

linux教程 | 如何在 Linux Web 服務(wù)器上快速跟蹤 PDF 訪問(wèn)
是否可以跟蹤您網(wǎng)站的用戶點(diǎn)擊下載 PDF 或 JPG 等二進(jìn)制文件的次數(shù)?對(duì)的,這是可能的。這簡(jiǎn)單嗎?我原本不這么認(rèn)為。我錯(cuò)了。
這個(gè)故事開(kāi)始于我在我的Bootstrap IT 網(wǎng)站上優(yōu)化我的新書(shū)的登陸頁(yè)面,保持最新:你不能錯(cuò)過(guò)的所有重大技術(shù)趨勢(shì)的背景資料。
我想提供對(duì)本書(shū)示例章節(jié)的 PDF 文件的訪問(wèn)。但我也想知道有多少人實(shí)際下載了它。
現(xiàn)在讓我們退后一步。Google Analytics是一項(xiàng)免費(fèi)服務(wù),它使用插入到您的 HTML 文件中的代碼片段來(lái)收集和顯示有關(guān)您的文件被訪問(wèn)頻率的數(shù)據(jù)。
Google Analytics 的魔力和問(wèn)題在于可以透露多少有關(guān)用戶的信息。我在 Keeping Up 書(shū)中討論了與該服務(wù)相關(guān)的一些隱私問(wèn)題。我還提到了我自己在自己的網(wǎng)站上使用該服務(wù)時(shí)至少感到有點(diǎn)內(nèi)疚。
無(wú)論如何,谷歌分析本身并不能告訴你很多關(guān)于你的基于網(wǎng)絡(luò)的 PDF 是如何被使用的。當(dāng)然,有一些技巧可以解決這個(gè)問(wèn)題。
傳統(tǒng)方法包括設(shè)置Google 跟蹤代碼管理器、自定義您使用的請(qǐng)求 URL 的語(yǔ)法,或者,如果您的網(wǎng)站使用 WordPress 軟件,則使用Monster Insights 插件。這些都可以工作,但需要相當(dāng)陡峭的學(xué)習(xí)曲線。
但我是 Linux 系統(tǒng)管理員。而且,正如我經(jīng)常提醒我周圍的人一樣,最好的系統(tǒng)管理員是懶惰的。學(xué)習(xí)曲線?這聽(tīng)起來(lái)有點(diǎn)像工作。不會(huì)發(fā)生在我的手表上。
所以這是交易。顯然,我的 Web 服務(wù)器運(yùn)行 Linux。而且,在底層,HTTP 流量由 Apache 處理。這意味著在我的網(wǎng)站上發(fā)生的所有事情都將由 Apache 記錄。
一切。只需要從我的本地工作站運(yùn)行一行 Bash,就可以讓我了解我的 PDF 示例章節(jié)的內(nèi)容:
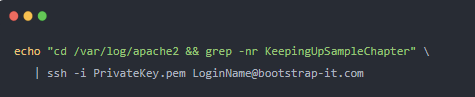

讓我們分解一下。引號(hào) (?cd /var/log/apache2) 中的兩個(gè)命令中的第一個(gè)會(huì)將我們移動(dòng)到 Linux 服務(wù)器上的 /var/log/apache2/ 目錄,Apache 將在該目錄中寫(xiě)入其日志。那不是火箭科學(xué)。
該目錄中將有多個(gè)感興趣的文件。這是因?yàn)榕c常規(guī)訪問(wèn)和錯(cuò)誤相關(guān)的消息被保存到不同的文件中,并且因?yàn)槲募啌Q策略意味著這些文件中的任何一個(gè)都可能有多個(gè)版本。因此,我將使用grep在所有未壓縮文件中搜索該KeepingUpSampleChapter字符串。KeepingUpSampleChapter當(dāng)然,它是 PDF 文件名的一部分。
然后我將該命令通過(guò)管道傳輸?shù)?SSH,SSH 將連接到我的遠(yuǎn)程服務(wù)器并執(zhí)行該命令。這是成功運(yùn)行后單個(gè)條目的外觀(出于隱私考慮,我刪除了請(qǐng)求者的 IP 地址):
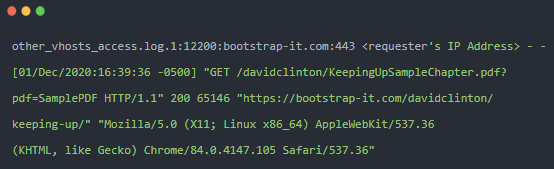
我們可以看到:
- 出現(xiàn)條目的日志文件 (?
other_vhosts_access.log.1) - 請(qǐng)求者的 IP 地址(已編輯)
- 時(shí)間戳告訴我們文件被訪問(wèn)的確切時(shí)間
- 文件在服務(wù)器文件系統(tǒng)上的相對(duì)位置 (?
/davidclinton/KeepingUpSampleChapter.pdf) - 發(fā)出請(qǐng)求的 URL (?
https://bootstrap-it.com/davidclinton/keeping-up/) - 以及用戶正在運(yùn)行的瀏覽器
這是很多信息。如果我們只是想知道文件被下載了多少次,我們可以簡(jiǎn)單地將輸出通過(guò)管道傳遞給wc命令,該命令將告訴我們關(guān)于輸出的三件事:行數(shù)、單詞數(shù)和包含的字符數(shù)。該命令如下所示:

這種方法有一個(gè)可能的限制。如果您的網(wǎng)站很忙,日志文件會(huì)頻繁翻轉(zhuǎn),通常一天超過(guò)一次。默認(rèn)情況下,第一次翻轉(zhuǎn)后,文件使用gz算法壓縮,無(wú)法讀取grep。
該zgrep命令處理此類文件不會(huì)有任何問(wèn)題,但該過(guò)程最終可能需要很長(zhǎng)時(shí)間。您可能會(huì)考慮編寫(xiě)一個(gè)簡(jiǎn)單的自定義腳本來(lái)解壓縮每個(gè)gz文件,然后grep對(duì)其內(nèi)容進(jìn)行常規(guī)運(yùn)行。那將是你的項(xiàng)目。
在我的bootstrap-it.com上以書(shū)籍、課程和文章的形式提供了更多的管理優(yōu)勢(shì)。
原文:https://www.freecodecamp.org/news/quickly-track-pdf-access-linux-web-server/