

一個(gè)Python小白如何快速完成爬蟲(chóng)
很人或多或少都聽(tīng)說(shuō)過(guò)Python爬蟲(chóng),但不知道如何通過(guò)Python爬蟲(chóng)來(lái)爬取自己想要的內(nèi)容,今天我就給大家說(shuō)一個(gè)爬蟲(chóng)教程來(lái)實(shí)現(xiàn)自己第一次Python爬蟲(chóng)。
環(huán)境搭建
既然用Python,那么自然少不了語(yǔ)言環(huán)境。于是乎到官網(wǎng)下載了3.5版本的。安裝完之后,隨機(jī)選擇了一個(gè)編輯器叫PyCharm,話說(shuō)Python編輯器還真挺多的。
建好項(xiàng)目,打開(kāi)編輯器,直接開(kāi)工。搜一個(gè)HTML解析工具,人家都做的那種,這事不要客氣,直接拿來(lái)用-BeautifulSoup 。安裝也很簡(jiǎn)單的。
發(fā)送請(qǐng)求
當(dāng)然我也是不清楚Python是怎么進(jìn)行網(wǎng)絡(luò)請(qǐng)求的,其中還有什么2.0和3.0的不同,通過(guò)各種百度,最終還是寫(xiě)出了最簡(jiǎn)單的一段請(qǐng)求代碼。
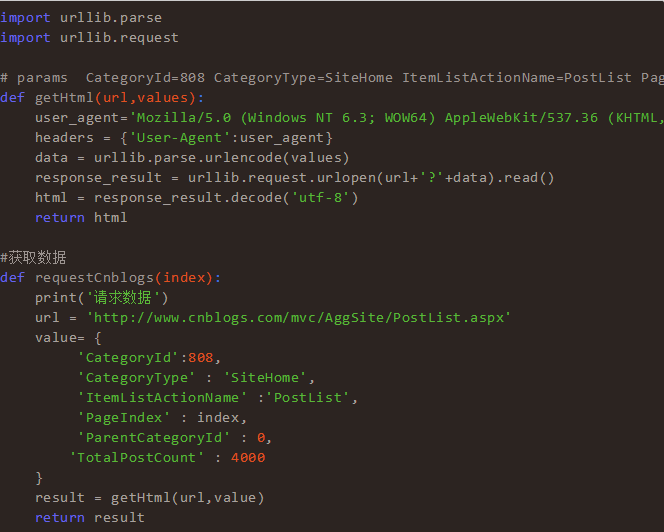

數(shù)據(jù)解析
上文已經(jīng)提到了,用到的是BeautifulSoup,好處就是不用自己寫(xiě)正則,只要根據(jù)他的語(yǔ)法來(lái)寫(xiě)就好了,在多次的測(cè)試之后終于完成了數(shù)據(jù)的解析。先上一段HTML。然后在對(duì)應(yīng)下面的代碼,也許看起來(lái)更輕松一些。
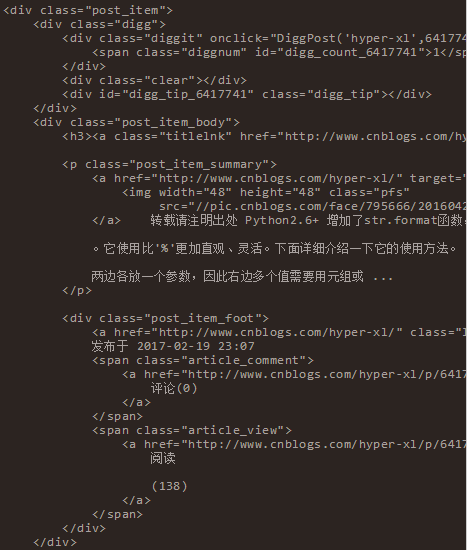
通過(guò)上文的HTML代碼可以看到幾點(diǎn)。首先每一條數(shù)據(jù)都在 div(class=”post_item”)下。然后 div(“post_item_body”)下有用戶信息,標(biāo)題,鏈接,簡(jiǎn)介等信息。逐一根據(jù)樣式解析即可。代碼如下:
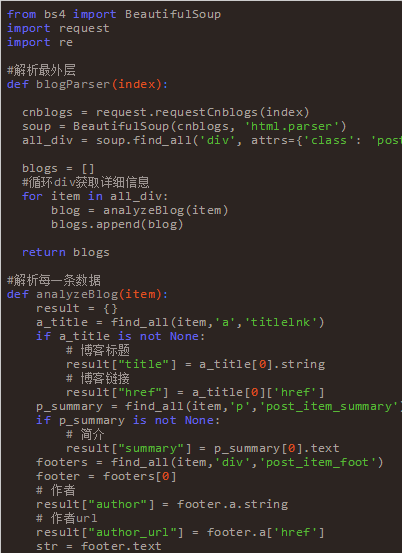
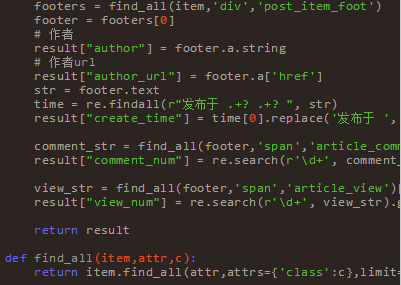
上邊一堆代碼下來(lái),著實(shí)會(huì)花費(fèi)不少時(shí)間,邊寫(xiě)邊調(diào)試,再百度,不過(guò)還好最終還是出來(lái)了。等數(shù)據(jù)都整理好之后,然后我把它保存到了txt文件里面,以供其他語(yǔ)言來(lái)處理。
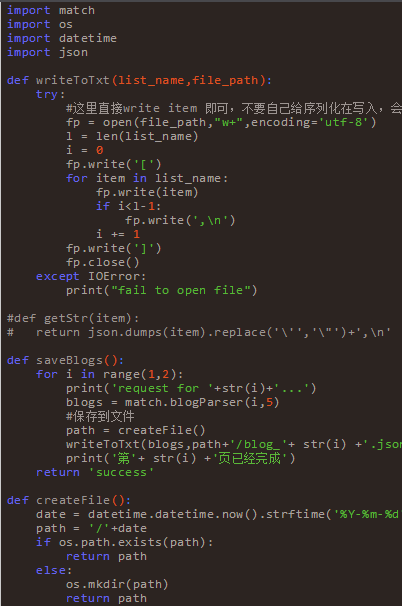
上邊呢,我取了一百頁(yè)的數(shù)據(jù),也就是大概2000條做測(cè)試。
成果驗(yàn)收
廢了好大勁終于寫(xiě)完那些代碼之后呢,就欣賞自己的成果了,像我這樣的初學(xué)者,代碼寫(xiě)的很渣,都是這參考一下,那參考一下,不過(guò)當(dāng)你真正完成了,你就會(huì)有一種莫名的自豪感。
聲明:文章來(lái)源于網(wǎng)絡(luò),侵刪!