

吐血整理:一份不可多得的架構師圖譜!
一個技術圖譜:
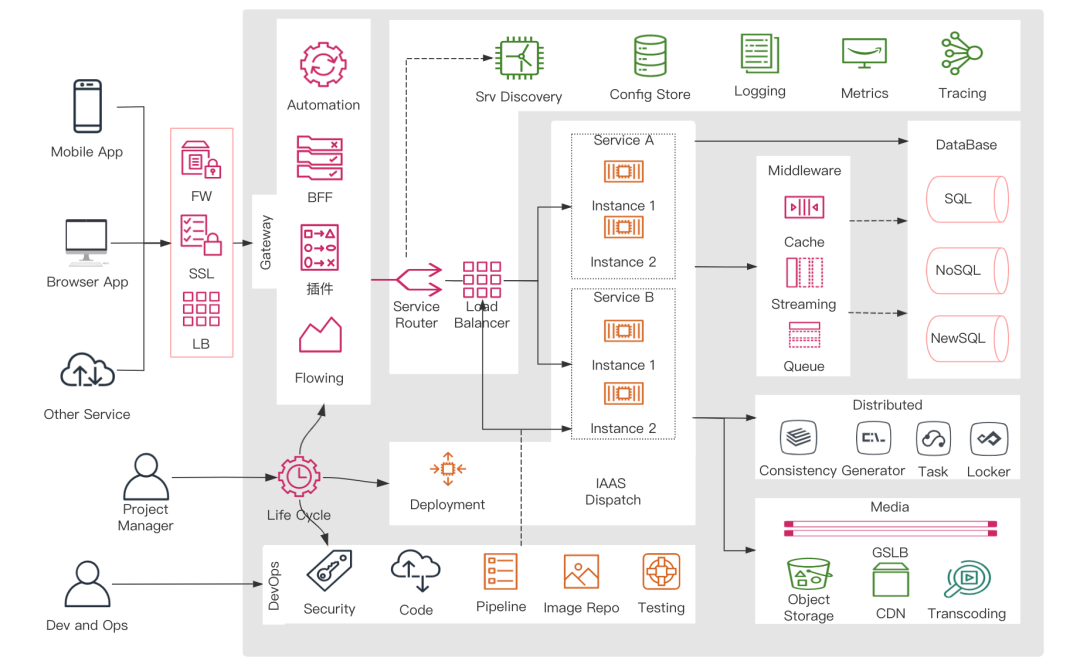

完整的思維導圖:
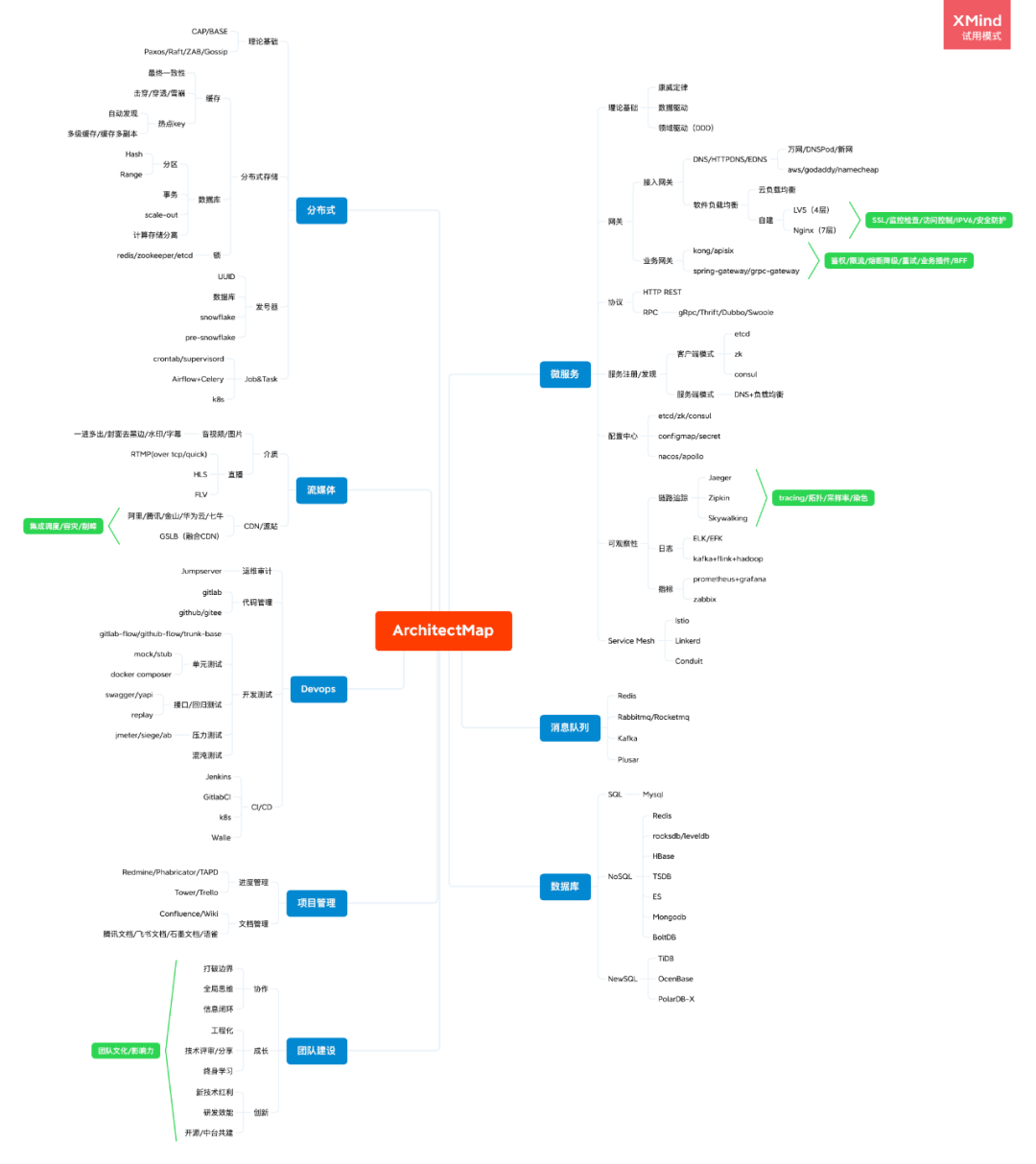
| 理論基礎
在康威的這篇文章中,最有名的一句話就是:
Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations.
-
組織溝通方式決定系統設計,對于復雜的系統,聊設計就離不開聊人與人的溝通,解決好人與人的溝通問題,才能有一個好的系統設計 -
時間再多一件事情也不可能做的完美,但總有時間做完一件事情,這與架構設計的“簡單、合適、演化”思維不謀而合 -
線型系統和線型組織架構間有潛在的異質同態特征,更直白的說,你想要什么樣的系統,就搭建什么樣的團隊,定義好系統的邊界和接口,團隊內應該是自治的,這樣將溝通成本維持在系統內部,每個子系統就會更加內聚 -
大的系統組織總是比小系統更傾向于分解,面對復雜的系統及組織,往往可以采用分而治之
-
根據需求劃分出初步的領域和限界上下文,以及上下文之間的關系 -
進一步分析每個上下文內部,識別出哪些是實體,哪些是值對象 -
對實體、值對象進行關聯和聚合,劃分出聚合的范疇和聚合根 -
為聚合根設計倉儲,并思考實體或值對象的創建方式 -
在工程中實踐領域模型,并在實踐中檢驗模型的合理性,倒推模型中不足的地方并重構
| 網關
-
安全防護目的是保護服務數據以及可用性,例如防范常見的 DDOS/CC 網絡攻擊,反爬蟲,自定義訪問控制,自研成本往往比較高,可以借助云上一系列的高防、防火墻服務。 -
SSL(TLS)用來提供外部 https 訪問,https 可以防止數據在傳輸過程中不被竊取、改變,確保數據的完整性,在支付或者用戶登錄等敏感數據場景,可以起到一定的保護作用,同時 https 頁面對搜索引擎也比較友好。 -
IPV6,全球 43 億 IPV4 地址已經在 2019 年年底耗盡,網信辦在 2018 年開始就已經推行各大運營商、CDN 廠商、互聯網核心產品支持 IPV6,我們公司之前也是試點之一。IPV6 的支持只需要增加一條“AAAA”DNS記錄,將域名解析到自持 IPV6 的 IP/VIP 即可。IPV4 到 IPV6 由于存在兼容性等問題,一定是長期共存的,過渡方案可以采用 IPV6 代理(IPV6 代理轉發到 IPV4 服務)或者雙棧(同時支持 IPV6 和 IPV4)。
業務網關:
| 協議
-
更清晰的 API 定義,例如 gRPC 協議的定義文件 proto,自身就可以作為很好的 API 文檔,日常開發中也可以把 proto 文件獨立版本庫管理,精簡目錄結構,方便不同的服務引用。 -
更好的傳輸效率,通過序列化和反序列化進一步壓縮網絡傳輸數據,不過序列化、反序列化也會有一定的性能損耗,protobuf 可以說很好的兼顧了這兩點。 -
更合適的容錯機制,可以基于實際的業務場景,實現更合適的超時控制與異常重試機制,以應對網絡抖動等對服務造成的影響。
| 服務注冊/發現
從實現方式上可以分為服務端模式與客戶端模式:
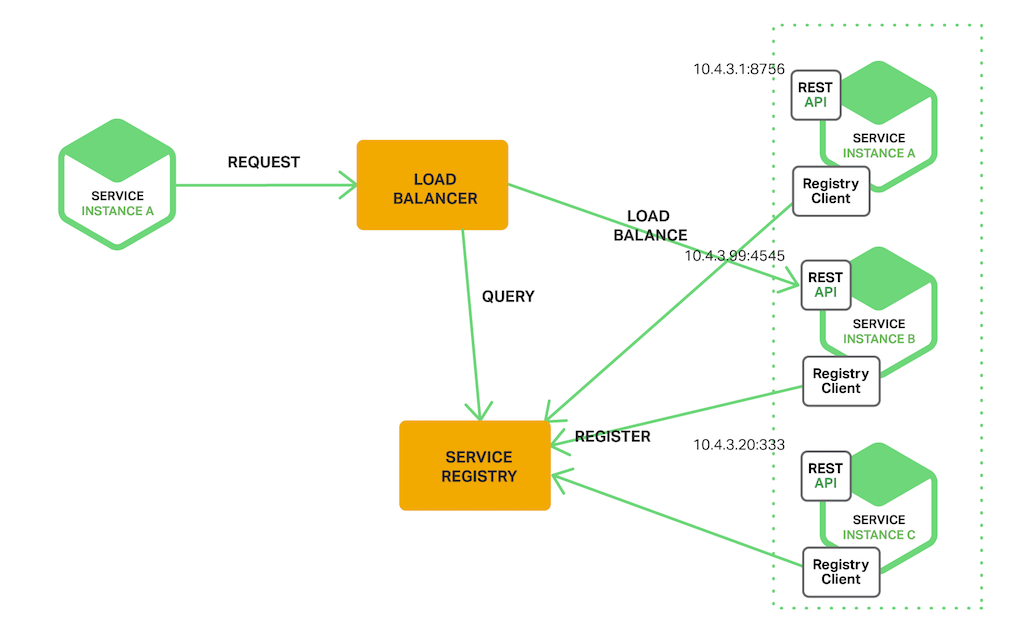
服務端模式:也可以說是傳統模式,通過借助負載均衡器和 DNS 實現,負載均衡器負責健康檢查、負載均衡策略,DNS 負責實現訪問域名到負載均衡器 IP/VIP 的映射。通過直接暴露域名和端口的方式提供客戶端訪問。
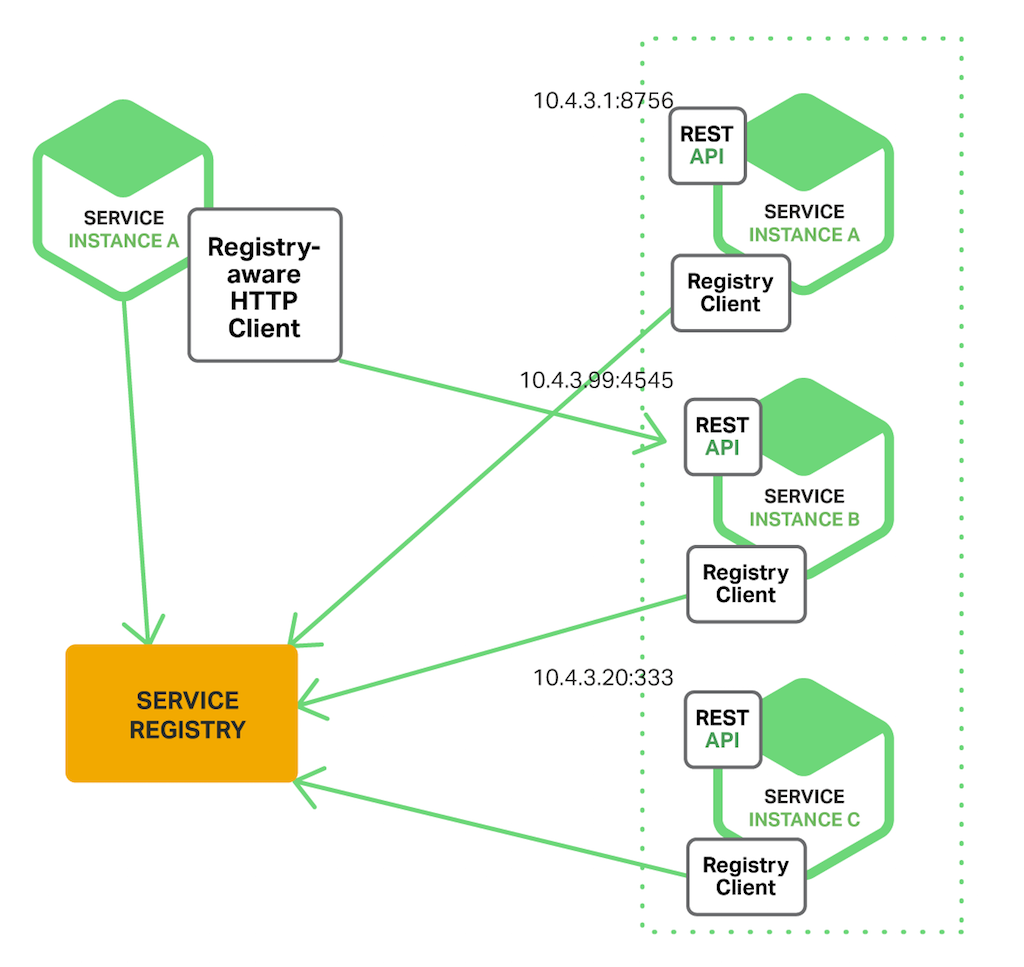
客戶端模式:可以借助注冊中心實現,注冊中心負責服務的注冊與健康檢查,客戶端通過監聽配置變更的方式及時把配置中心維護的配置同步到本地,通過客戶端負載均衡策略直接向后端機器發起請求。
Consul 提供開箱即用的功能,etcd 社區和接入易用性方面更優一些,他們之間的一些具體區別:
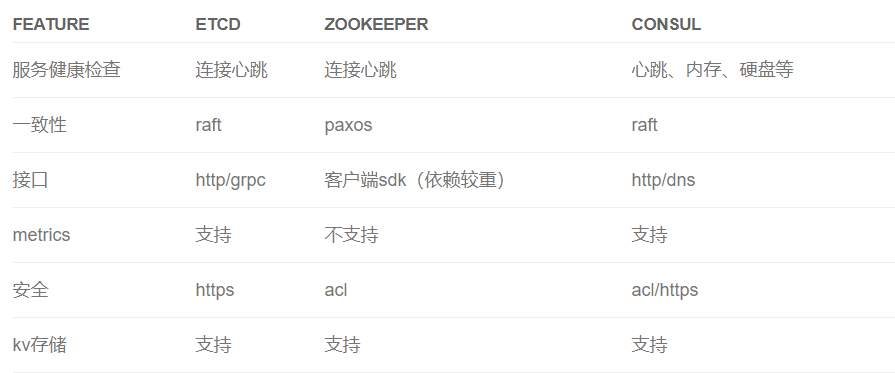
|?配置中心
| 可觀察性
很長一段時間,這三者是獨立存在的,隨著時間的推移,這三者已經相互關聯,相輔相成。
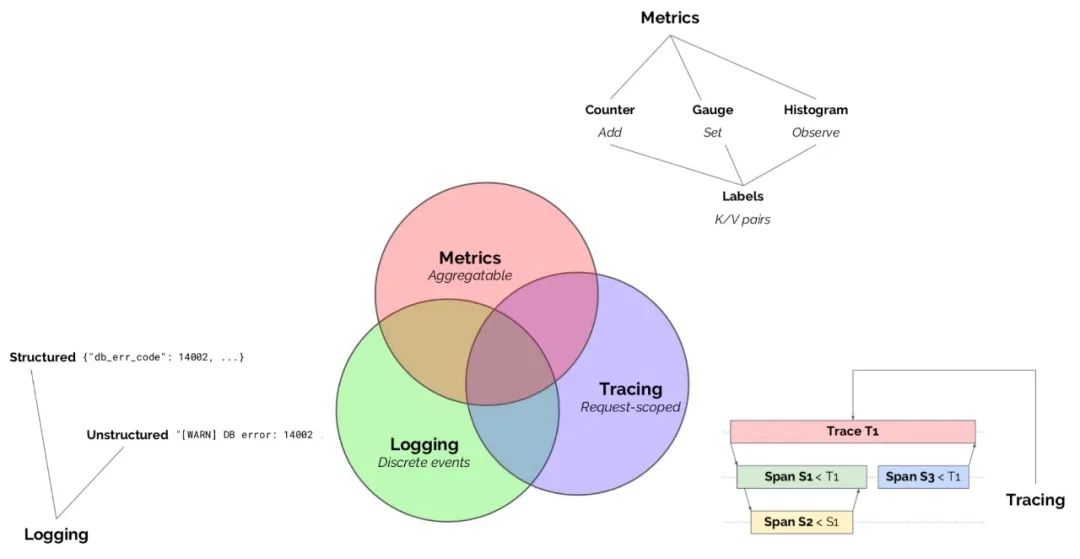
為了解決不同的分布式系統 API 不兼容的問題,誕生了 OpenTracing 規范,OpenTracing 中的 Trace 可以被認為是由多個 Spacn 組成的 DAG 圖。
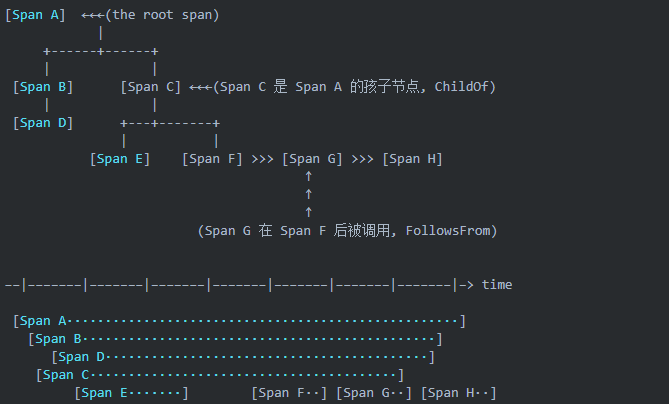
OpenTracing 中的佼佼者當屬 Jaeger、Zipkin、Skywalking。他們之間的一些對比:
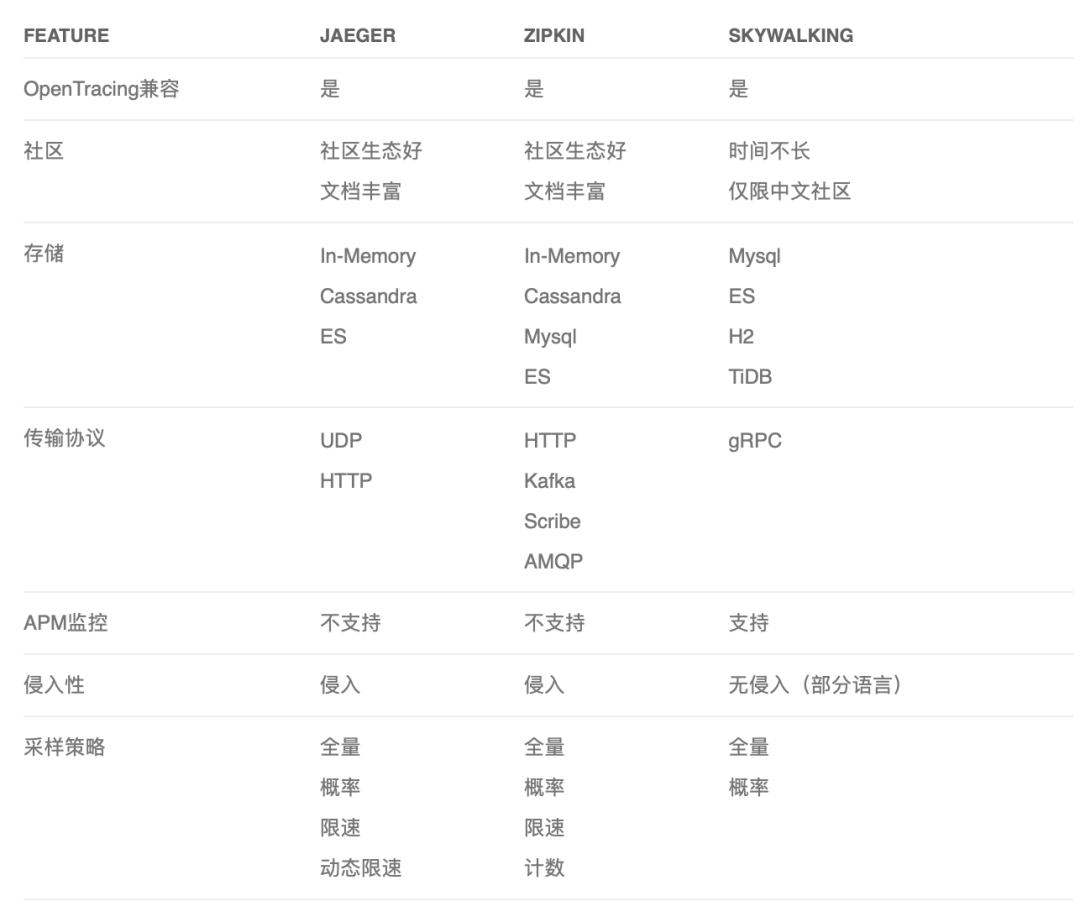
-
Emergency:system is unusable -
Alert:action must be taken immediately -
Critical:critical conditions -
Error:error conditions -
Warning:warning conditions -
Notice:normal but significant condition -
Informational:informational messages -
Debug:debug-level messages
-
資源監控:CPU、內存、IO、fd、GC等 -
業務監控:QPS、模調、耗時分布等
-
Counter 只增不減的計數器,例如請求數(http_requests_total)。基于此數據模型,使用 Prometheus 提供的強大 PromQL 表達式能夠拓展出更加適合開發觀察的指標數據。分鐘增量請求:increase(http_requests_total[1m]) 分鐘 QPS:rate(http_requests_total[1m]) -
Gauge 可增可減的時刻量,例如 Go 語言協程數(go_goroutines) 波動量:delta(go_goroutines[10m]) -
Histogram 直方圖,不同區間內樣本的個數。例如,耗時 50ms-100ms 每分鐘請求量,100ms-150ms 每分鐘請求量。 -
Summary 概要,反應百分位值。例如,某 RPC 接口,95% 的請求耗時低于 150ms,99% 的請求耗時低于 200ms。
Prometheus 指標支持 pull 和 push 模式:
- Pull:服務暴露 metrics 接口,指標內存更新,Prometheus server 定時拉取,性能更好,但要考慮易失性
- Push:指標推送 push-gateway,Promethus server 從 gateway 拉取,適用瞬時業務場景(定時任務)
| Service Mesh
我們前邊講的服務發現、熔斷降級、安全、流量控制、可觀察性等能力。這些通用能力在 Service Mesh 出現之前,由 Lib/Framework 通過一些切面的方式完成,這樣就可以在開發層面上很容易地集成到我們的應用服務中。
但是并沒有辦法實現跨語言編程,有什么改動后,也需要重新編譯重新發布服務。理論上應該有一個專門的層來干這事,于是出現了 Sidecar。
第一代 Service Mesh,像 Linkerd,后邊又出現了第二代 Service Mesh,Istio,職責分明,分離出處數據面和控制面。
但是 Sidecar 作為代理層,避免不了性能損耗(CPU 序列化反序列化 UDS),所以 proxyless service mesh 重新被提起,和之前的 「RPC + 服務發現治理」區別是啥?
感覺這個名詞營銷味道略重。其實不能簡單的 “Proxyless Service Mesh” 理解為 “一個簡單的 RPC 框架,暴露了幾個超時參數到配置中心來控制”,它重在統一協議、API。
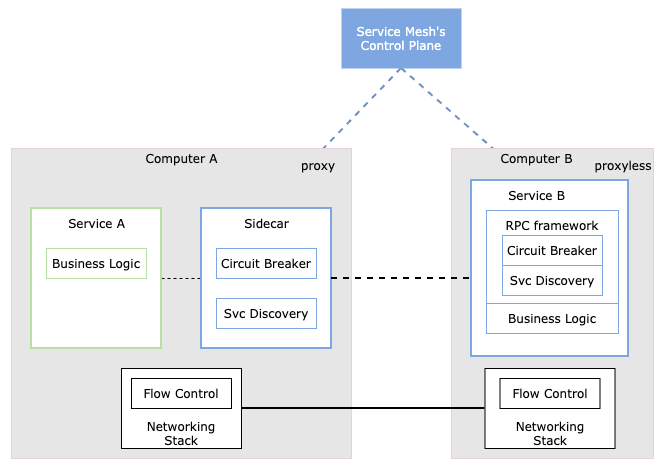

這些現實的問題還擺在面前,我覺得這也是屬于技術進化的一種趨勢,當一項技術足夠成熟的時候,又回衍生出新的復雜度問題,從而又需要發展出新技術解決。
也就是說:消息的發送者和接收者不需要同時與消息隊列交互。消息會保存在隊列中,直到接收者取回它。
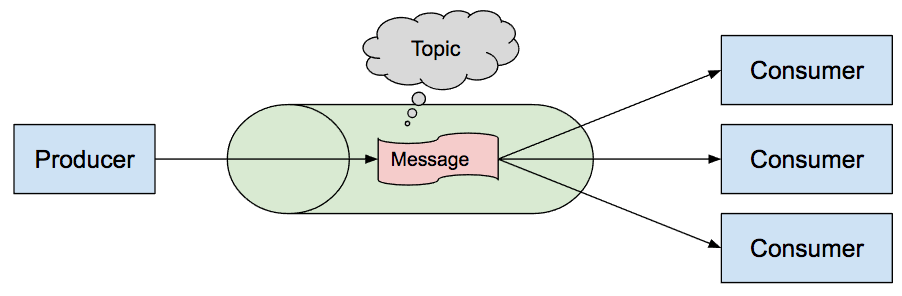
-
HA:自身的高可用性保障,避免消息隊列的引入而影響整體服務的可用性 -
高吞吐:在面對海量數據寫入能否保持一個相對穩定、高效的數據處理能力 -
功能豐富性:是否支持延遲消息、事務消息、死信隊列、優先級隊列等 -
消息廣播:是否支持將消息廣播給消費者組或者一組消費者 -
消息堆積能力:在數據量過大時,是否允許一定消息堆積到broker -
數據持久性:數據持久化策略的采用,也決定著數據在宕機恢復后是否會丟失數據 -
重復消費:是否支持ack機制,在消費者未正確處理消息時,支持重新消費 -
消息順序性:針對順序消費的場景保證數據按寫入時間的順序性
| Redis
-
功能豐富性:只支持普通的消息類型 -
數據持久性:Pub/Sub 只提供緩沖區廣播能力,不進行持久化,List/Stream 即使基于 aof 和 rdb 持久化策略,但是并沒有事務性保障,在宕機恢復后還是存在丟失數據的可能性 -
消息堆積能力:List 隨長度增大,內存不斷增長;Pub/Sub 只在緩沖區內堆積,緩沖區滿消費者強制下線;Stream 創建時可以指定隊列最大長度,寫滿后剔除舊消息
| RabbitMQ vs Kafka vs RocketMQ
| Pulsar
設計上避免了 Kafka 遇到的功能豐富性、擴容等方面的問題,采用計算、存儲分離的架構,broker 層只作為“API 接口層”,存儲交給更專業的 bookeeper,由于 broker 層的無狀態性,結合 Kubernetes 等非常方便的進行擴容。
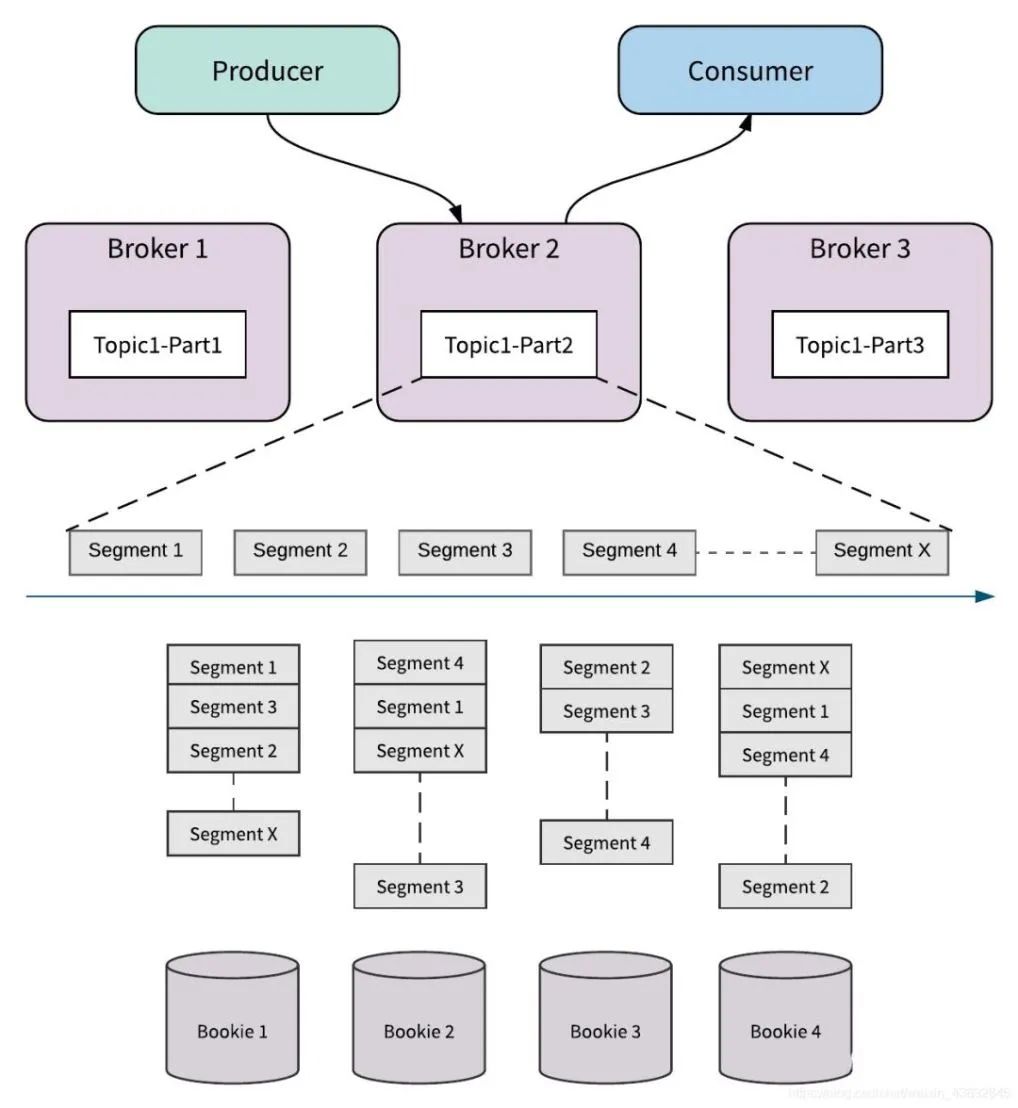
-
HA、高吞吐:和 Kafka 類似,通過多 partition 和選舉機制功,除此之外,還支持豐富的跨地域復制能力 -
功能豐富性:可以支持秒級的延遲消息,以及獨特的重試隊列和私信隊列 -
消息順序性:為了實現 partition 消息的順序性,和 Kafka 一樣,都需要將消息寫入到同一 broker,區別是 Kafka 會同時存儲消息在該 broker,broker 和 partiton 綁定在一起,而 Pulsar 可以將消息分塊(segment)后,更加均勻的分散到 bookeeper 節點上,broker 只需要記錄映射關系即可,這樣在資源擴容時,可以更加快速便捷
文章來源:https://c1n.cn/J3wve 轉自:幽鬼,侵刪