

大數據求職必看:經典的大數據面試問題
在開始之前,首先要確定的一個問題:什么是大數據?
大數據(big data,mega data),或稱巨量資料,指的是需求新處理形式才干具有更強的決議計劃力、洞察力和流程優化能力的海量、高增長率和多元化的信息財物。 在維克托·邁爾-舍恩伯格及肯尼斯·庫克耶編寫的《大數據年代》中大數據指不必隨機剖析法(抽樣調查)這么的捷徑,而選用一切數據進行剖析處理。大數據的4V特點:Volume(很多)、Velocity(高速)、Variety(多樣)、Value(價值)。

給一個超過100G大小的log file,log中存著IP地址 ,設計算法找到出現次數最多的IP地址?
答:
首先看到100G的日志文件,我們的第一反應肯定是太大了,根本加載不到內存,更別說設計算法了,那么怎么辦呢?既然裝不下,我們是不是可以將其切分開來,一小部分一小部分輪流進入內存呢,答案當然是肯定的。
在這里要記住一點:但凡是大數據的問題,都可通過切分來解決它。
粗略算一下:如果我們將其分成1000個小文件,每個文件大概就是500M左右的樣子,現在計算機肯定輕輕 松松就能裝下。
那么,問題又來了,怎樣才能保證相同的IP被分到同一個文件中呢?
這里我想到的是哈希切分,使用相同的散列函數(如 BKDRHash)將所有IP地址轉換為一個整數key,再利用 index=key%1000就可將相同IP分到同一個文件。
依次將這1000個文件讀入內存,出現次數最多的IP進行統計。
最后,在1000個出現次數最多的IP中找出最大的出現次數即為所求。
用到的散列函數:
與上題條件相同,如何找到TOP K的IP?
答:
這倒題說白了就是找前K個出現次數最多的IP,即降序排列IP出現的次數。
與上題類似,我們用哈希切分對分割的第一個個小文件中出現最多的前K個IP建小堆,
然后讀入第二個文件,將其出現次數最多的前K個IP與 堆中數據進行對比,
如果包含大于堆中的IP出現次數,則更新小堆,替換原堆中次數的出現少的數據
再讀入第三個文件,以此類推……
直到1000個文件全部讀完,堆中出現的K個IP即是出現 次數最多的前K個IP地址。
給定100億個整數,設計算法找到只出現一次的整數 ?
答:
看到此題目,我的第一反應就是估算其占用內存的大小:100億個int,一個int4個字節,100億*4=400億字節
又因為42億字節約等于4G,所以100億個整數大概占用的內存為40G,一次加載到內存顯然是不太現實的。
反過來想,所有整數所能表示的范圍為2^32,即16G, 故給出的數據有很多數據是重復的。
解法1:哈希切分
與第一題類似,用哈希切分將這些數據分到100個文件 中,每個文件大約400M,將每一個文件依次加載到內存中,利用哈希表統計出現一次的整數,將100個文件中出現一次的整數匯總起來即為所求。
解法2:位圖變形
我們知道,位圖是利用每一位來表示一個整數是否存在來節省空間,1表示存在,0表示不存在。
而上題對于所有整數而言,卻有三種狀態:不存在、 存在一次、存在多次。
故此,我們需要對傳統位圖進行擴展,用兩位來表示一個整數的狀態:00表示不存在、01表示存在一次, 10表示存在多次,11表示無效狀態。
按照上述表示,兩位表示一個整數狀態,所有整數只需要1G即可表示其存在與否。
解法3:
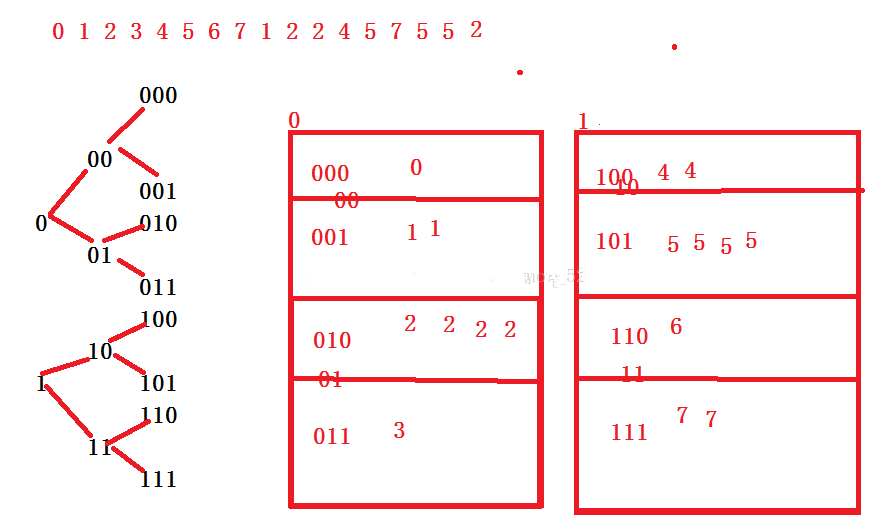
眾所周知,一個整數占32位,那么我們可對每一位按照0和1將其分為兩個文件,直到劃分到最低位,如果被分的文件中哪個文件只包含一個數據,那么,此數據即為只出現一次的整數。
如下圖:
給兩個文件,分別有100億個整數,我們只有1G內存 ,如何找到兩個文件交集?
答:100億*4字節 = 400億字節 = 40G
解法1:普通查找
將其中的一個文件分為100個小文件,每一份占400M, 將每一小份輪流加到內存中,與第二個文件中的數據進行對比,找到交集。此種算 法時間復雜度為O(N*N)。
解法2:哈希切分
對兩個文件分別進行哈希切分,將其分為100個小文件 ,index=key%100(index為文件下標)。
將兩個文件中下標相同的小文件進行對比,找出其交集。將100個文件的交集匯總起來即為所給文件的文件交集 。此種算法時間復雜度為O(N)。
解法3:位圖
我們知道,位圖中的每一位就可代表一個整數的存在與否,而16G的整數用位圖512M即可表示,將第一個文件中的整數映射到位圖中去拿第二個文件中的數字到第一個文件映射的位圖中去對比,相同數字存在即為交集。此種算法時間復雜度為O(N)。
注意:重復出現的數字交集中只會出現一次。
位圖的簡單模擬:
運行結果:
1個文件有100億個int,1G內存,設計算法找到出現次數不超過兩次的所有整數?
答:
此題思路類似第三題。
解法1:哈希切分
與第一題類似,用哈希切分將這些數據分到100個文件中,每個文件大約400M,
將每一個文件依次加載到內存中,利用哈希表統計出現不超過兩次的整數
將100個文件中出現不超過兩次的整數匯總起來即為所求。
解法2:位圖變形
我們知道,位圖是利用每一位來表示一個整數是否存在來節省空間,1表示存在,0表示不存在。
而上題對于所有整數而言,卻有三種狀態:不存在、 ?存在一次、存在多次。
故此,我們需要對傳統位圖進行擴展,用兩位來表示一個整數的狀態:00表示不存在、
01表示存在一次, ?10表示存在兩次,11表示出現超過兩次。
按照上述表示,兩位表示一個整數狀態,所有整數只需要1G即可表示其存在次數。
給兩個文件,分別有100億個query,我們只有1G內存,如何找到兩個文件交集?分別給出精確算法和近似算法。
答:
這道題思路類似于第四題:100億*4字節 = 400億字節 = 40G。
精確算法:哈希切分
對兩個文件分別進行哈希切分,使用相同的散列函數 (如 BKDRHash散列函數)將所有query轉換為一個整數key ,再利用 index=key%1000就可將相同query分到同一 個文件。(index為文件下標)
將兩個文件中下標相同的小文件進行對比,找出其交集。
將100個文件的交集匯總起來即為所給文件的文件交集 。此種算法時間復雜度為O(N)。
近似算法:布隆過濾器
首先使用相同的散列函數(如?BKDRHash散列函數)將所有 query轉換為一個整數key,
又因為布隆過濾器中的每 一位就可代表一個整數的存在 與否,而16G的整數用位圖512M即可表示,
將第一個文件中的整數映射到位圖中去,
拿第二個文件中的數字到第一個文件映射的位圖中去對比,相同數字存在即為交集。
此種算法時間復雜度為O(N)。
注意:布隆過濾器判斷不存在是確定的,而存存在在可能導致誤判,所以稱近似算法。
布隆過濾器的簡單模擬:
各種不同的散列函數:
布隆過濾器:
測試函數:
運行結果:
如何擴展BloomFilter使得它支持刪除元素的操作?
答:
因為一個布隆過濾器的key對應多個為位,沖突的概率比較大,所以不支持刪除,因為刪除有可能影響到其他元素。如果要對其元素進行刪除,就不得不對每一個位進行引用計數,同下題。
如何擴展BloomFilter使得它支持計數的操作?
答:
我們都知道,位圖非常的節省空間,但由于每一位都要引入一個int,所以空間浪費還是比較嚴重的, 因此不得不放棄位圖了,代碼如下:
給上千個文件,每一個文件大小為1K-100M,給n個單 詞,設計算法對每個詞找到所有包含它的文件,你只 有100K內存。
答:
對上千個文件生成1000個布隆過濾器,并將1000個布隆過濾器存入一個文件中,將內存分為兩份,一份用來讀取布隆過濾器中的詞,一份用來讀取文件, 直到每個布隆過濾器讀完為止。
用一個文件info 準備用來保存n個詞和包含其的文件信息。
首先把n個詞分成x份。對每一份用生成一個布隆過濾器(因為對n個詞只生成一個布隆過濾器,內存可能不夠用)。把生成的所有布隆過濾器存入外存 的一個文件Filter中。
將內存分為兩塊緩沖區,一塊用于每次讀入一個 布隆過濾器,一個用于讀文件(讀文件這個緩沖區使用 相當于有界生產者消費者問題模型來實現同步),大文 件可以分為更小的文件,但需要存儲大文件的標示信 息(如這個小文件是哪個大文件的)。
對讀入的每一個單詞用內存中的布隆過濾器來判 斷是否包含這個值,如果不包含,從Filter文件中讀 取下一個布隆過濾器到內存,直到包含或遍歷完所有 布隆過濾器。如果包含,更新info 文件。直到處理完 所有數據。刪除Filter文件。
有一個詞典,包含N個英文單詞,現在任意給一個字符串,設計算法找出包含這個字符串的所有英文單詞。
答:
對于這道題目,我們要用到一種特殊的數據結構----字典樹來解決它,所謂字典樹,又稱單詞查找樹(或Trie樹),是一種哈希樹的變種。
典型應用:用于統計、排序和保存大量的字符串,經 常被搜索引擎系統用于文本詞頻統計。
優點:利用字符串的公共前綴來減少查詢時間,最大 限度地減少無謂的字符串比較,查詢效率高于哈希表 。
基本性質:根節點不包含字符,除根節點外每個節點 都只包含一個字符;
從根節點到某一節點,路徑上所有經過的字符連接起來,為該節點對應的字符串;
每個節點的所有子節點包含的字符都不相同 。
應用:串的快速檢索、串排序、最長公共前綴
解法如下:
用給出的N個單詞建立一棵與上述字典樹不同的字典樹 ,用任意字符串與字典樹中的每個節點中的單詞進行 比較,在每層中查找與任意字符串首字母一樣的,找到則遍歷其下面的子樹,找第二個字母,以此類推, 如果與任意字符串的字符全部相同,則算找到。
如下圖: