時序數據庫之InfluxDB
最近公司業務重度依賴時序數據庫, 公司上個版本選擇了OpenTSDB, 在1-2年前,他的確很流行。但是在做軟件重構時, 業務層反饋的一些問題, OpenTSDB暫時無法解決,成為了一個痛點, 讓我需要考慮其他方案, 由于之前使用過InfluxDB, 也一直在關注, 它給了我驚艷的感覺,所以記憶猶新.
之前做運維時,重度使用過zabbix, 關系型數據庫的優化,根本無法解決高IO, 后面又使用過Graphite, 這個安裝像迷一樣的工具, 它后端在RRD上面設計出了一個簡單的時序數據庫, 但是配置繁雜,容量完全靠規劃。直到使用了InfluxDB, 部署簡單,使用方便,高壓縮, 對它印象很不錯, 但是0.12過后不支持集群。
之前InfluxDB切換了2次存儲引擎(它的存儲是插件式的), 也沒去了解過它切換的原因, 直到看到InfoQ上七牛的演講從InfluxDB看時序數據的處, 他道出了了原因:
-
LevelDB不支持熱備份, influxDB設計的shard會消耗大量文件描述符,將系統資源耗盡。
-
BoltDB解決了熱備, 解決了消耗大量文件描述符的問題, 但是引入了一個更致命的問題:容量達到數GB級別時,會產生大量隨機寫, 造成高IOPS。
-
放棄了他們, 在他們的經驗上開始自己實現一個存儲引擎: TSM(Time-Structured Merge Tree), 它截取了OpenTSDB的一些設計經驗,根據LSM Tree針對時間序列數據進行優化
我認為像這樣的針對特殊場景進行優化的數據庫會是今后數據庫領域發展的主流, 另一個證明就是EleasticSearch一個針對文本解索而設計的數據庫, 雖然OpenTSDB也針對時序數據做了優化,但是由于存儲系統依然依賴HBase, 所以力度上面感覺沒InfluxDB給力。
社區一路走來之艱辛,但是卻激情洋溢,他們是先行者. 我對它集群的閉源并不反感, 這群激情洋溢的人需要有商業支持。
這是DB Engine的時序數據庫最新的排行榜
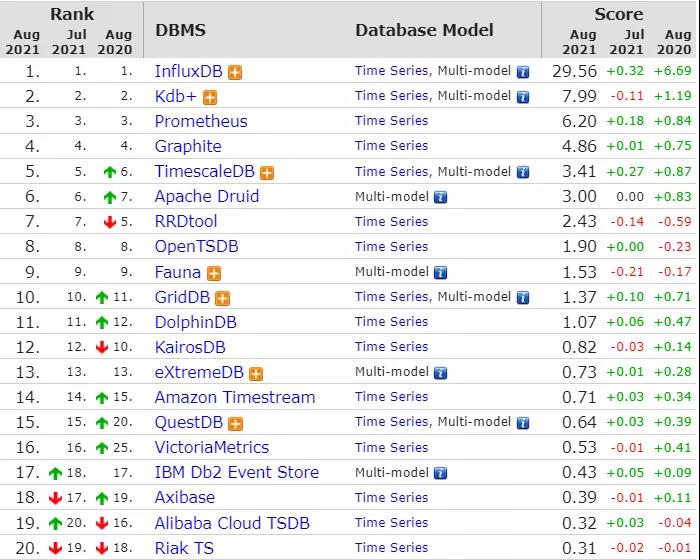

上圖可以看出InfluxDB超級火熱, 穩居第一,對于一個設計精良,部署簡單,使用方便,而且還高性能的時序數據庫而言, 想不熱都難。
基于Go語言開發,社區非常活躍,項目更新速度很快,日新月異,關注度高, 1.0發布過后, 穩定性也非常高。官方是這樣介紹InfluxDB的:
influxdb是一個從底層一步一步成長為能處理高寫入,高查詢的時序數據庫, 它專門針對時序數據做了優化,讓其更高性能, 他可以用來存儲任何時序數據, 包括DevOps的監控、應用指標、物聯網傳感器的數據, 并實時分析
這是它github上給出的特性說明:
-
內建HTTP API, 無需自己實現
-
數據高壓縮, 支持非常靈活的查詢訪問
-
支持類SQL查詢, 學習成本低, 方便使用
-
安裝和管理都十分簡單, 數據寫入和讀取的速度快
-
為實時查詢而生, 對每一個點位都建立索引, 及時查詢響應速度小于100ms
我們需要一個時序數據庫, 他需要能解決我們以下這些問題:
-
一個測試指標多值
一個指標往往有多個維度來描述其變化狀態,并不僅僅是值, 比如對于CPU的而言, 應該有中斷,負載, 使用率等。
? ?2.多Tag支持
tag是對一個指標的描述,是一個標簽, 在業務上Tag對于分組過濾非常有意義, 用于標示一個指標在業務上的意義, 比如對于IOT來說, 傳感器的指標往往是一個無意義的id, 因此需求給它打上name標簽, 標示他的特殊意義, 打上設備ID, 標示它屬于哪個設備, 打上位置標簽, 標示該指標來源于哪個地方。
? ? ? 3.在指標的值上能做一些基本的比較運算
作為一個數據庫,在功能層面需要解決一些基本的運算, 比如求和,求最小,求最大, 但這還不夠, 需要支持條件過濾, 支持Tag的條件過濾, 支持值的條件過濾, 支持值的條件過濾是關鍵, 不然會產生巨大的數據復制, 比如我們需要過濾出 CPU > 90的機器, 如果數據庫不支持, 那么我需要將這些數據從數據庫中查出來,復制給我的程序處理。
這帶來了巨大的問題:
-
數據庫要吐出如此大量的數據, 負載升高, 出口流量暴增
-
程序拿到如此大量的數據, 給處理方帶來了巨大的計算壓力, 如果前段采用Angular或者React來寫, 一個運行在pc上的小小的瀏覽器,根本處理不了。
-
處理效率低,數據的處理本該在數據存儲的地方進行, 比如Hadoop, 完全沒必要復制。
? ? 4.指標計算的中間結果需要存會指標
這是一個比較常見的場景, 使用RDD時更是常用,比如數據是按照30秒存儲的,但是我需要 這樣一個聚合維度 5m, 15m, 1h, 3h, 12h, 然后我平時只使用這些維度的數據, 不用每次臨時計算。
influxDB的核心概念包含: Line Protocol, Retention Policy, Series, Point, Continuous Query.
5.1 Line Protocol
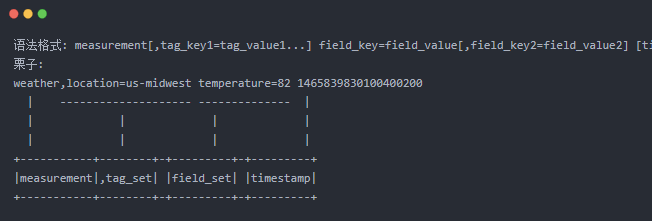
Line Protocol用于描述存入數據庫的數據格式, 也可以說是數據協議, 相比于JSON格式,Line Protocol無需序列化,更加高效, 官方對它做了全面的介紹Line Protocol, 下面摘取語法部分做簡要說明:Line Protocol里面的一行就是InfluxDB里面的一個點位, 他將一個點分割成measurement, tag_set, field_set, timestamp4個部分, 例如:
-
measurement: metric name, 需要監控的指標的名稱, 比如上面的weather
-
tag_set: 使用”,”與measurement隔開, 表示一組Tag的集合, 用于保存點位的元數據, 為可選項, 會進行索引,方便查詢時用于過濾條件, 格式: =,=, 比如上面的location=us-midwest
-
field_set: 使用空格與tag_set隔開, 標示一組Field的集合, 用于保存該點位多維度的值, 支持各種類型,數據存儲時不會進行索引,格式: =,=, 比如上面的temperature=82
-
timestamp: 采集該點位的時間戳, 時間的默認精度是納秒.
存儲策略:measurements,tag keys,field keys,tag values全局存一份。field values和timestamps每條數據存一份。
5.2 Retention Policy
指數據的保存策略, 包含數據的保存時間和副本數(集群中的概念),默認保存時間是永久,副本是1個, 但是我們可以修改, 也可以創建新的保存策略
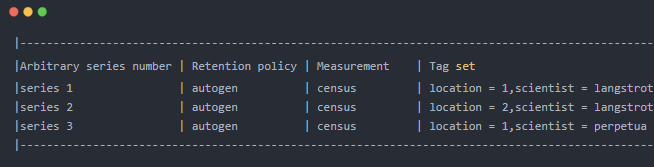
5.3 Series
InfluxDB中元數據的數據結構體, series相當于是InfluxDB中元數據的集合,在同一個database中,retention policy、measurement、tag sets完全相同的數據同屬于一個series,同一個series的數據在物理上會按照時間順序排列存儲在一起。
series 的key為 measurement+所有tags的序列化字符串, 他保存著該series的Retention policy, Measurement,Tag set, 比如:
5.4 Point
InfluxDB中單條插入語句的數據結構體, 用于保存點位的值的集合, 每一個Point通過series和timestamp進行唯一標示:

5.5 Schema
用于描述數據在InfluxDB的組織形式, InfluxDB的Schema十分簡單由 這些概念組成:
-
databases
-
retention policies
-
series
-
measurements
-
tag keys
-
tag values
-
field keys
在操作數據庫的時候,需要知道這些概念。
5.6 Continuous Query
簡稱CQ, 是預先配置好的一些查詢命令,SELECT語句必須包含GROUP BY time(),influxdb會定期自動執行這些命令并將查詢結果寫入指定的另外的measurement中。
利用這個特性并結合RP我們可以方便地保存不同粒度的數據,根據數據粒度的不同設置不同的保存時間,這樣不僅節約了存儲空間,而且加速了時間間隔較長的數據查詢效率,避免查詢時再進行聚合計算。
5.7 存儲引擎
從LevelDB(LSM Tree),到BoltD(mmap B+樹),現在是自己實現的TSM Tree的算法,類似LSM Tree,針對InfluxDB的使用做了特殊優化。
5.7.1 Shard
Shard這個概念并不對普通用戶開放,Shard也不是存儲引擎, 它在存儲引擎之上的一個概念, 存儲引擎負責存儲shard, 因此在講存儲引擎之前先講明shard。
在InfluxDB中按照數據的時間戳所在的范圍,會去創建不同的shard,每一個shard都有自己的存儲引擎相關文件,這樣做的目的就是為了可以通過時間來快速定位到要查詢數據的相關資源,加速查詢的過程,并且也讓之后的批量刪除數據的操作變得非常簡單且高效。
它和retention policy相關聯。每一個存儲策略下會存在許多shard,每一個shard存儲一個指定時間段內的數據,并且不重復,例如7點-8點的數據落入shard0 中,8點-9點的數據則落入shard1中。每一個shard都對應一個底層的存儲引擎。
當檢測到一個shard中的數據過期后,只需要將這個shard的資源釋放,相關文件刪除即可,這樣的做法使得刪除過期數據變得非常高效。
5.7.2 LevelDB
5.7.3 BoltDB
5.7.4 TSM Tree
6.1 安裝與部署
我這里主要做功能測試, 后面會有機會專門做性能測試, 因此這里使用官方提供的docker鏡像部署,官方鏡像最新也是1.2版本
配置Daocloud的鏡像加速源或者阿里的加速源,然后直接拉取鏡像

由于influxDB開發時就設計好了, 官方也給出了環境配置變量,啟動時可以通過這些環境變量對influxdb進行配置InfluxDB配置
6.2 函數與SQL
內部提供很多函數,方便一些基本操作InfluxQL Functions
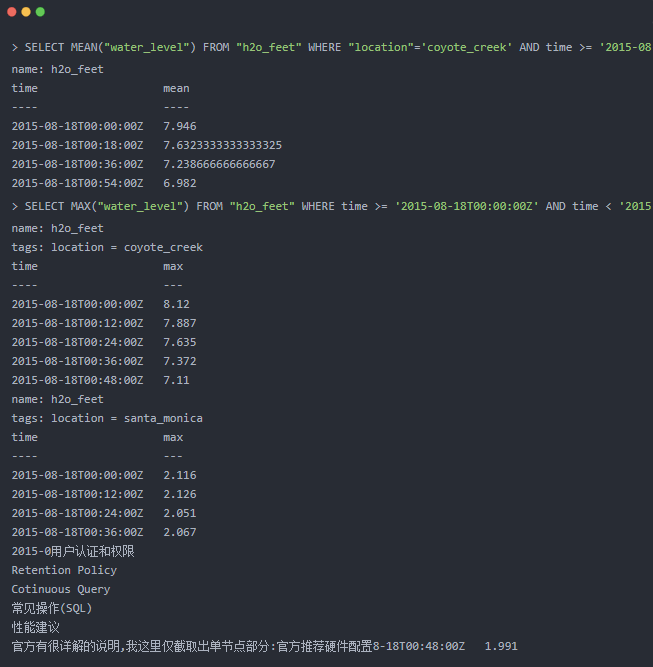
6.3 用戶認證和權限
6.4 Retention Policy
6.5 Cotinuous Query
6.6 常見操作(SQL)
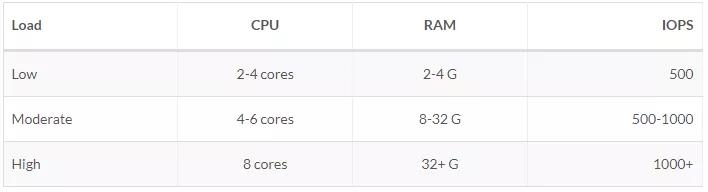
官方有很詳解的說明,我這里僅截取出單節點部分:官方推薦硬件配置
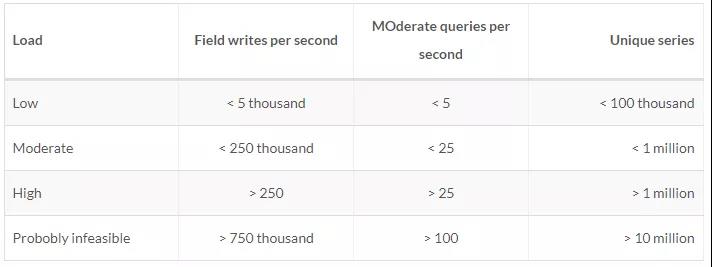
根據負載情況官方推薦的硬件需求: