

使用Python - PCA分析進行金融數據分析
1.pandas的一個技巧
apply() 和applymap()是DataFrame數據類型的函數,map()是Series數據類型的函數。apply()的操作目標DataFrame的一列或許一行數據, applymap()是element-wise的,作用于每個DataFrame的每個數據。 map()也是element-wise的,對Series中的每個數據調用一次函數。
2.PCA分解德國DAX30指數
DAX30指數有三十個股票,聽起來不多的樣子,其實還是挺多的,我們很有必要對其進行主成分分析,然后找出最重要的幾個股票。想必PCA的原理大家應該都是知道,說白了就是在一個回歸中找到影響最大的那幾個,當然,數學原理就涉及矩陣分解,什么SVD呀。
先上點代碼
- import?pandas?as?pd
- import?pandas.io.data?as?web
- import?numpy?as?np
- np.random.seed(1000)
- import?scipy.stats?as?scs
- import?statsmodels.api?as?sm
- import?matplotlib?as?mpl
- import?matplotlib.pyplot?as?plt
- from?sklearn.decomposition?import?KernelPCA#導入機器學習的PCA包
- symbols?=?['ADS.DE','ALV.DE','BAS.DE','BAYN.DE','BEI.DE','BMW.DE','CBK.DE','CON.DE','DAI.DE',
- ????????????'DB1.DE','DBK.DE','DPW.DE','DTE.DE','EOAN.DE','FME.DE','FRE.DE','HEI.DE','HEN3.DE',
- ????????????'IFX.DE','LHA.DE','LIN.DE','LXS.DE','MRK.DE','MUV2.DE','RWE.DE','SAP.DE','SDF.DE',
- ????????????'SIE.DE','TKA.DE','VOW3.DE','^GDAXI']#DAX30指數各個股票的代碼以及德國30指數代碼,共31個數據列
- data?=?pd.DataFrame()
- for?sym?in?symbols:#獲取數據
- ????data[sym]?=?web.DataReader(sym,data_source?=?'yahoo')['Close']
- data?=?data.dropna()#丟棄缺失數據
- dax?=?pd.DataFrame(data.pop('^GDAXI'))#將指數數據單獨拿出來,采用pop在獲取的時候已經從原來的地方刪除了這一列數據了
- scale_function?=?lambda?x:(x-x.mean())/x.std()
- pca?=?KernelPCA().fit(data.apply(scale_function))#這里用到了apply函數。做PCA前,我們要對數據做標準化
- get_we?=?lambda?x:x/x.sum()
- print?get_we(pca.lambdas_)[:10]
這樣,你就可以看到前十個股票對DAX30指數的貢獻量了。
- pca?=?KernelPCA(n_components?=?1).fit(data.apply(scale_function))
- dax['PCA_1']?=pca.transform(data)
- dax.apply(scale_function).plot(figsize?=?(8,4))
- pca?=?KernelPCA(n_components?=?5).fit(data.apply(scale_function))
- weights?=?get_we(pca.lambdas_)
- dax['PCA_5']?=np.dot(pca.transform(data),weights)
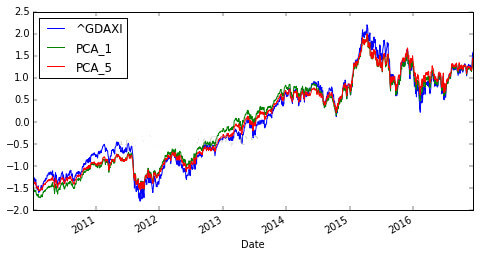

這里,我們采用只用第一個成分去擬合以及前五個成分去擬合,發現效果好的出奇。這樣我們就做到了降維的工作了。我們再來展開看一下PCA的效果。
- plt.figure(figsize?=?(8,4))
- plt.scatter(dax['PCA_5'],dax['^GDAXI'],color?=?'r')
這里,我們把PCA后的值與原始值進行散點圖的繪制,
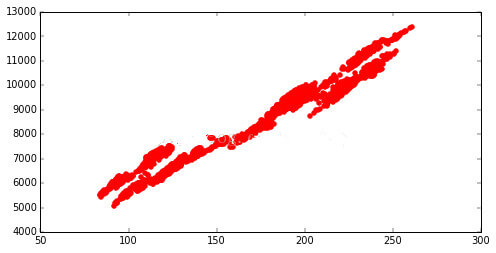
咱們看到,全體效果還是不錯的,但是很顯然,兩頭和中心老是有點疑問,所以,假如咱們要進步,咱們能夠在中心分段進行PCA,這樣的話,效果應該會更加好。