

云原生時代需要什么樣的存儲系統(tǒng)?


而應(yīng)用系統(tǒng)的敏捷性、擴展性、可靠性、高可用等,則由基礎(chǔ)設(shè)施軟件和運維團隊共同承擔(dān)。一方面,運維團隊需要利用基礎(chǔ)設(shè)施軟件,快速響應(yīng)業(yè)務(wù)系統(tǒng)提出的部署、擴容、遷移等需求,另一方面,也要時刻保持業(yè)務(wù)系統(tǒng)和基礎(chǔ)設(shè)施軟件的穩(wěn)定運行。這為基礎(chǔ)設(shè)施軟件和運維團隊都帶來了更大的挑戰(zhàn)。
如何正確的為基礎(chǔ)架構(gòu)軟件進行設(shè)計和選型,就成為了運維主管們最具挑戰(zhàn)的任務(wù)之一。
存儲系統(tǒng)一直以來都是基礎(chǔ)設(shè)施軟件中的核心之一。無論業(yè)務(wù)采用什么樣的運行環(huán)境和架構(gòu),都離不開存儲系統(tǒng)的支撐。
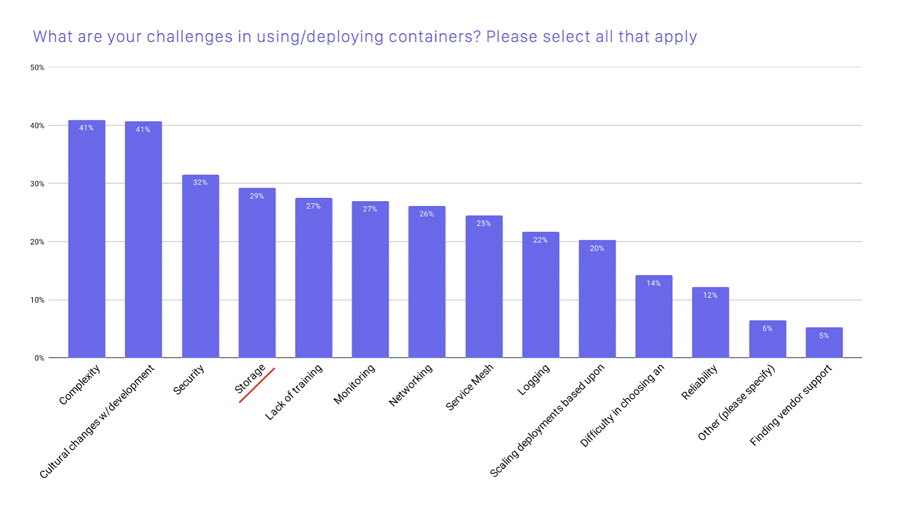
圖 1. 使用/部署容器的主要挑戰(zhàn)(圖片來源于 CNCF 報告)
從 CNCF 的調(diào)查可以看出,目前存儲系統(tǒng)依然是云原生場景使用和部署中面臨的最主要障礙之一。接下來我們來介紹一下云原生場景下不同存儲方案的優(yōu)劣點。
本地磁盤
本地磁盤是最容易想到的方式,也是從物理機時代就一直在使用的方式。
在服務(wù)器的硬盤槽上插上硬盤,并利用 HBA 卡或軟件的方式制作 RAID,劃分邏輯卷,格式化成某種文件系統(tǒng)后,掛載到容器中。
由于磁盤和應(yīng)用系統(tǒng)中間的 IO 路徑最短,本地磁盤可以提供最佳的性能。同時 RAID 提供了一定程度的可靠性的保證,可以避免因單個磁盤故障而導(dǎo)致的數(shù)據(jù)丟失。因此,目前有大量用戶采用這種方式為有狀態(tài)的應(yīng)用提供存儲服務(wù)。
然而本地磁盤方案也存在著巨大的缺陷。
首先,本地磁盤無法提供節(jié)點級別的高可用,當(dāng)物理節(jié)點發(fā)生故障時,由于數(shù)據(jù)都存儲在故障節(jié)點上,所以應(yīng)用無法被恢復(fù)到其他節(jié)點。如果業(yè)務(wù)系統(tǒng)有節(jié)點級高可用的要求,則必須由業(yè)務(wù)系統(tǒng)自己實現(xiàn)數(shù)據(jù)層面的高可用,這極大的增加了業(yè)務(wù)系統(tǒng)的復(fù)雜度。
其次,本地磁盤在敏捷性上也無法滿足業(yè)務(wù)需求,業(yè)務(wù)使用的存儲空間受限于本地磁盤的大小,如果達到磁盤空間的上限后難以擴容。部署 RAID 也是相當(dāng)耗時的操作,難以實現(xiàn)在短時間內(nèi)部署大量的應(yīng)用系統(tǒng)。
此外,該方案無論是部署還是故障后的修復(fù),都需要大量人力的參與,這使得本地存儲方案的運維成本非常高。同時由于節(jié)點間的存儲空間無法共享,也很容易造成存儲空間的浪費。
總的來說,本地磁盤的方案只適合在業(yè)務(wù)容器化的初期階段進行小規(guī)模試用,難以在大規(guī)模場景下被廣泛使用。
集中式存儲
集中式存儲提供了可遠程訪問共享存儲的能力。和本地磁盤的方案相比,集中式存儲解決了應(yīng)用系統(tǒng)高可用的問題,當(dāng)業(yè)務(wù)系統(tǒng)所在的服務(wù)器發(fā)生故障時,由于數(shù)據(jù)不再存儲在服務(wù)器本地,而是存儲在遠端的共享存儲中,所以可以在其他節(jié)點上把應(yīng)用拉起來,以實現(xiàn)業(yè)務(wù)系統(tǒng)的高可用。此外,由于數(shù)據(jù)集中存儲,也一定程度解決了本地存儲對磁盤空間浪費的問題。
很多商用存儲都采用集中式存儲架構(gòu),除了基本的數(shù)據(jù)讀寫能力外,還提供了很多高級功能,包括快照、克隆、容災(zāi)等等,進一步提升業(yè)務(wù)數(shù)據(jù)的可靠性。
然而集中式存儲的架構(gòu)決定了它不適合云原生的場景。
集中式存儲采用存儲控制器加盤柜的形式,控制器負責(zé)提供性能和存儲功能,盤柜提供可擴展的存儲容量。
盡管集中式存儲可以為單個業(yè)務(wù)系統(tǒng)提供較高的性能保證,但是當(dāng)面臨大量業(yè)務(wù)并發(fā)訪問時,存儲控制器則成為了性能瓶頸。如果想要滿足大量業(yè)務(wù)對性能需求,需要采用多套集中式存儲系統(tǒng),存儲系統(tǒng)的管理成本也會急劇上升。
此外,由于集中式存儲誕生在幾十年前,在設(shè)計上就沒有把敏捷性和運維便利性考慮進去,無法應(yīng)對短時間內(nèi)大量 Volume 的并發(fā)創(chuàng)建和銷毀操作,無法滿足業(yè)務(wù)系統(tǒng)對敏捷性的要求。
分布式存儲
分布式存儲的誕生就是為了解決集中式存儲無法解決的問題。
分布式存儲天然具有橫向擴展能力,在性能和高可用方面遠優(yōu)于集中式存儲,非常適合應(yīng)對大規(guī)模虛擬化場景。與此同時,分布式存儲也逐漸具備了企業(yè)級存儲的能力,包括快照、克隆等等。
不過,盡管分布式存儲在架構(gòu)上具備眾多優(yōu)點,但在實現(xiàn)難度上具備非常大的挑戰(zhàn),并不是所有的分布式存儲都能夠充分發(fā)揮出分布式架構(gòu)的優(yōu)勢。在實際的使用過程中,大部分分布式存儲的性能和穩(wěn)定性都難以達到生產(chǎn)級別的標(biāo)準,這使得很多運維團隊不敢輕易地部署分布式存儲產(chǎn)品。
總結(jié)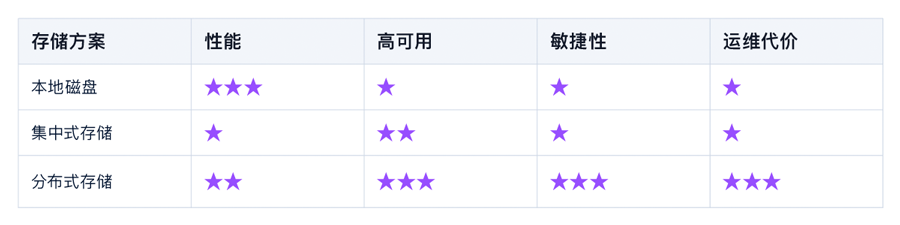
圖 2. 不同存儲方案對比
目前越來越多的數(shù)據(jù)庫也在采用云原生架構(gòu),數(shù)據(jù)庫迎來了云原生時代。云原生數(shù)據(jù)庫將實例運行在容器中,具備了快速部署,快速擴容的能力。同時,云原生數(shù)據(jù)庫也采用了“存算分離”的架構(gòu),將數(shù)據(jù)庫計算邏輯和存儲邏輯進一步進行分離,存儲能力交給更專業(yè)的存儲系統(tǒng)完成,數(shù)據(jù)庫只專注在數(shù)據(jù)庫的業(yè)務(wù)邏輯處理。
在某種程度上講,我們可以說云原生時代的有狀態(tài)應(yīng)用,大部分指的就是“云原生數(shù)據(jù)庫”。接下來,我們分兩種典型的數(shù)據(jù)庫類型進行介紹。
常見的 OLTP 數(shù)據(jù)庫有 MySQL,PostgreSQL 等,通常承載的都是核心交易類業(yè)務(wù),對存儲系統(tǒng)的數(shù)據(jù)可靠性、性能要求極高。交易類業(yè)務(wù)本身對延遲非常敏感,所以存儲系統(tǒng)的性能直接決定了 OLTP 系統(tǒng)能提供的能力。存儲系統(tǒng)的帶寬越高、延遲越低,OLTP 能提供的 TPS 越高。
每一套業(yè)務(wù)系統(tǒng)通常都會有 N 套獨立的 OLTP 數(shù)據(jù)庫作為業(yè)務(wù)支撐。由于業(yè)務(wù)系統(tǒng)會頻繁的進行部署以及擴容,所以支撐 OLTP 的存儲系統(tǒng)必須具備很高的敏捷性,可以快速提供數(shù)據(jù)庫對存儲空間的需求,同時也要方便的進行擴容等操作。
大部分 OLTP 數(shù)據(jù)庫采用塊存儲系統(tǒng)作為數(shù)據(jù)存儲系統(tǒng),因為塊存儲通常可以提供最佳的性能。此外,商業(yè)塊存儲還提供了快照、克隆等技術(shù),可以很好地保證數(shù)據(jù)庫業(yè)務(wù)的延續(xù)性。
分析型數(shù)據(jù)庫(OLAP)
OLAP 數(shù)據(jù)庫主要用在數(shù)據(jù)分析場景,對存儲系統(tǒng)的可靠性以及延遲的要求都不像 OLTP 數(shù)據(jù)庫那么高,且因為數(shù)據(jù)量巨大,所以對存儲成本也非常敏感。
為了支撐 OLAP 對存儲成本的要求,存儲系統(tǒng)通常采用 EC 技術(shù),以降低數(shù)據(jù)存儲的成本。而考慮到文件接口難以支撐百億級別的文件數(shù)量,所以 OLAP 使用的存儲系統(tǒng)通常采用對象接口,例如 S3 接口。
OLAP 系統(tǒng)對敏捷性沒有特殊的需求,一旦部署好后,最常見的運維操作是擴容,并不會對數(shù)據(jù)庫頻繁的進行重新部署和銷毀操作。
基于以上因素,分析型數(shù)據(jù)庫通常采用支持 EC 的對象存儲作為數(shù)據(jù)存儲服務(wù),通過 S3 接口訪問數(shù)據(jù)。
總結(jié)
?圖 3. OLTP 和 OLAP 對存儲系統(tǒng)的不同要求
公有云和私有云在產(chǎn)品設(shè)計理念上完全不同,產(chǎn)品的使用方式、運維方式、服務(wù)質(zhì)量、產(chǎn)品參數(shù)也完全不同。即使同樣是公有云或者私有云,不同的服務(wù)提供商之間也存在著巨大差異。多云的環(huán)境,對企業(yè)的運維團隊提出了巨大的挑戰(zhàn)。
而云原生架構(gòu)的誕生,就是為了應(yīng)對多云的挑戰(zhàn):開發(fā)者在設(shè)計云原生應(yīng)用時,只需要關(guān)注應(yīng)用被如何創(chuàng)建和部署,無需關(guān)注在哪里運行。
然而盡管目前有相當(dāng)多的開發(fā)者采用了云原生的架構(gòu)設(shè)計應(yīng)用系統(tǒng),但是對于基礎(chǔ)架構(gòu)軟件來說,目前還是由不同的云廠商來提供。基礎(chǔ)架構(gòu)的運維人員需要為不同服務(wù)商提供的存儲系統(tǒng),準備不同的運維方式,這極大的增加了運維人員的負擔(dān)。
由此也誕生一個新的存儲系統(tǒng)類別:云原生存儲系統(tǒng)。云原生存儲系統(tǒng)可以良好的運行在各種不同服務(wù)商提供的公有云環(huán)境或私有云環(huán)境,并且為運維人員提供相同接口和運維方式。云原生存儲系統(tǒng)可以極大的降低運維團隊的負擔(dān)。
云原生存儲有什么不同
此處我們以 IOMesh 的架構(gòu)圖作為示例,說明云原生存儲的特點。
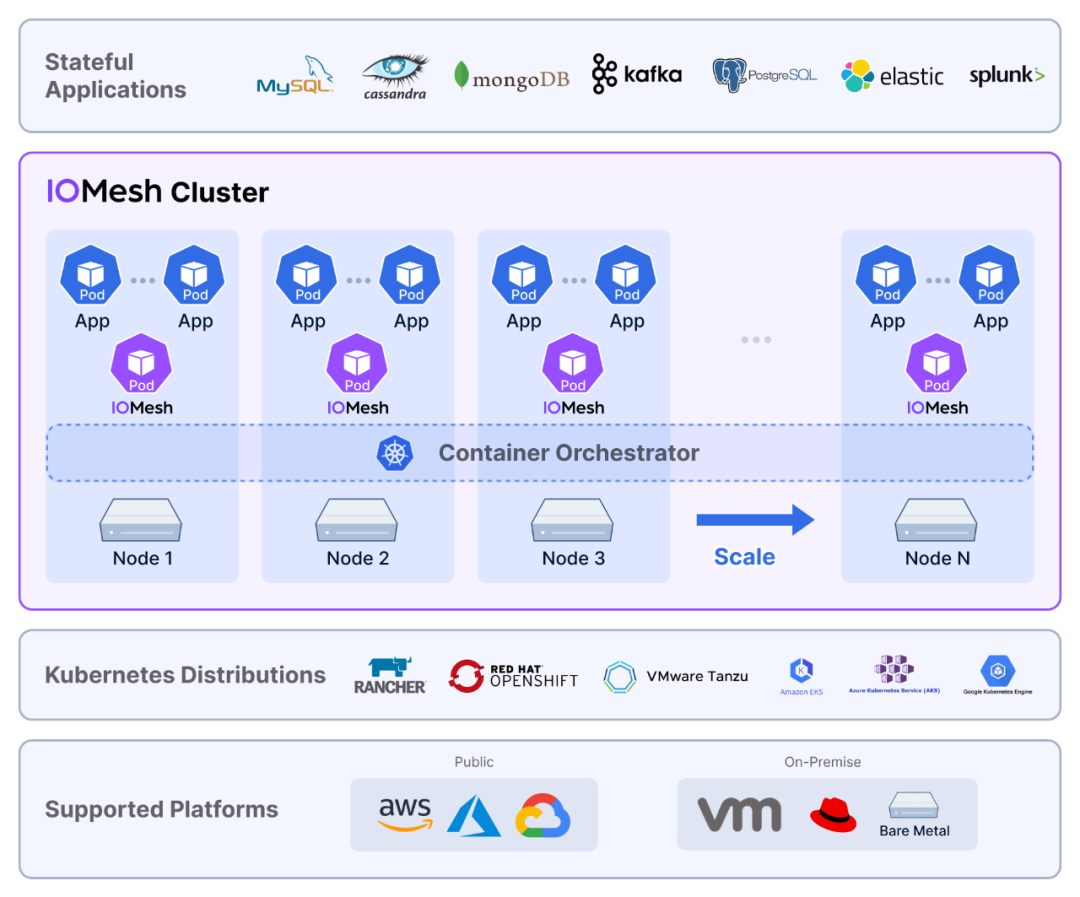
圖 4. IOMesh 產(chǎn)品架構(gòu)圖
云原生存儲不僅僅可以做到支持在公有云和私有云運行,而且提供了容器化部署、自動運維、聲明式接口等特征,讓用戶可以采用和運維其他云原生應(yīng)用一樣的方式對存儲系統(tǒng)進行部署、運維和管理。
除此之外,云原生存儲還需要能夠很好地和其他云原生基礎(chǔ)設(shè)施配合,例如云原生數(shù)據(jù)庫,使得云原生數(shù)據(jù)庫可以真正的在公有云和私有云都能夠得到一致的用戶體驗。
除此之外,“云原生”對存儲系統(tǒng)提出了更高的要求。
盡量減少環(huán)境依賴
云原生存儲系統(tǒng)應(yīng)盡量不對軟硬件環(huán)境存在任何依賴,例如對內(nèi)核的依賴,對特定的網(wǎng)絡(luò)設(shè)備和磁盤型號的依賴等等。只有盡量少的依賴,才能夠做到最大的適配性。
避免資源消耗過高
云原生存儲系統(tǒng)以容器的形式和業(yè)務(wù)系統(tǒng)混合部署在容器平臺上。如果存儲系統(tǒng)占用過多的計算資源(CPU、內(nèi)存),則會導(dǎo)致整體投入成本太高。
聲明式運維方式
存儲系統(tǒng)應(yīng)支持通過聲明式的接口進行運維管理,同時支持一定程度的自動化運維,包括在線擴容、升級等等。當(dāng)發(fā)生硬件故障時,存儲服務(wù)可以自動恢復(fù),以保證業(yè)務(wù)系統(tǒng)不受影響。
云原生生態(tài)
云原生存儲系統(tǒng)應(yīng)該可以很好地和云原生的運維生態(tài)系統(tǒng)結(jié)合,包括監(jiān)控、報警、日志處理等待。
我們準備了三個 Worker 節(jié)點作為運行應(yīng)用和云原生存儲的節(jié)點,每個節(jié)點配備了兩塊 SATA SSD,四塊 SATA HDD,以及萬兆網(wǎng)卡。
在測試中,我們采用最常見的 MySQL 數(shù)據(jù)庫作為有狀態(tài)應(yīng)用,并使用 sysbench-tpcc 模擬業(yè)務(wù)負載。下表提供了四個云原生存儲系統(tǒng)在 TPC-C MySQL 測試中的 TPS、QPS 以及 P95 延遲數(shù)據(jù)。
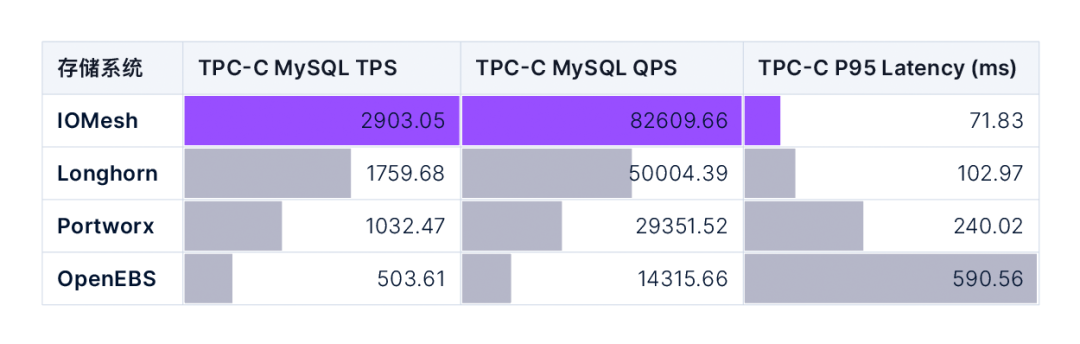
圖 5. TPC-C MySQL 綜合性能測試
下圖對比了四個云原生存儲系統(tǒng)的性能測試結(jié)果。圖中橫軸代表測試時間,縱軸分別代表:TPS、QPS、以及 P95 延遲的瞬時值。
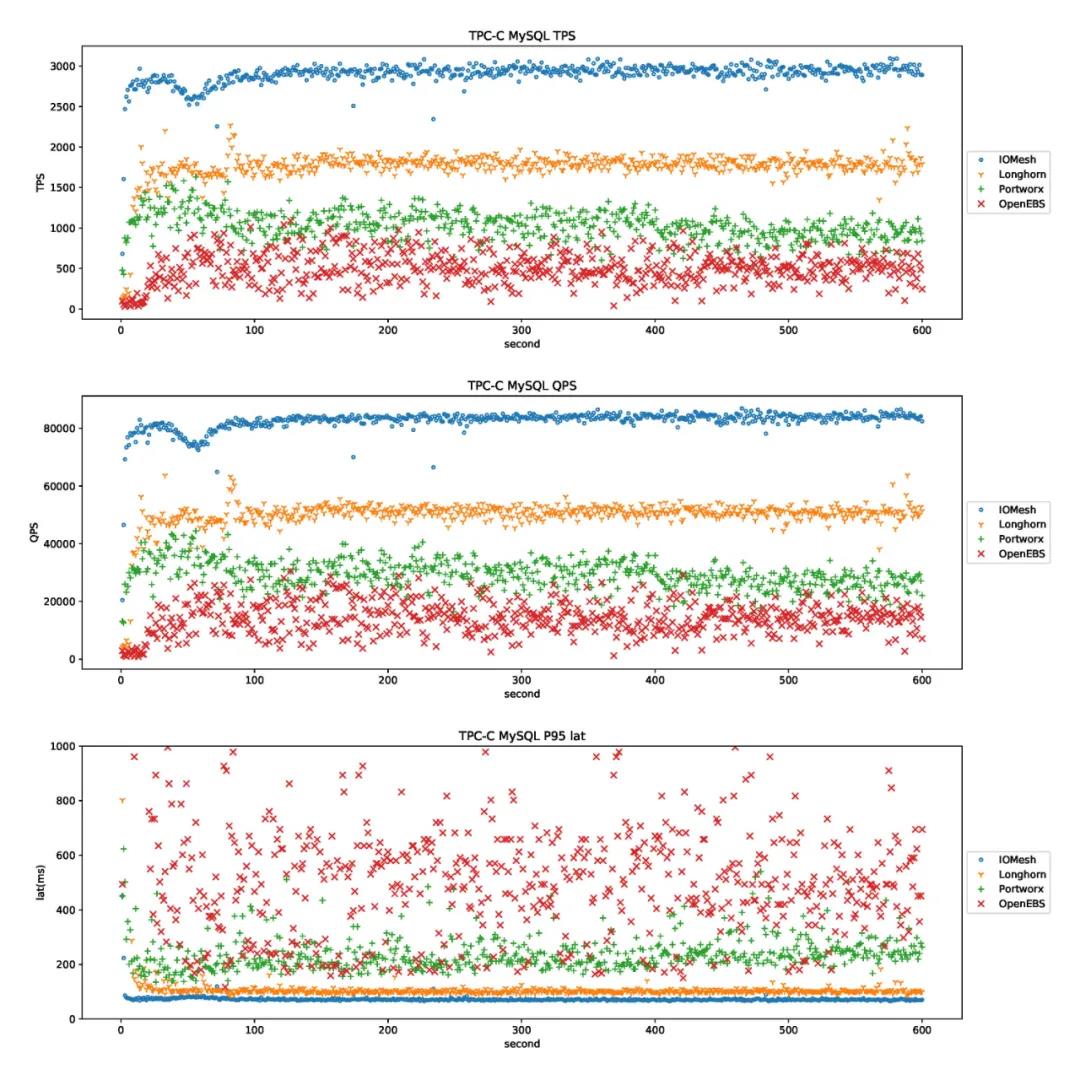
圖 6. TPC-C MySQL 性能穩(wěn)定性測試
從以上數(shù)據(jù)與對比可以明顯地看出, IOMesh 在絕對性能,以及性能的穩(wěn)定性上,都遙遙領(lǐng)先于其他的云原生存儲系統(tǒng),具備為核心生產(chǎn)系統(tǒng)提供存儲支撐的能力。
作者:張凱現(xiàn)任 SmartX 聯(lián)合創(chuàng)始人兼 CTO。張凱碩士畢業(yè)于清華大學(xué)計算機系,擁有十余年分布式存儲研究與產(chǎn)品經(jīng)驗。在創(chuàng)立 SmartX 之前,張凱曾就職于 Baidu,負責(zé)大數(shù)據(jù)平臺基礎(chǔ)設(shè)施建設(shè)、穩(wěn)定性和性能優(yōu)化。
文章轉(zhuǎn)載:CSDN(ID:CSDNnews)
(版權(quán)歸原作者所有,侵刪)