

自從上了 Prometheus,睡覺也踏實了!
背景
概念:Instance、Job、Metric、Metric Name、Metric Label、Metric Value、Metric Type(Counter、Gauge、Histogram、Summary)、DataType(Instant Vector、Range Vector、Scalar、String)、Operator、Function
日常監控
假設需要監控 WebServerA 每個API的請求量為例,需要監控的維度包括:服務名(job)、實例IP(instance)、API名(handler)、方法(method)、返回碼(code)、請求量(value)。
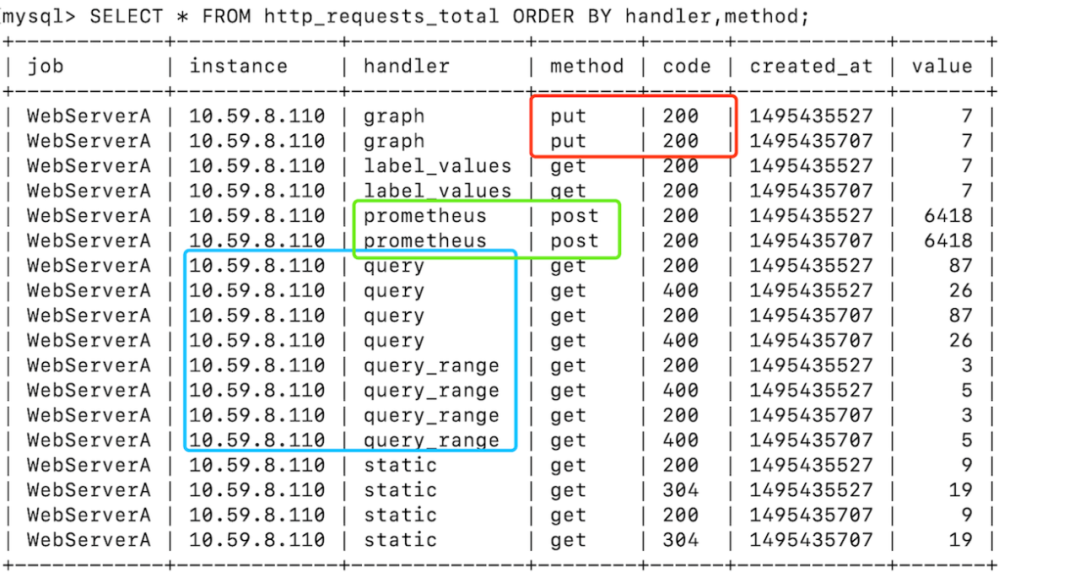

如果以SQL為例,演示常見的查詢操作:
查詢 method=put 且 code=200 的請求量(紅框)

查詢 handler=prometheus 且 method=post 的請求量(綠框)

查詢 instance=10.59.8.110 且 handler 以 query 開頭 的請求量(綠框)

通過以上示例可以看出,在常用查詢和統計方面,日常監控多用于根據監控的維度進行查詢與時間進行組合查詢。如果監控100個服務,平均每個服務部署10個實例,每個服務有20個API,4個方法,30秒收集一次數據,保留60天。那么總數據條數為:100(服務) 10(實例) 20(API) 4(方法) 86400(1天秒數)* 60(天) / 30(秒)= 138.24 億條數據,寫入、存儲、查詢如此量級的數據是不可能在Mysql類的關系數據庫上完成的。因此 Prometheus 使用 TSDB 作為存儲引擎。
存儲引擎
-
存儲的數據量級十分龐大 -
大部分時間都是寫入操作 -
寫入操作幾乎是順序添加,大多數時候數據到達后都以時間排序 -
寫操作很少寫入很久之前的數據,也很少更新數據。大多數情況在數據被采集到數秒或者數分鐘后就會被寫入數據庫 -
刪除操作一般為區塊刪除,選定開始的歷史時間并指定后續的區塊。很少單獨刪除某個時間或者分開的隨機時間的數據 -
基本數據大,一般超過內存大小。一般選取的只是其一小部分且沒有規律,緩存幾乎不起任何作用 -
讀操作是十分典型的升序或者降序的順序讀 -
高并發的讀操作十分常見
那么 TSDB 是怎么實現以上功能的呢?

原始數據分為兩部分 label, samples。前者記錄監控的維度(標簽:標簽值),指標名稱和標簽的可選鍵值對唯一確定一條時間序列(使用 series_id 代表);后者包含包含了時間戳(timestamp)和指標值(value)。

TSDB 使用 timeseries:doc:: 為 key 存儲 value。為了加速常見查詢查詢操作:label 和 時間范圍結合。TSDB 額外構建了三種索引:Series, Label Index 和 Time Index。
以標簽 latency 為例:
Series
存儲兩部分數據。一部分是按照字典序的排列的所有標簽鍵值對序列(series);另外一部分是時間線到數據文件的索引,按照時間窗口切割存儲數據塊記錄的具體位置信息,因此在查詢時可以快速跳過大量非查詢窗口的記錄數據
Label Index
每對 label 為會以 index:label: 為 key,存儲該標簽所有值的列表,并通過引用指向 Series 該值的起始位置。
Time Index
數據會以 index:timeseries:: 為 key,指向對應時間段的數據文件
數據計算
一次計算,處處查詢

文章轉載:DevOps技術棧
(版權歸原作者所有,侵刪)