

Python 的列表解析式是解決任務最有效的方法嗎?
Python 是一種極其多樣化和強大的編程語言!當需要解決一個問題時,它有著不同的方法。在本文中,我將向您展示列表解析式(List Comprehension)。我們將討論如何使用它?什么時候該或不該使用它?小伙伴們,把全文都讀下來把!
列表解析式的優勢
-
比循環更節省時間和空間。 -
需要更少的代碼行。 -
可將迭代語句轉換為公式。
如何在 Python 中創建列表
列表解析式是一種基于現有列表創建列表的語法結構。讓我們來看看創建列表的不同實現
循環
循環是創建列表的傳統方式。不管你使用什么樣的循環。要以這種方式創建列表,您應該:
-
實例化一個空列表。 -
循環遍歷一個可迭代的(如? range)的元素。 -
將每個元素附加到列表的末尾。 

輸出:

在此示例中,您實例化了一個空列表?
numbers。然后使用?for?循環迭代?range(10)?并使用?append()?方法將每個數字附加到列表的末尾。map() 對象
map()?是創建列表的另一種方法。您需要向?map()?傳遞一個函數和一個可迭代對象,之后它會創建一個對象。該對象包含使用指定函數執行每個迭代元素所獲得的輸出。例如,我們將呈現在某些產品的價格中增加增值稅的任務。
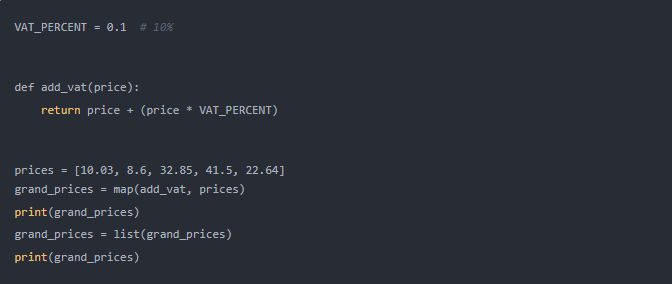
您已經構建了?
add_vat()?函數并創建了?prices?可迭代對象。您將這兩個參數都傳遞給?map()?并收集生成的?map?對象?grand_prices,或者您可以使用?list()?輕松地將其轉換為列表。輸出:

列表解析式
現在,讓我們看一下列表解析式方法!這確實是 Python 風格,并且是創建列表的更好方法。為了弄清楚這種方法有多強大,我們用一個單行代碼來重寫那個循環示例。

輸出

正如您所見,這是一種不可思議的方法!列表解析式看起來足夠可讀,您不需要編寫更多代碼,而只需一行。
為了更好地理解列表,請查看以下語法格式:

哪種方法更有效
好的,我們已經學習了如何使用循環、
map()?和列表解析式來創建列表,在您的腦海中可能會提出“哪種方法更有效”的問題。我們來分析一下吧!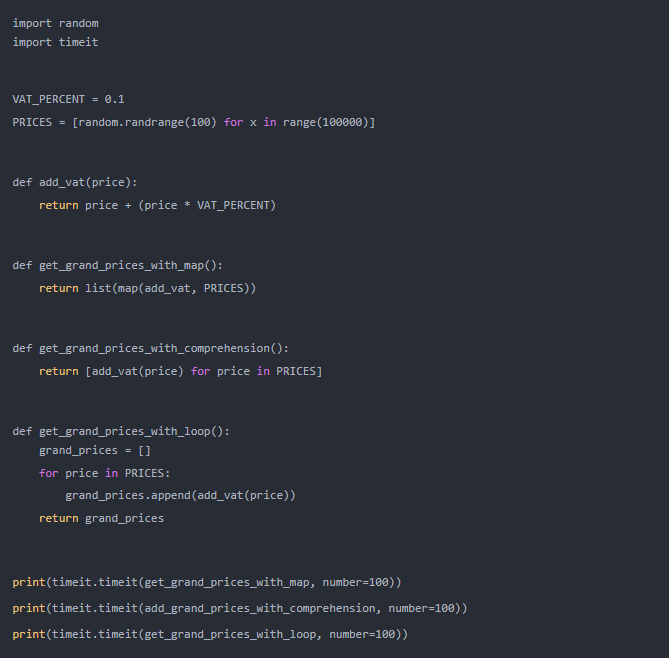
輸出:

正如我們現在所看到的,創建列表的最優的方法是?
map(),排在第二位的是列表解析式,最后是循環。但是,方法的選擇應取決于您想要實現的目標。
-
使用? map()?可以使你的代碼更高效。 -
使用循環可以使代碼的思路展現更加清晰。 -
使用列表解析式可以您使代碼更加緊湊,且較高效。這是創建列表的最佳方式,因為這種方式可讀性最強。
高級解析式
條件邏輯
早些時候,我向您展示了這個公式:

公式可能有些不完整。對解析式的更加完整描述增加了對可選條件的支持。將條件邏輯添加到列表解析式的最常見方法是在表達式的末尾添加條件:

在這里,您的條件語句正好位于右邊的括號中。
條件很重要,因為它們允許列表解析式過濾掉不需要的值,這在一般情況下也可以調用?
filter():
輸出:

正如您所看到的那樣,這個解析式收集了可被 2 整除且沒有余數的數字。
如果您需要更復雜的過濾器,那么您甚至可以將條件邏輯移動到單獨的函數中。
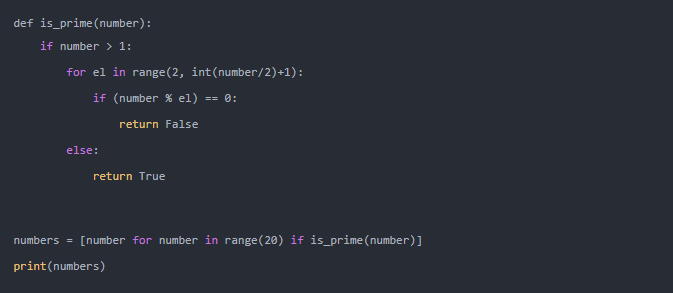
輸出:

您構建?
is_prime(number)?以確定是否是素數并返回布爾值。接下來,您應該將函數添加到解析式的條件中。該公式允許您使用條件邏輯從幾個可能的輸出選項中進行選擇。例如,您有一個產品價格表,若有負數,您應將其轉換為正數:

輸出:

在這里,您的表達式?
price?有一個條件語句,如果?price > 0 else price*-1。這會告訴 Python,如果價格為正,則輸出價格值;但如果價格為負,則將價格轉換為正值。該功能很強大,考慮將條件邏輯視為其自身的函數的確是很有用的: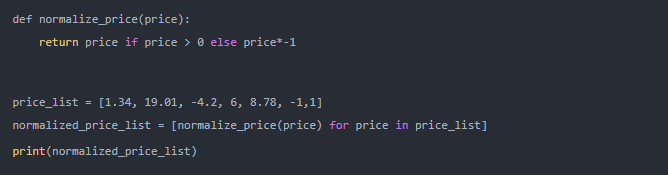
輸出:

集合解析式
您還可以創建一個集合解析式!它基本與列表解析式相同。不同之處在于集合解析式不包含重復項。您可以通過使用花括號取代方括號來創建集合解析式:

輸出:

你的集合解析式只包含唯一的字母。這與列表不同,集合不保證項目將以特定順序存儲數據。這就是為什么集合輸出的第二個字母是?
e,即使字符串中的第二個字母是?x。字典解析式
字典解析式也是是類似的,但需要定義一個鍵:

輸出:

要創建?
word_order?字典,請在表達式中使用花括號 ({}) 以及鍵值對 (el: ind+1)。海象運算符
Python 3.8 中引入的海象運算符允許您一次解決兩個問題:為變量賦值,返回該值。
假設您需要對將返回溫度數據的 API 應用十次。您想要的只是 100 華氏度以上的結果。而每個請求可能都會返回不同的數據。在這種情況下,沒有辦法在 Python 中使用列表解析式來解決問題。可迭代成員(如果有條件)的公式表達式無法讓條件將數據分配給表達式可以訪問的變量。
海象運算符解決了這個問題。它允許您在執行表達式的同時將輸出值分配給變量。以下示例顯示了這是如何實現的,使用?
get_weather_data()?生成偽天氣數據: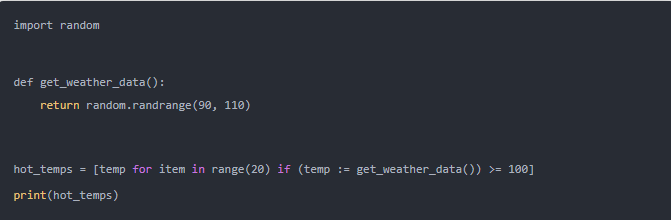
輸出:

什么時候不要使用解析式
列表解析式非常有用,它可以幫助您編寫清晰且易于閱讀和調試的代碼。但在某些情況下,它們可能會使您的代碼運行速度變慢或使用更多內存。如果它讓您的代碼效率更低或更難理解,那么可以考慮選擇另一種方式。
注意嵌套的解析式
可以通過嵌套解析式以創建列表、字典和集合的組合集合(譯者注:這個集合不是指 set 對象類型,而是 collection,泛指容器)。例如,假設一家公司正在跟蹤一年中五個不同城市的收入。存儲這些數據的完美數據結構可以是嵌套在字典解析式中的列表解析式。

輸出:
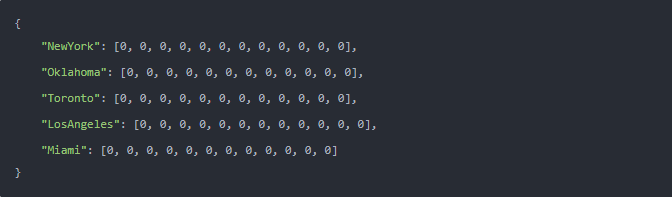
您使用字典解析式創建了?
budgets?容器。該表達式是一個鍵值對,其中包含另一個解析式。此代碼將快速生成城市中每個?city?的數據列表。嵌套列表是創建矩陣的常用方法,通常用于數學目的。查看下面的代碼塊:

輸出:

外部列表解析式?
[... for y in range(6)]?創建了六行,而內部列表解析式?[x for x in range(7)]?將用值填充這些行中的每一行。到目前為止,每個嵌套解析式的目標都是真正且直觀的。但是,還有一些其他情況,例如創建扁平化的嵌套列表,其中的邏輯可以使您的代碼非常難以閱讀。讓我們看下面的例子,使用嵌套列表解析式來展平一個矩陣:
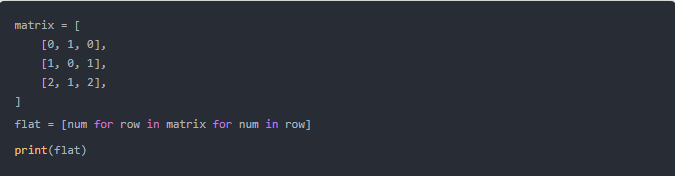
輸出:

扁平化矩陣的代碼確實很簡潔,但是太難理解了,您應該花點時間弄清楚它是如何工作的。另一方面,如果您使用?
for?循環來展平相同的矩陣,那么您的代碼將更加簡單易讀:
輸出:

現在,您可以看到代碼一次遍歷矩陣的一行,在移動到下一行之前取出該行中的所有元素。
雖然嵌套列表解析式可能看起來更具有 Python 風格,但對于能夠編寫出您的團隊可以輕松理解和修改的代碼來才是更加最重要的。當選擇一個方法時,您應該根據解析式是有助于還是有損于可讀性來做出相應的判斷。
為大型數據集使用生成器
Python 中的列表解析式通過將整個列表存儲到內存中來工作。對于小型至中型列表這通常很好。如果您想將前一千個整數相加,那么列表解析式將輕松地解決此任務:

輸出:
499500但是,如果您需要對十億個數字求和呢?您可以嘗試執行此操作,但您的計算機可能不會有響應。這是可能因為計算機中分配大量內存。也許您是因為計算機沒有如此多的內存資源。
例如,你想要一些第一個十億整數,那么讓我們使用生成器!這可能多需要一些時間,但計算機應該可以克服它:

輸出:

讓我們來對比一下哪種方法是更優的!

輸出:

正如您所見,生成器比?
map()?高效得多。總結
本文向您介紹了列表解析式,以及如何使用它來解決復雜的任務,而不會使您的代碼變得過于困難。
現在你:
-
學習了幾種創建列表的替代方法。 -
找出每種方法的優點。 -
可以簡化循環和 map() 調用列表解析式。 -
理解了一種將條件邏輯添加到解析式中的方法。 -
可以創建集合和字典解析式。 -
學會了何時不使用解析式。
感謝您閱讀本文直到結束!如果這篇文章有幫助,請發表評論,記得點擊“關注”確保你不會錯過我的文章!你的活動是我的快樂!祝你好運!
鏈接:https://blog.devgenius.io/is-list-comprehension-the-most-effective-way-to-solve-any-tasks-python-b6bb3f5391fa#:~:text=compact%20yet%20optimized.-,Advance%20Level%20of%20a%20Comprehension,-Conditionals%20Logic
(版權歸原作者所有,侵刪)
-