

Kubernetes 集群網絡從懵圈到熟悉
在Kubernetes中要保證容器之間網絡互通,網絡至關重要。而Kubernetes本身并沒有自己實現容器網絡,而是通過插件化的方式自由接入進來。在容器網絡接入進來需要滿足如下基本原則:
-
Pod無論運行在任何節點都可以互相直接通信,而不需要借助NAT地址轉換實現。 -
Node與Pod可以互相通信,在不限制的前提下,Pod可以訪問任意網絡。 -
Pod擁有獨立的網絡棧,Pod看到自己的地址和外部看見的地址應該是一樣的,并且同個Pod內所有的容器共享同個網絡棧。
容器網絡基礎
一個Linux容器的網絡棧是被隔離在它自己的Network Namespace中,Network Namespace包括了:網卡(Network Interface),回環設備(Lookback Device),路由表(Routing Table)和iptables規則,對于服務進程來講這些就構建了它發起請求和相應的基本環境。而要實現一個容器網絡,離不開以下Linux網絡功能:
-
網絡命名空間:將獨立的網絡協議棧隔離到不同的命令空間中,彼此間無法通信 -
Veth Pair:Veth設備對的引入是為了實現在不同網絡命名空間的通信,總是以兩張虛擬網卡(veth peer)的形式成對出現的。并且,從其中一端發出的數據,總是能在另外一端收到 -
Iptables/Netfilter:Netfilter負責在內核中執行各種掛接的規則(過濾、修改、丟棄等),運行在內核中;Iptables模式是在用戶模式下運行的進程,負責協助維護內核中Netfilter的各種規則表;通過二者的配合來實現整個Linux網絡協議棧中靈活的數據包處理機制 -
網橋:網橋是一個二層網絡虛擬設備,類似交換機,主要功能是通過學習而來的Mac地址將數據幀轉發到網橋的不同端口上 -
路由: Linux系統包含一個完整的路由功能,當IP層在處理數據發送或轉發的時候,會使用路由表來決定發往哪里
基于以上的基礎,同宿主機的容器時間如何通信呢?
我們可以簡單把他們理解成兩臺主機,主機之間通過網線連接起來,如果要多臺主機通信,我們通過交換機就可以實現彼此互通,在Linux中,我們可以通過網橋來轉發數據。
在容器中,以上的實現是通過docker0網橋,凡是連接到docker0的容器,就可以通過它來進行通信。要想容器能夠連接到docker0網橋,我們也需要類似網線的虛擬設備Veth Pair來把容器連接到網橋上。
我們啟動一個容器:


然后查看網卡設備:
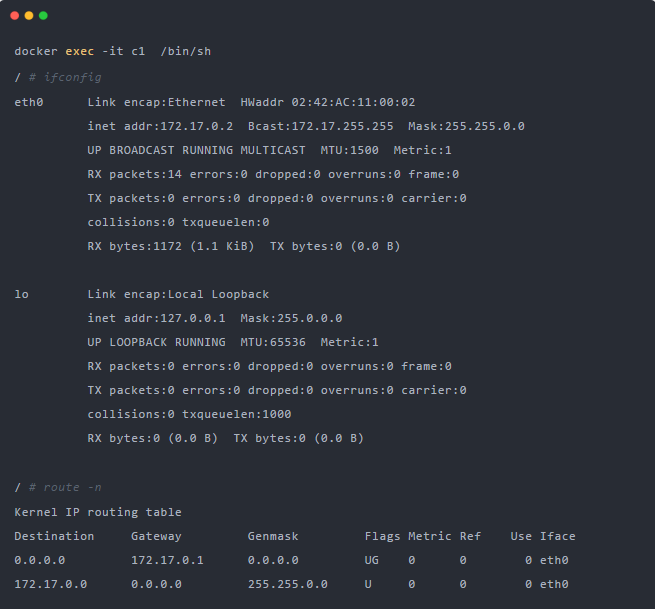
可以看到其中有一張eth0的網卡,它就是veth peer其中的一端的虛擬網卡。然后通過route -n 查看容器中的路由表,eth0也正是默認路由出口。所有對172.17.0.0/16網段的請求都會從eth0出去。
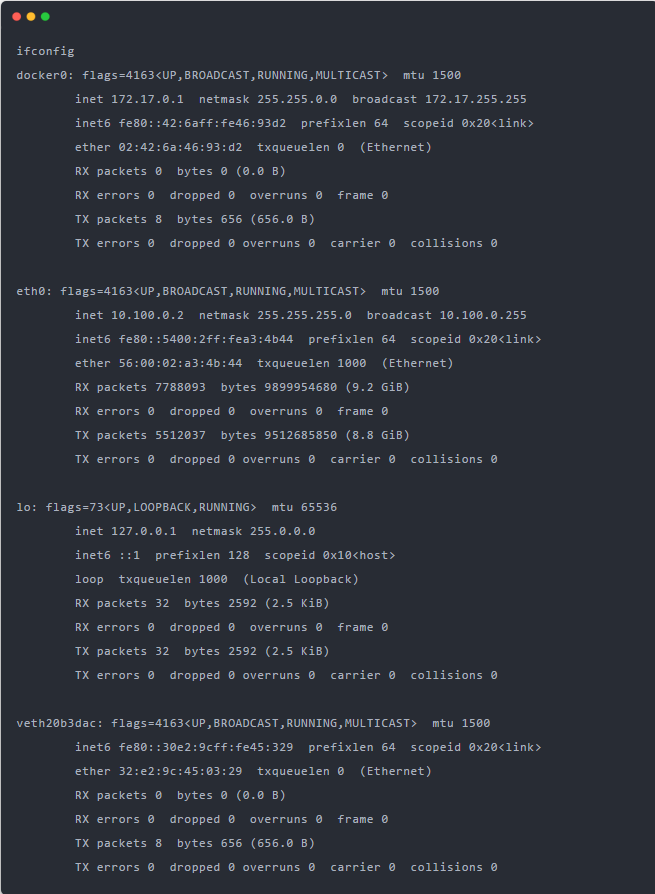
我們可以看到,容器對應的Veth peer另一端是宿主機上的一塊虛擬網卡叫veth20b3dac,并且可以通過brctl查看網橋信息看到這張網卡是在docker0上。

然后我們再啟動一個容器,從第一個容器是否能ping通第二個容器。
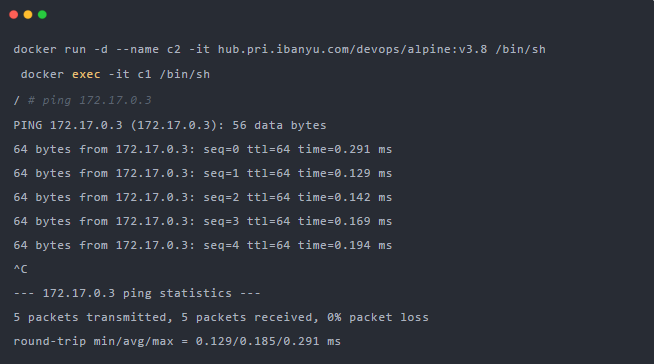
可以看到,能夠ping通,其原理就是我們ping目標IP172.17.0.3時,會匹配到我們的路由表第二條規則,網關為0.0.0.0,這就意味著是一條直連路由,通過二層轉發到目的地。要通過二層網絡到達172.17.0.3,我們需要知道它的Mac地址,此時就需要第一個容器發送一個ARP廣播,來通過IP地址查找Mac。此時Veth peer另外一段是docker0網橋,它會廣播到所有連接它的veth peer虛擬網卡去,然后正確的虛擬網卡收到后會響應這個ARP報文,然后網橋再回給第一個容器。
以上就是同宿主機不同容器通過docker0通信,如下圖所示:
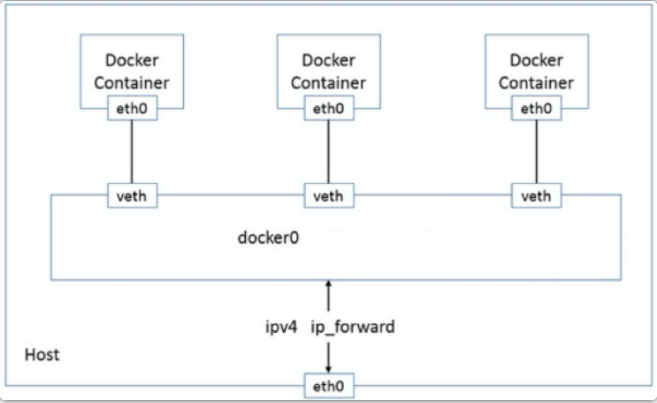
默認情況下,通過network namespace限制的容器進程,本質上是通過Veth peer設備和宿主機網橋的方式,實現了不同network namespace的數據交換。
與之類似地,當你在一臺宿主機上,訪問該宿主機上的容器的IP地址時,這個請求的數據包,也是先根據路由規則到達docker0網橋,然后被轉發到對應的Veth Pair設備,最后出現在容器里。
跨主機網絡通信
在Docker的默認配置下,不同宿主機上的容器通過IP地址進行互相訪問是根本做不到的。為了解決這個問題,社區中出現了很多網絡方案。同時Kubernetes為了更好的控制網絡的接入,推出了CNI即容器網絡的API接口。它是Kubernetes中標準的一個調用網絡實現的接口,kubelet通過這個API來調用不同的網絡插件以實現不同的網絡配置,實現了這個接口的就是CNI插件,它實現了一系列的CNI API接口。目前已經有的包括Flannel、Calico、Weave、Contiv等等。
實際上CNI的容器網絡通信流程跟前面的基礎網絡一樣,只是CNI維護了一個單獨的網橋來代替 docker0。這個網橋的名字就叫作:CNI 網橋,它在宿主機上的設備名稱默認是:cni0。cni的設計思想,就是:Kubernetes在啟動Infra容器之后,就可以直接調用CNI網絡插件,為這個Infra容器的Network Namespace,配置符合預期的網絡棧。
CNI插件三種網絡實現模式:
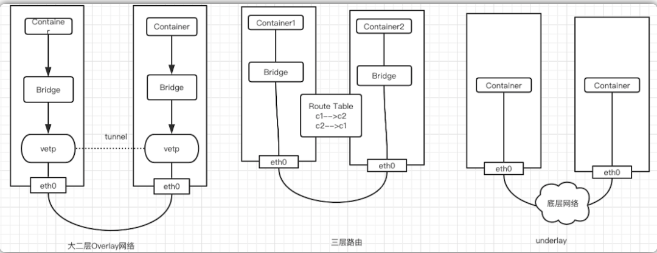
-
Overlay模式是基于隧道技術實現的,整個容器網絡和主機網絡獨立,容器之間跨主機通信時將整個容器網絡封裝到底層網絡中,然后到達目標機器后再解封裝傳遞到目標容器。不依賴與底層網絡的實現。實現的插件有Flannel(UDP、vxlan)、Calico(IPIP)等等 -
三層路由模式中容器和主機也屬于不通的網段,他們容器互通主要是基于路由表打通,無需在主機之間建立隧道封包。但是限制條件必須依賴大二層同個局域網內。實現的插件有Flannel(host-gw)、Calico(BGP)等等 -
Underlay網絡是底層網絡,負責互聯互通。容器網絡和主機網絡依然分屬不同的網段,但是彼此處于同一層網絡,處于相同的地位。整個網絡三層互通,沒有大二層的限制,但是需要強依賴底層網絡的實現支持.實現的插件有Calico(BGP)等等
我們看下路由模式的一種實現flannel Host-gw:

如圖可以看到當node1上container-1要發數據給node2上的container2時,會匹配到如下的路由表規則:

表示前往目標網段10.244.1.0/24的IP包,需要經過本機eth0出去發往的下一跳IP地址為10.168.0.3(node2),然后到達10.168.0.3以后再通過路由表轉發CNI網橋,進而進入到container2。
以上可以看到host-gw工作原理,其實就是在每個Node節點配置到每個Pod網段的下一跳為Pod網段所在的Node節點IP,Pod網段和Node節點IP的映射關系,Flannel保存在etcd或者Kubernetes中。Flannel只需要watch這些數據的變化來動態更新路由表即可。
這種網絡模式最大的好處就是避免了額外的封包和解包帶來的網絡性能損耗。缺點我們也能看見主要就是容器IP包通過下一跳出去時,必須要二層通信封裝成數據幀發送到下一跳。如果不在同個二層局域網,那么就要交給三層網關,而此時網關是不知道目標容器網絡的(也可以靜態在每個網關配置Pod網段路由)。所以flannel host-gw必須要求集群宿主機是二層互通的。
而為了解決二層互通的限制性,Calico提供的網絡方案就可以更好的實現,Calico大三層網絡模式與Flannel提供的類似,也會在每臺宿主機添加如下格式的路由規則:

其中網關的IP地址不通場景有不同的意思,如果宿主機是二層可達那么就是目的容器所在的宿主機的IP地址,如果是三層不同局域網那么就是本機宿主機的網關IP(交換機或者路由器地址)。
不同于Flannel通過Kubernetes或者etcd存儲的數據來維護本機路由信息的做法,Calico是通過BGP動態路由協議來分發整個集群路由信息。
BGP全稱是Border Gateway Protocol邊界網關協議,Linxu原生支持的、專門用于在大規模數據中心為不同的自治系統之間傳遞路由信息。只要記住BGP簡單理解其實就是實現大規模網絡中節點路由信息同步共享的一種協議。而BGP這種協議就能代替Flannel維護主機路由表功能。
Calico主要由三個部分組成:
-
Calico CNI插件:主要負責與kubernetes對接,供kubelet調用使用。 -
Felix:負責維護宿主機上的路由規則、FIB轉發信息庫等。 -
BIRD:負責分發路由規則,類似路由器。 -
Confd:配置管理組件。
除此之外,Calico還和flannel host-gw不同之處在于,它不會創建網橋設備,而是通過路由表來維護每個Pod的通信,如下圖所示:
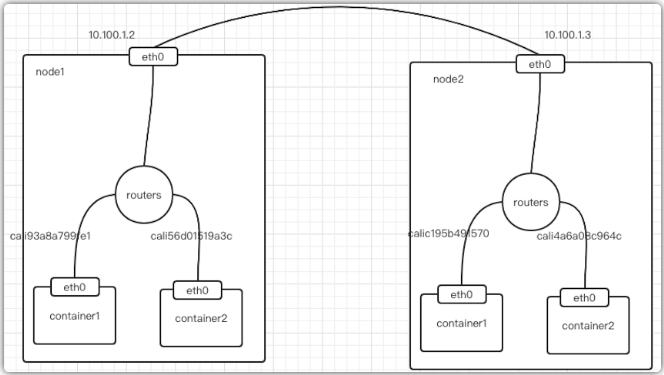
可以看到Calico的CNI插件會為每個容器設置一個veth pair設備,然后把另一端接入到宿主機網絡空間,由于沒有網橋,CNI插件還需要在宿主機上為每個容器的veth pair設備配置一條路由規則,用于接收傳入的IP包,路由規則如下:

以上表示發送10.92.77.163的IP包應該發給cali93a8a799fe1設備,然后到達另外一段容器中。
有了這樣的veth pair設備以后,容器發出的IP包就會通過veth pair設備到達宿主機,然后宿主機根據路有規則的下一條地址,發送給正確的網關(10.100.1.3),然后到達目標宿主機,在到達目標容器。

這些路由規則都是Felix維護配置的,而路由信息則是calico bird組件基于BGP分發而來。Calico實際上是將集群里所有的節點都當做邊界路由器來處理,他們一起組成了一個全互聯的網絡,彼此之間通過BGP交換路由,這些節點我們叫做BGP Peer。
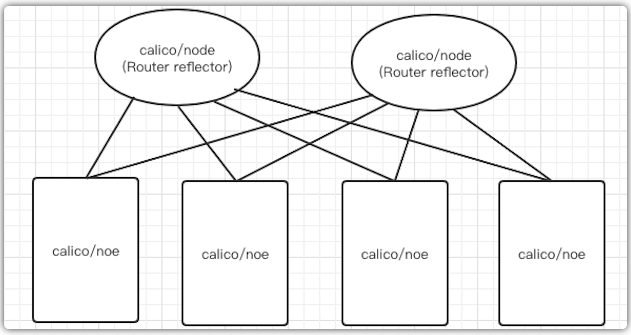
需要注意的是Calico維護網絡的默認模式是node-to-node mesh,這種模式下,每臺宿主機的BGP client都會跟集群所有的節點BGP client進行通信交換路由。這樣一來,隨著節點規模數量N的增加,連接會以N的2次方增長,會集群網絡本身帶來巨大壓力。
所以一般這種模式推薦的集群規模在50節點左右,超過50節點推薦使用另外一種RR(Router Reflector)模式,這種模式下,Calico可以指定幾個節點作為RR,他們負責跟所有節點BGP client建立通信來學習集群所有的路由,其他節點只需要跟RR節點交換路由即可。這樣大大降低了連接數量,同時為了集群網絡穩定性,建議RR>=2。
以上的工作原理依然是在二層通信,當我們有兩臺宿主機,一臺是10.100.0.2/24,節點上容器網絡是10.92.204.0/24;另外一臺是10.100.1.2/24,節點上容器網絡是10.92.203.0/24,此時兩臺機器因為不在同個二層所以需要三層路由通信,這時Calico就會在節點上生成如下路由表:

這時候問題就來了,因為10.100.1.2跟我們10.100.0.2不在同個子網,是不能二層通信的。這之后就需要使用Calico IPIP模式,當宿主機不在同個二層網絡時就是用Overlay網絡封裝以后再發出去。如下圖所示:
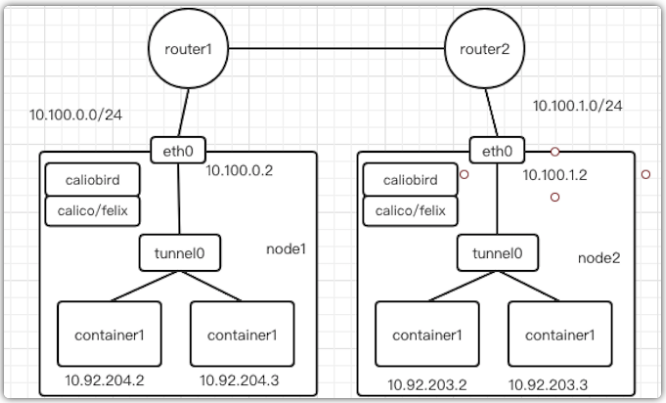
IPIP模式下在非二層通信時,Calico會在Node節點添加如下路由規則:

可以看到盡管下一條仍然是Node的IP地址,但是出口設備卻是tunnel0,其是一個IP隧道設備,主要有Linux內核的IPIP驅動實現。會將容器的IP包直接封裝宿主機網絡的IP包中,這樣到達node2以后再經過IPIP驅動拆包拿到原始容器IP包,然后通過路由規則發送給veth pair設備到達目標容器。
以上盡管可以解決非二層網絡通信,但是仍然會因為封包和解包導致性能下降。如果Calico能夠讓宿主機之間的router設備也學習到容器路由規則,這樣就可以直接三層通信了。比如在路由器添加如下的路由表:

而node1添加如下的路由表:

那么node1上的容器發出的IP包,基于本地路由表發送給10.100.1.1網關路由器,然后路由器收到IP包查看目的IP,通過本地路由表找到下一跳地址發送到node2,最終到達目的容器。這種方案,我們是可以基于underlay 網絡來實現,只要底層支持BGP網絡,可以和我們RR節點建立EBGP關系來交換集群內的路由信息。
以上就是Kubernetes常用的幾種網絡方案了,在公有云場景下一般用云廠商提供的或者使用flannel host-gw這種更簡單,而私有物理機房環境中,Calico項目更加適合。根據自己的實際場景,再選擇合適的網絡方案。
文章來源于網絡,侵刪!
