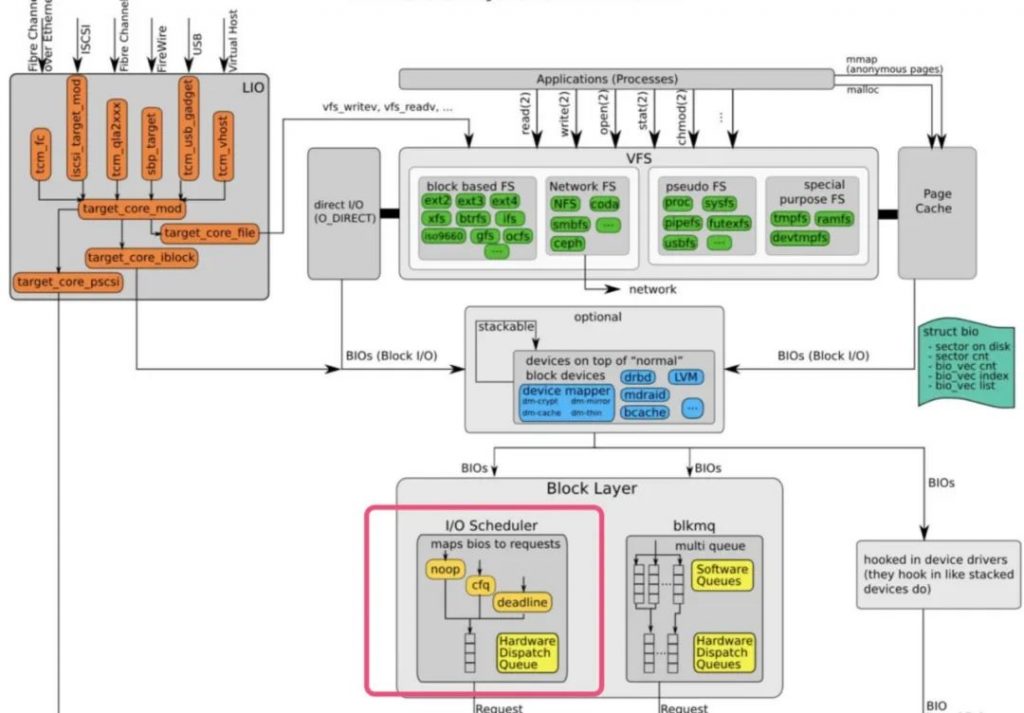
塊設(shè)備最悲劇的地方就是磁盤轉(zhuǎn)動,這個過程會很耗時間。每個塊設(shè)備或者塊設(shè)備的分區(qū),都對應(yīng)有自身的請求隊列(request_queue),而每個請求隊列都可以選擇一個I/O調(diào)度器來協(xié)調(diào)所遞交的request。
I/O調(diào)度器的基本目的是將請求按照它們對應(yīng)在塊設(shè)備上的扇區(qū)號進行排列,以減少磁頭的移動,提高效率。每個設(shè)備的請求隊列里的請求將按順序被響應(yīng)。
實際上,除了這個隊列,每個調(diào)度器自身都維護有不同數(shù)量的隊列,用來對遞交上來的request進行處理,而排在隊列最前面的request將適時被移動到請求隊列中等待響應(yīng)。

IO scheduler 的作用主要是為了減少磁盤轉(zhuǎn)動的需求。主要通過2種方式實現(xiàn):
-
合并 -
?排序
每個設(shè)備都會自己對應(yīng)請求隊列,所有的請求在被處理之前都會在請求隊列上。在新來一個請求的時候如果發(fā)現(xiàn)這個請求和前面的某個請求請求的位置是相鄰的,那么就可以合并為一個請求。
如果不能找到合并的,就會按照磁盤的轉(zhuǎn)動方向進行排序。通常IO scheduler 的作用就是為了在進行合并和排序的同時,也不會太影響單個請求的處理時間。
1、NOOP
FIFO
-
noop是什么? noop是一種輸入輸出調(diào)度算法 . NOOP, No Operation. 什么都不做,請求來一個處理一個。這種方式事實起來簡單,也更有效。問題就是disk seek 太多,對于傳統(tǒng)磁盤,這是不能接受的。但對于SSD 磁盤就可以,因為SSD 磁盤不需要轉(zhuǎn)動。 -
noop的別稱 又稱為電梯調(diào)度算法. -
noop原理是怎樣的?
將輸入輸出請求放到一個FIFO隊列中,然后按次序執(zhí)行隊列中的輸入輸出請求:當(dāng)來一個新請求時:
-
如果能合并就合并 -
如果不能合并,就會嘗試排序。如果隊列上的請求都已經(jīng)很老了,這個新的請求就不能插隊,只能放到最后面。否則就插到合適的位置 -
如果既不能合并,又沒有合適的位置插入,就放到請求隊列的最后。 -
適用場景 4.1 在不希望修改輸入輸出請求先后順序的場景下;
4.2 在輸入輸出之下具有更加智能調(diào)度算法的設(shè)備,如NAS存儲設(shè)備;
4.3 上層應(yīng)用程序已經(jīng)精心優(yōu)化過的輸入輸出請求;
4.4 非旋轉(zhuǎn)磁頭式的磁盤設(shè)備,如SSD磁盤
2、CFQ(Completely Fair Queuing, 完全公平排隊)
CFQ(Completely Fair Queuing)算法,顧名思義,絕對公平算法。它試圖為競爭塊設(shè)備使用權(quán)的所有進程分配一個請求隊列和一個時間片,在調(diào)度器分配給進程的時間片內(nèi),進程可以將其讀寫請求發(fā)送給底層塊設(shè)備,當(dāng)進程的時間片消耗完,進程的請求隊列將被掛起,等待調(diào)度。
每個進程的時間片和每個進程的隊列長度取決于進程的IO優(yōu)先級,每個進程都會有一個IO優(yōu)先級,CFQ調(diào)度器將會將其作為考慮的因素之一,來確定該進程的請求隊列何時可以獲取塊設(shè)備的使用權(quán)。
IO優(yōu)先級從高到低可以分為三大類:
RT(real time)
BE(best try)
IDLE(idle)其中RT和BE又可以再劃分為8個子優(yōu)先級。可以通過ionice 去查看和修改。優(yōu)先級越高,被處理得越早,用于這個進程的時間片也越多,一次處理的請求數(shù)也會越多。
實際上,我們已經(jīng)知道CFQ調(diào)度器的公平是針對于進程而言的,而只有同步請求(read或syn write)才是針對進程而存在的,他們會放入進程自身的請求隊列,而所有同優(yōu)先級的異步請求,無論來自于哪個進程,都會被放入公共的隊列,異步請求的隊列總共有8(RT)+8(BE)+1(IDLE)=17個。
從Linux 2.6.18起,CFQ作為默認的IO調(diào)度算法。對于通用的服務(wù)器來說,CFQ是較好的選擇。具體使用哪種調(diào)度算法還是要根據(jù)具體的業(yè)務(wù)場景去做足benchmark來選擇,不能僅靠別人的文字來決定。
3、DEADLINE
DEADLINE在CFQ的基礎(chǔ)上,解決了IO請求餓死的極端情況。
除了CFQ本身具有的IO排序隊列之外,DEADLINE額外分別為讀IO和寫IO提供了FIFO隊列。
讀FIFO隊列的最大等待時間為500ms,寫FIFO隊列的最大等待時間為5s(當(dāng)然這些參數(shù)都是可以手動設(shè)置的)。
FIFO隊列內(nèi)的IO請求優(yōu)先級要比CFQ隊列中的高,而讀FIFO隊列的優(yōu)先級又比寫FIFO隊列的優(yōu)先級高。優(yōu)先級可以表示如下:
FIFO(Read) > FIFO(Write) > CFQ
deadline 算法保證對于既定的 IO 請求以最小的延遲時間,從這一點理解,對于 DSS 應(yīng)用應(yīng)該會是很適合的。
deadline 實際上是對Elevator 的一種改進:
1. 避免有些請求太長時間不能被處理。
2. 區(qū)分對待讀操作和寫操作。
deadline IO 維護3個隊列。第一個隊列和Elevator 一樣, 盡量按照物理位置排序。第二個隊列和第三個隊列都是按照時間排序,不同的是一個是讀操作一個是寫操作。
deadline IO 之所以區(qū)分讀和寫是因為設(shè)計者認為如果應(yīng)用程序發(fā)了一個讀請求,一般就會阻塞到那里,一直等到的結(jié)果返回。而寫請求則不是通常是應(yīng)用請求寫到內(nèi)存即可,由后臺進程再寫回磁盤。應(yīng)用程序一般不等寫完成就繼續(xù)往下走。所以讀請求應(yīng)該比寫請求有更高的優(yōu)先級。
在這種設(shè)計下,每個新增請求都會先放到第一個隊列,算法和Elevator的方式一樣,同時也會增加到讀或者寫隊列的尾端。這樣首先處理一些第一隊列的請求,同時檢測第二/三隊列前幾個請求是否等了太長時間,如果已經(jīng)超過一個閥值,就會去處理一下。這個閥值對于讀請求時 5ms, 對于寫請求時5s.
個人認為對于記錄數(shù)據(jù)庫變更日志的分區(qū),例如oracle 的online log, mysql 的binlog 等等,最好不要使用這種分區(qū)。因為這類寫請求通常是調(diào)用fsync 的。如果寫完不成,也會很影響應(yīng)用性能的。
4、ANTICIPATORY
CFQ和DEADLINE考慮的焦點在于滿足零散IO請求上。對于連續(xù)的IO請求,比如順序讀,并沒有做優(yōu)化。
為了滿足隨機IO和順序IO混合的場景,Linux還支持ANTICIPATORY調(diào)度算法。ANTICIPATORY的在DEADLINE的基礎(chǔ)上,為每個讀IO都設(shè)置了6ms的等待時間窗口。如果在這6ms內(nèi)OS收到了相鄰位置的讀IO請求,就可以立即滿足。
小結(jié)
IO調(diào)度器算法的選擇,既取決于硬件特征,也取決于應(yīng)用場景。
在傳統(tǒng)的SAS盤上,CFQ、DEADLINE、ANTICIPATORY都是不錯的選擇;對于專屬的數(shù)據(jù)庫服務(wù)器,DEADLINE的吞吐量和響應(yīng)時間都表現(xiàn)良好。
然而在新興的固態(tài)硬盤比如SSD、Fusion IO上,最簡單的NOOP反而可能是最好的算法,因為其他三個算法的優(yōu)化是基于縮短尋道時間的,而固態(tài)硬盤沒有所謂的尋道時間且IO響應(yīng)時間非常短。
鏈接:blog.csdn.net/universsky2015/article/details/105531343
(版權(quán)歸原作者所有,侵刪)
-