

為Python選擇一個更快的JSON庫
使用JSON越多, 你就越有可能遇到JSON編碼或解碼瓶頸。Python的內置庫也不錯, 但是還有多個更快的JSON庫可用: 如何選擇使用哪一個呢?
事實是,沒有一個正確的答案,沒有一個最快的JSON庫來超越其他所有庫:
一個“快速的JSON庫”對不同的人意味著不同的東西,因為它們的使用模式不同。
速度并不是一切——你可能還會關心其他一些事情,比如安全性和可定制性。
因此,為了幫助你根據需要選擇最快的JSON庫,我想在這里分享一下我為Python選擇一個快速JSON庫所經歷的過程。你可以使用這個過程來選擇最適合你的特殊需要的庫:
確保確實有問題需要用到JSON庫來解決。
定義基準。
根據附加要求來過濾。
對剩下的候選者進行基準測試。
步驟1:?你確實需要一個新的JSON 庫嗎?
使用JSON并不意味著它就是一個相關的瓶頸。在考慮使用哪個JSON庫之前,你需要一些證據來表明Python的內置JSON庫確實在特定應用程序中存在問題。
在我的例子中,我從我的原因日志庫Eliot(causal logging library Eliot)的基準測試中學到了這一點,它表明JSON編碼占用了大約25%的用于生成消息的CPU時間。我能得到的最大加速是比原先運行快33%(如果JSON編碼時間變為零),但那是一個足夠大的時間塊,使用最快的JSON庫會讓這個時間塊減小到最低。
步驟 2:?定義基準
如果你查看各種JSON庫的基準頁面,你會發現它們都會討論如何處理各種不同的消息。然而,這些消息并不一定與你的使用相關。其他人會經常測量非常大型消息,但在我的例子中,我只關心小型消息。
所以你想要提出一些符合你的特定使用模式的措施:
你關心編碼、解碼,還是兩者都關心?
你使用的是小型消息還是大型消息?
典型的消息是什么樣的?
在我的例子中,我主要關心的是編碼小型消息,即由Eliot生成的日志消息的特定結構。基于一些真實的日志,我整理出了以下示例消息:
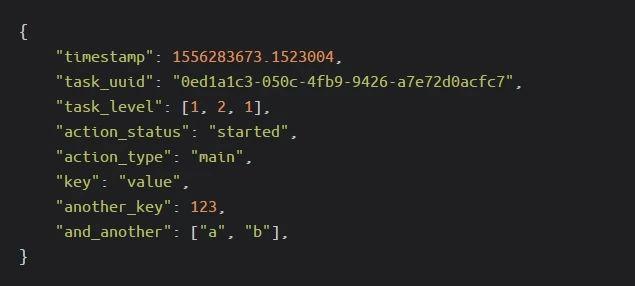

步驟 3:?根據附加要求來過濾
性能并不是一切——你可能還會關心其他一些事情。在我的例子中:
安全性/抗崩潰性:日志消息可以包含來自不可信源的數據。如果JSON編碼器在不良數據上崩潰,這對可靠性或安全性都不好。
自定義編碼: Eliot支持自定義JSON編碼,因此您可以序列化其他類型的Python對象。有些JSON庫支持這一點,有些則不支持。
跨平臺: 運行在Linux、macOS和Windows上。
維護: 我不想依賴一個沒有得到積極支持的庫。
我考慮的庫有orjson、rapidjson、ujson和hyperjson。
我根據上面的標準過濾掉了其中的一些:
ujson有很多關于崩潰的bug,即使那些已經修復的崩潰也并不總是可用,因為自2016年以來就沒有再發布過新版本。
hyperjson只有針對macOS的包,而且總體看起來也相當不成熟。
步驟 4:?基準測試
最后的兩個競爭者是rapidjson和orjson。我運行了以下基準測試:
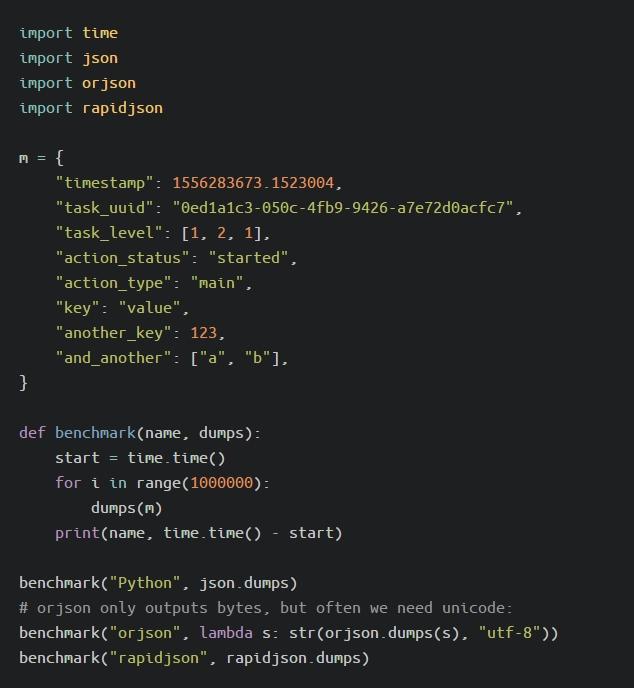
結果如下:
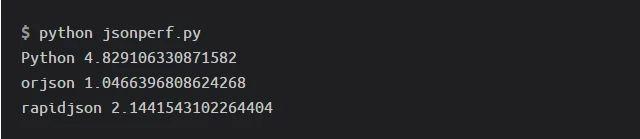
即使需要額外的Unicode解碼,orjson也是最快的(對于這個特定的基準測試!)。
與往常一樣,我也需要權衡。orjson的用戶比rapidjson要少(比較orjson PyPI stats和rapidjson PyPI stats),并且它也沒有Conda包,所以我必須自己為Conda-forge對它進行打包。但是,它確實要快得多。
需求為大
你應該使用orjson嗎? 不一定。你可能有不同的要求,你的基準測試也可能不同——例如,你可能需要解碼大型文件。
關鍵點是過程: 找出你的特定要求,比如性能以及其他方面,然后選擇最適合你的需求的庫。
聲明:文章來源于網絡,侵刪!