

Python爬蟲工程師是干什么的?能賺多少錢?需要掌握哪些技術(shù)?
程序員有時候很難和外行人講明白自己的工作是什么,講一下“爬蟲工程師”的工作內(nèi)容是什么,需要掌握哪些技能,難點(diǎn)和好玩的地方等等,講到哪里算哪里吧。
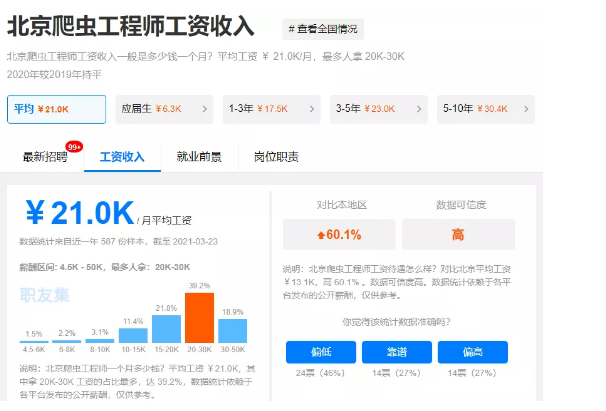

一、爬蟲工程師是干嘛的?
-
爬知乎的作者和回答 -
爬百度網(wǎng)盤的資源,存到數(shù)據(jù)庫中(當(dāng)然,只是保存資源的鏈接和標(biāo)題),然后制作一個網(wǎng)盤的搜索引擎 -
同上,種子網(wǎng)站的搜索引擎也是這樣的
二、爬蟲工程師需要掌握哪些技能?
-
如果中間遇到錯誤停掉,重頭再來?這不科學(xué) -
我怎么知道程序在哪里失敗了?任務(wù)和任務(wù)之間不應(yīng)該相互影響 -
如果我有兩臺機(jī)器怎么分工?