

如何在 60秒內(nèi)優(yōu)化提升 Linux 性能?只有 2% 的人知道
當(dāng)你發(fā)現(xiàn) Linux 服務(wù)器上的系統(tǒng)性能問題,在最開始的 1 分鐘時間里,你會查看哪些系統(tǒng)指標(biāo)呢?
Netflix 在 AWS 上有著大規(guī)模的 EC2 集群,以及各種各樣的性能分析和監(jiān)控工具。比如我們使用 Atlas 來監(jiān)控整個平臺,用 Vector 實時分析 EC2 實例的性能。這些工具已經(jīng)能夠幫助我們解決大部分的問題,但是有時候我們還是要登錄進(jìn)機(jī)器內(nèi)部,用一些標(biāo)準(zhǔn)的 Linux 性能分析工具來定位問題。
在這篇文章里,Netflix 性能工程團(tuán)隊會介紹一些我們使用的標(biāo)準(zhǔn)的 Linux 命令行工具,在發(fā)現(xiàn)問題的前 60 秒內(nèi)去分析和定位問題。


有些命令行依賴于 sysstat 包。通過這些命令行的使用,你可以熟悉一下分析系統(tǒng)性能問題時常用的一套方法或者流程:USE 。這個方法主要從資源使用率(Utilization)、資源飽和度(Satuation)、錯誤(Error),這三個方面對所有的資源進(jìn)行分析(CPU,內(nèi)存,磁盤等等)。在這個分析的過程中,我們也要時刻注意我們已經(jīng)排除過的資源問題,以便縮小我們定位的范圍,給下一步的定位提供更明確的方向。
下面的章節(jié)對每個命令行做了一個說明,并且使用了我們在生產(chǎn)環(huán)境的數(shù)據(jù)作為例子。對這些命令行更詳細(xì)的描述,請查看相應(yīng)的幫助文檔。
1、uptime

這個命令能很快地檢查系統(tǒng)平均負(fù)載,你可以認(rèn)為這個負(fù)載的值顯示的是有多少任務(wù)在等待運(yùn)行。在 Linux 系統(tǒng)里,這包含了想要或者正在使用 CPU 的任務(wù),以及在 io 上被阻塞的任務(wù)。這個命令能使我們對系統(tǒng)的全局狀態(tài)有一個大致的了解,但是我們依然需要使用其它工具獲取更多的信息。
這三個值是系統(tǒng)計算的 1 分鐘、5 分鐘、15 分鐘的指數(shù)加權(quán)的動態(tài)平均值,可以簡單地認(rèn)為就是這個時間段內(nèi)的平均值。根據(jù)這三個值,我們可以了解系統(tǒng)負(fù)載隨時間的變化。比如,假設(shè)現(xiàn)在系統(tǒng)出了問題,你去查看這三個值,發(fā)現(xiàn) 1 分鐘的負(fù)載值比 15 分鐘的負(fù)載值要小很多,那么你很有可能已經(jīng)錯過了系統(tǒng)出問題的時間點。
在上面這個例子里面,負(fù)載的平均值顯示 1 分鐘為 30,比 15 分鐘的 19 相比增長較多。有很多原因會導(dǎo)致負(fù)載的增加,也許是 CPU 不夠用了;vmstat 或者 mpstat 可以進(jìn)一步確認(rèn)問題在哪里。
2、dmesg | tail

這個命令顯示了最新的幾條系統(tǒng)日志。這里我們主要找一下有沒有一些系統(tǒng)錯誤會導(dǎo)致性能的問題。上面的例子包含了 oom-killer 以及 TCP 丟包。
不要略過這一步!dmesg 永遠(yuǎn)值得看一看。
3、?vmstat 1
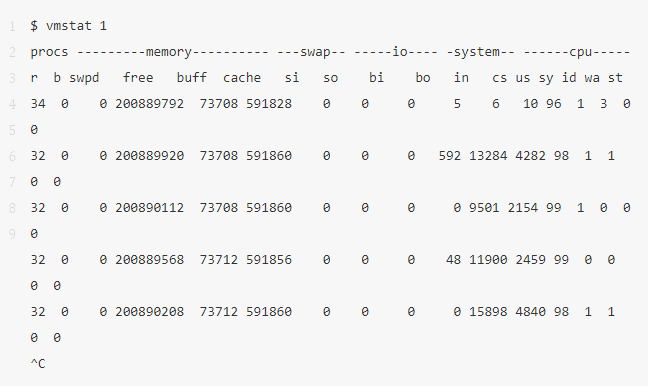
vmstat 展示了虛擬內(nèi)存、CPU 的一些情況。上面這個例子里命令行的 1 表示每隔 1 秒鐘顯示一次。在這個版本的 vmstat 里,第一行表示了這一次啟動以來的各項指標(biāo),我們可以暫時忽略掉第一行。
需要查看的指標(biāo):
-
r:處在 runnable 狀態(tài)的任務(wù),包括正在運(yùn)行的任務(wù)和等待運(yùn)行的任務(wù)。這個值比平均負(fù)載能更好地看出 CPU 是否飽和。這個值不包含等待 io 相關(guān)的任務(wù)。當(dāng) r 的值比當(dāng)前 CPU 個數(shù)要大的時候,系統(tǒng)就處于飽和狀態(tài)了。 -
free:以 KB 計算的空閑內(nèi)存大小。 -
si,so:換入換出的內(nèi)存頁。如果這兩個值非零,表示內(nèi)存不夠了。 -
us,sy,id,wa,st:CPU 時間的各項指標(biāo)(對所有 CPU 取均值),分別表示:用戶態(tài)時間,內(nèi)核態(tài)時間,空閑時間,等待 io,偷取時間(在虛擬化環(huán)境下系統(tǒng)在其它租戶上的開銷)
把用戶態(tài) CPU 時間(us)和內(nèi)核態(tài) CPU 時間(sy)加起來,我們可以進(jìn)一步確認(rèn) CPU 是否繁忙。等待 IO 的時間 (wa)高的話,表示磁盤是瓶頸;注意,這個也被包含在空閑時間里面(id), CPU 這個時候也是空閑的,任務(wù)此時阻塞在磁盤 IO 上了。你可以把等待 IO 的時間(wa)看做另一種形式的 CPU 空閑,它可以告訴你 CPU 為什么是空閑的。
系統(tǒng)處理 IO 的時候,肯定是會消耗內(nèi)核態(tài)時間(sy)的。如果內(nèi)核態(tài)時間較多的話,比如超過 20%,我們需要進(jìn)一步分析,也許內(nèi)核對 IO 的處理效率不高。
在上面這個例子里,CPU 時間大部分都消耗在了用戶態(tài),表明主要是應(yīng)用層的代碼在使用 CPU。CPU 利用率 (us + sy)也超過了 90%,這不一定是一個問題;我們可以通過 r 和 CPU 個數(shù)確定 CPU 的飽和度。
4、mpstat -P ALL 1
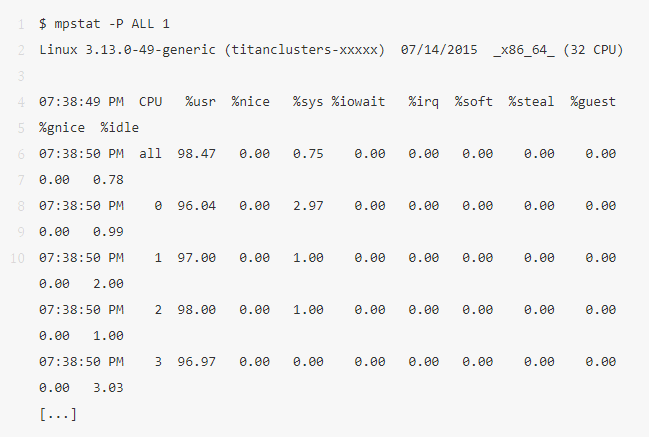
這個命令把每個 CPU 的時間都打印出來,可以看看 CPU 對任務(wù)的處理是否均勻。比如,如果某一單個 CPU 使用率很高的話,說明這是一個單線程應(yīng)用。
5、pidstat 1
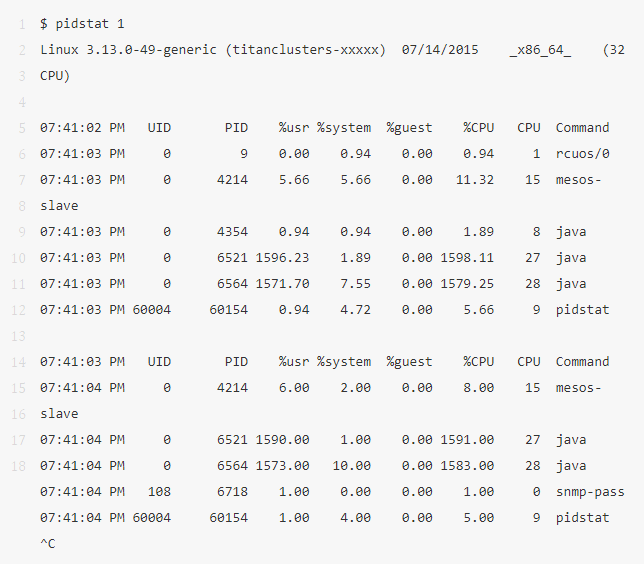
pidstat 和 top 很像,不同的是它可以每隔一個間隔打印一次,而不是像 top 那樣每次都清屏。這個命令可以方便地查看進(jìn)程可能存在的行為模式,你也可以直接 copy past,可以方便地記錄隨著時間的變化,各個進(jìn)程運(yùn)行狀況的變化。
上面的例子說明有 2 個 Java 進(jìn)程消耗了大量 CPU。這里的 %CPU 表明的是對所有 CPU 的值,比如 1591% 標(biāo)識這個 Java 進(jìn)程幾乎消耗了 16 個 CPU。
6、iostat -xz 1

iostat 是理解塊設(shè)備(磁盤)的當(dāng)前負(fù)載和性能的重要工具。幾個指標(biāo)的含義:
-
r/s,w/s,rkB/s,wkB/s:系統(tǒng)發(fā)往設(shè)備的每秒的讀次數(shù)、每秒寫次數(shù)、每秒讀的數(shù)據(jù)量、每秒寫的數(shù)據(jù)量。這幾個指標(biāo)反映的是系統(tǒng)的工作負(fù)載。系統(tǒng)的性能問題很有可能就是負(fù)載太大。 -
await:系統(tǒng)發(fā)往 IO 設(shè)備的請求的平均響應(yīng)時間。這包括請求排隊的時間,以及請求處理的時間。超過經(jīng)驗值的平均響應(yīng)時間表明設(shè)備處于飽和狀態(tài),或者設(shè)備有問題。 -
avgqu-sz:設(shè)備請求隊列的平均長度。隊列長度大于 1 表示設(shè)備處于飽和狀態(tài)。 -
%util:設(shè)備利用率。設(shè)備繁忙的程度,表示每一秒之內(nèi),設(shè)備處理 IO 的時間占比。大于 60% 的利用率通常會導(dǎo)致性能問題(可以通過 await 看到),但是每種設(shè)備也會有有所不同。接近 100% 的利用率表明磁盤處于飽和狀態(tài)。
如果這個塊設(shè)備是一個邏輯塊設(shè)備,這個邏輯快設(shè)備后面有很多物理的磁盤的話,100% 利用率只能表明有些 IO 的處理時間達(dá)到了 100%;后端的物理磁盤可能遠(yuǎn)遠(yuǎn)沒有達(dá)到飽和狀態(tài),可以處理更多的負(fù)載。
還有一點需要注意的是,較差的磁盤 IO 性能并不一定意味著應(yīng)用程序會有問題。應(yīng)用程序可以有許多方法執(zhí)行異步 IO,而不會阻塞在 IO 上面;應(yīng)用程序也可以使用諸如預(yù)讀取,寫緩沖等技術(shù)降低 IO 延遲對自身的影響。
7、free -m

右邊的兩列顯式:
-
buffers:用于塊設(shè)備 I/O 的緩沖區(qū)緩存。 -
cached:用于文件系統(tǒng)的頁面緩存。
我們只是想要檢查這些不接近零的大小,其可能會導(dǎo)致更高磁盤 I/O(使用 iostat 確認(rèn)),和更糟糕的性能。上面的例子看起來還不錯,每一列均有很多 M 個大小。
比起第一行,-/+ buffers/cache 提供的內(nèi)存使用量會更加準(zhǔn)確些。Linux 會把暫時用不上的內(nèi)存用作緩存,一旦應(yīng)用需要的時候就立刻重新分配給它。所以部分被用作緩存的內(nèi)存其實也算是空閑的內(nèi)存。為了解釋這一點, 甚至有人專門建了個網(wǎng)站:http://www.linuxatemyram.com/。
如果使用 ZFS 的話,可能會有點困惑。ZFS 有自己的文件系統(tǒng)緩存,在 free -m 里面看不到;系統(tǒng)看起來空閑內(nèi)存不多了,但是有可能 ZFS 有很多的緩存可用。
8、sar -n DEV 1
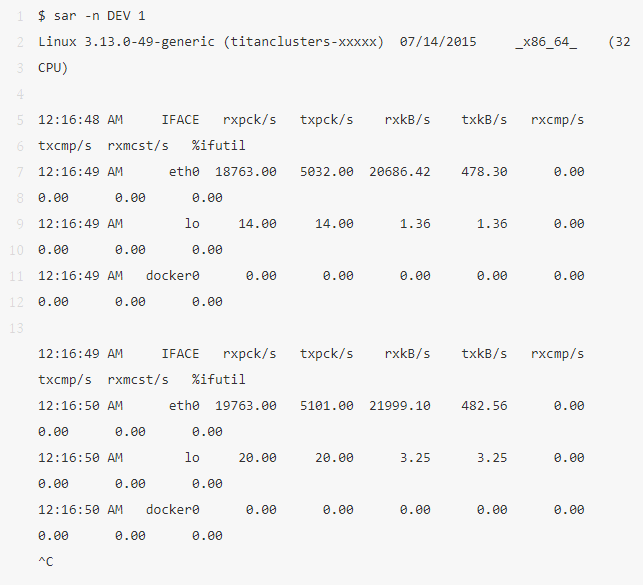
這個工具可以查看網(wǎng)絡(luò)接口的吞吐量:rxkB/s 和 txkB/s 可以測量負(fù)載,也可以看是否達(dá)到網(wǎng)絡(luò)流量限制了。在上面的例子里,eth0 的吞吐量達(dá)到了大約 22 Mbytes/s,差不多 176 Mbits/sec ,比 1 Gbit/sec 還要少很多。
這個例子里也有 %ifutil 標(biāo)識設(shè)備利用率,我們也用 Brenan 的 nicstat tool 測量。和 nicstat 一樣,這個設(shè)備利用率很難測量正確,上面的例子里好像這個值還有點問題。
9、sar -n TCP,ETCP 1
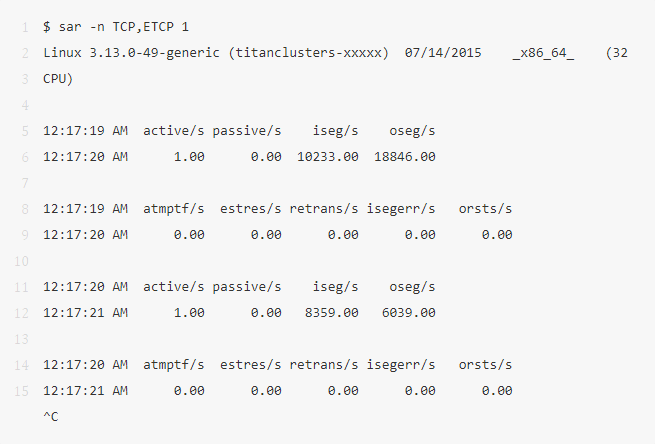
這是對 TCP 重要指標(biāo)的一些概括,包括:
-
active/s:每秒鐘本地主動開啟的 TCP 連接,也就是本地程序使用 connect() 系統(tǒng)調(diào)用 -
passive/s:每秒鐘從源端發(fā)起的 TCP 連接,也就是本地程序使用 accept() 所接受的連接 -
retrans/s:每秒鐘的 TCP 重傳次數(shù) -
atctive 和 passive 的數(shù)目通常可以用來衡量服務(wù)器的負(fù)載:接受連接的個數(shù)(passive),下游連接的個數(shù)(active)。可以簡單認(rèn)為 active 為出主機(jī)的連接,passive 為入主機(jī)的連接;但這個不是很嚴(yán)格的說法,比如 loalhost 和 localhost 之間的連接。
重傳表示網(wǎng)絡(luò)或者服務(wù)器的問題。也許是網(wǎng)絡(luò)不穩(wěn)定了,也許是服務(wù)器負(fù)載過重開始丟包了。上面這個例子表示每秒只有 1 個新連接建立。
10、top
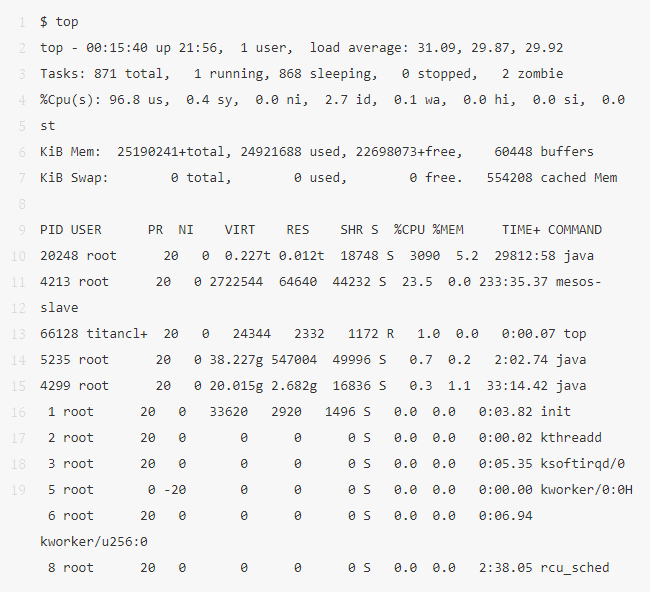
top 命令涵蓋了我們前面講述的許多指標(biāo)。我們可以用它來看和我們之前查看的結(jié)果有沒有很大的不同,如果有的話,那表示系統(tǒng)的負(fù)載在變化。
top 的缺點就是你很難找到這些指標(biāo)隨著時間的一些行為模式,在這種情況下,vmstat 或者 pidstat 這種可以提供滾動輸出的命令是更好的方式。如果你不以足夠快的速度暫停輸出(Ctrl-S 暫停,Ctrl-Q 繼續(xù)),一些間歇性問題的線索也可能由于被清屏而丟失。
來自:知乎,作者:胡明
鏈接:https://zhuanlan.zhihu.com/p/39893236