

深入理解TLB原理
深入理解TLB原理,最近在群里討論內(nèi)存缺頁中斷問題,討論到了MMU和TLB原理相關(guān)的:
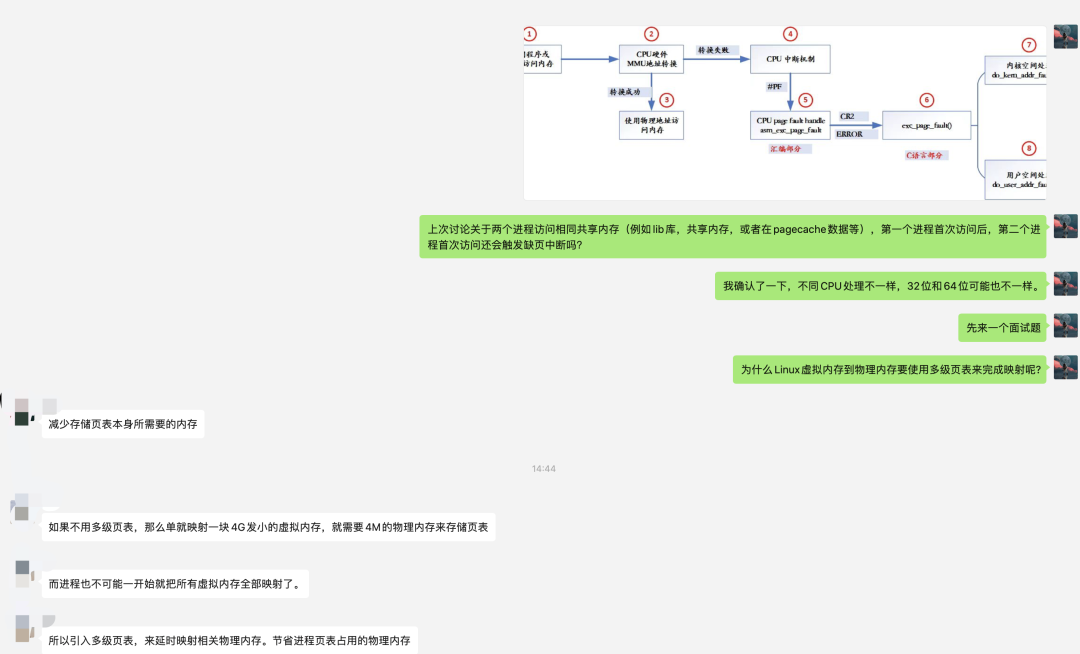


今天就分享一篇TLB的好文章,希望大家夯實基本功,讓我們一起深入理解計算機系統(tǒng)。TLB是translation lookaside buffer的簡稱。首先,我們知道MMU的作用是把虛擬地址轉(zhuǎn)換成物理地址。
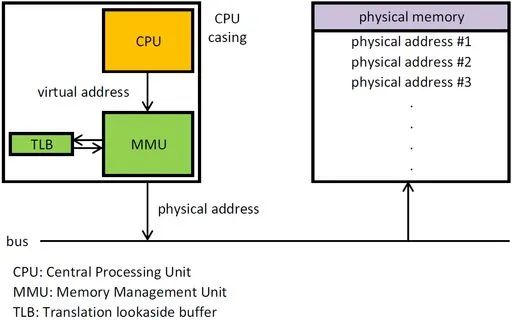
MMU工作原理
虛擬地址和物理地址的映射關(guān)系存儲在頁表中,而現(xiàn)在頁表又是分級的。64位系統(tǒng)一般都是3~5級。常見的配置是4級頁表,就以4級頁表為例說明。分別是PGD、PUD、PMD、PTE四級頁表。在硬件上會有一個叫做頁表基地址寄存器,它存儲PGD頁表的首地址。
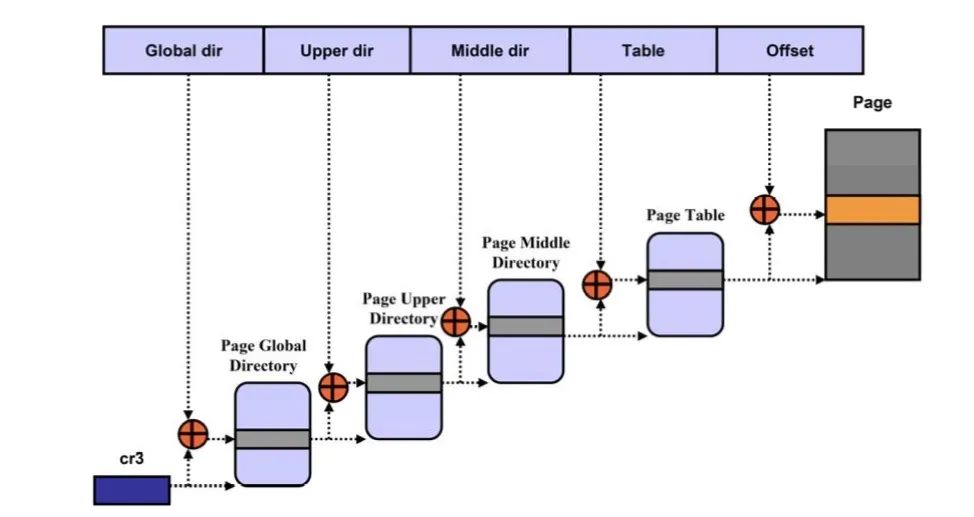
Linux分頁機制
MMU就是根據(jù)頁表基地址寄存器從PGD頁表一路查到PTE,最終找到物理地址(PTE頁表中存儲物理地址)。這就像在地圖上顯示你的家在哪一樣,我為了找到你家的地址,先確定你是中國,再確定你是某個省,繼續(xù)往下某個市,最后找到你家是一樣的原理。一級一級找下去。這個過程你也看到了,非常繁瑣。如果第一次查到你家的具體位置,我如果記下來你的姓名和你家的地址。下次查找時,是不是只需要跟我說你的姓名是什么,我就直接能夠告訴你地址,而不需要一級一級查找。四級頁表查找過程需要四次內(nèi)存訪問。延時可想而知,非常影響性能。頁表查找過程的示例如下圖所示。以后有機會詳細展開,這里了解下即可。
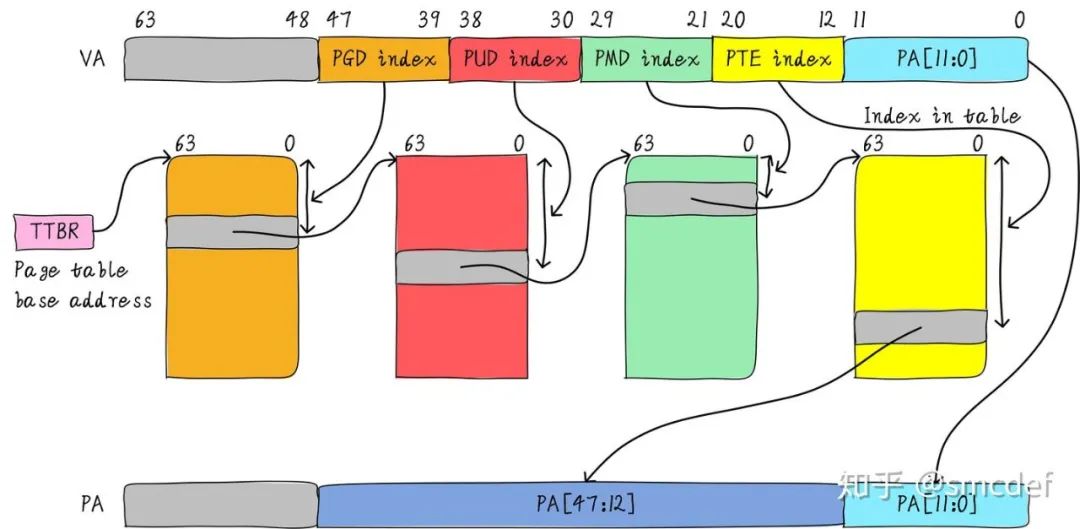
TLB的本質(zhì)是什么
TLB其實就是一塊高速緩存。數(shù)據(jù)cache緩存地址(虛擬地址或者物理地址)和數(shù)據(jù)。TLB緩存虛擬地址和其映射的物理地址。TLB根據(jù)虛擬地址查找cache,它沒得選,只能根據(jù)虛擬地址查找。所以TLB是一個虛擬高速緩存。硬件存在TLB后,虛擬地址到物理地址的轉(zhuǎn)換過程發(fā)生了變化。虛擬地址首先發(fā)往TLB確認是否命中cache,如果cache hit直接可以得到物理地址。否則,一級一級查找頁表獲取物理地址。并將虛擬地址和物理地址的映射關(guān)系緩存到TLB中。既然TLB是虛擬高速緩存(VIVT),是否存在別名和歧義問題呢?如果存在,軟件和硬件是如何配合解決這些問題呢?
TLB的特殊
虛擬地址映射物理地址的最小單位是4KB。所以TLB其實不需要存儲虛擬地址和物理地址的低12位(因為低12位是一樣的,根本沒必要存儲)。另外,我們?nèi)绻衏ache,肯定是一次性從cache中拿出整個數(shù)據(jù)。所以虛擬地址不需要offset域。index域是否需要呢?這取決于cache的組織形式。如果是全相連高速緩存。那么就不需要index。如果使用多路組相連高速緩存,依然需要index。下圖就是一個四路組相連TLB的例子。現(xiàn)如今64位CPU尋址范圍并沒有擴大到64位。64位地址空間很大,現(xiàn)如今還用不到那么大。因此硬件為了設(shè)計簡單或者解決成本,實際虛擬地址位數(shù)只使用了一部分。這里以48位地址總線為了例說明。
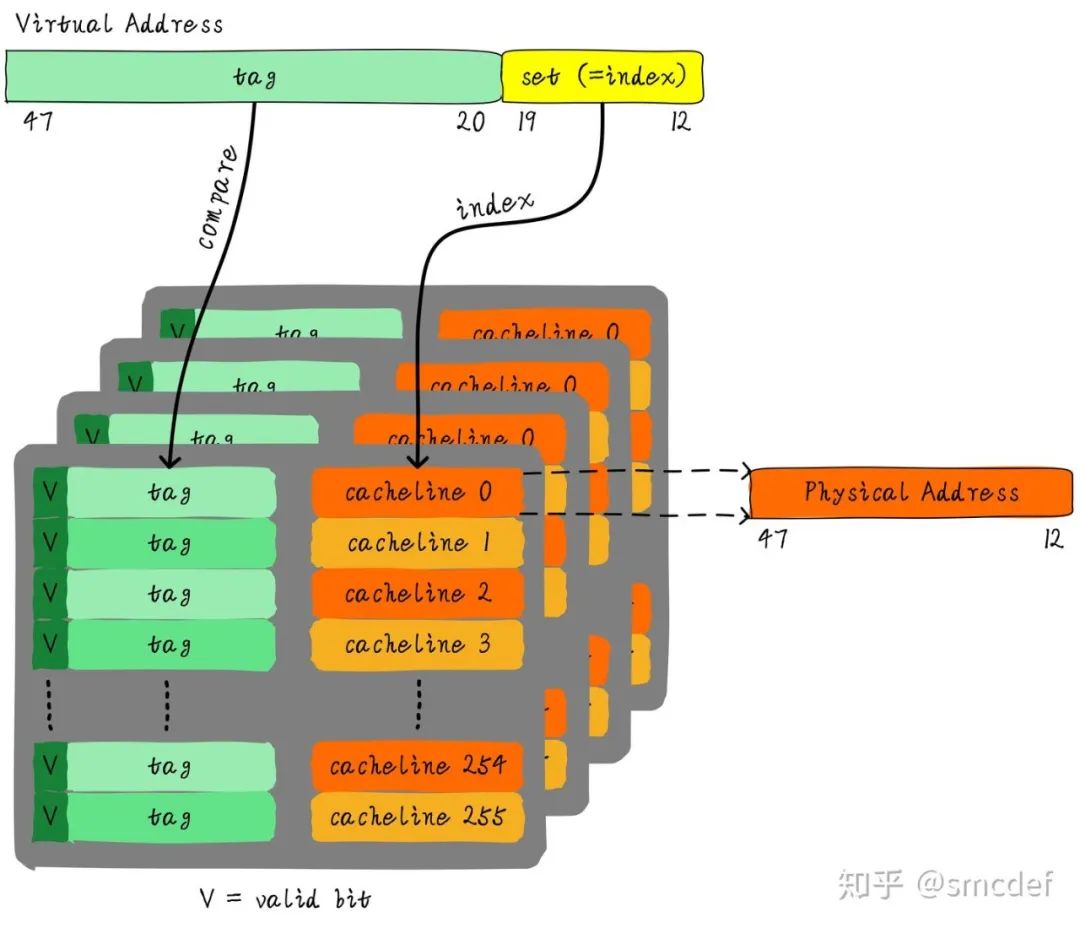
TLB的別名問題
我先來思考第一個問題,別名是否存在。我們知道PIPT的數(shù)據(jù)cache不存在別名問題。物理地址是唯一的,一個物理地址一定對應(yīng)一個數(shù)據(jù)。但是不同的物理地址可能存儲相同的數(shù)據(jù)。也就是說,物理地址對應(yīng)數(shù)據(jù)是一對一關(guān)系,反過來是多對一關(guān)系。由于TLB的特殊性,存儲的是虛擬地址和物理地址的對應(yīng)關(guān)系。因此,對于單個進程來說,同一時間一個虛擬地址對應(yīng)一個物理地址,一個物理地址可以被多個虛擬地址映射。將PIPT數(shù)據(jù)cache類比TLB,我們可以知道TLB不存在別名問題。而VIVT Cache存在別名問題,原因是VA需要轉(zhuǎn)換成PA,PA里面才存儲著數(shù)據(jù)。中間多經(jīng)傳一手,所以引入了些問題。
TLB的歧義問題
我們知道不同的進程之間看到的虛擬地址范圍是一樣的,所以多個進程下,不同進程的相同的虛擬地址可以映射不同的物理地址。這就會造成歧義問題。例如,進程A將地址0x2000映射物理地址0x4000。進程B將地址0x2000映射物理地址0x5000。當(dāng)進程A執(zhí)行的時候?qū)?x2000對應(yīng)0x4000的映射關(guān)系緩存到TLB中。當(dāng)切換B進程的時候,B進程訪問0x2000的數(shù)據(jù),會由于命中TLB從物理地址0x4000取數(shù)據(jù)。這就造成了歧義。如何消除這種歧義,我們可以借鑒VIVT數(shù)據(jù)cache的處理方式,在進程切換時將整個TLB無效。切換后的進程都不會命中TLB,但是會導(dǎo)致性能損失。
如何盡可能的避免flush TLB
首先需要說明的是,這里的flush理解成使無效的意思。我們知道進程切換的時候,為了避免歧義,我們需要主動flush整個TLB。如果我們能夠區(qū)分不同的進程的TLB表項就可以避免flush TLB。
我們知道Linux如何區(qū)分不同的進程?每個進程擁有一個獨一無二的進程ID。如果TLB在判斷是否命中的時候,除了比較tag以外,再額外比較進程ID該多好呢!這樣就可以區(qū)分不同進程的TLB表項。進程A和B雖然虛擬地址一樣,但是進程ID不一樣,自然就不會發(fā)生進程B命中進程A的TLB表項。所以,TLB添加一項ASID(Address Space ID)的匹配。ASID就類似進程ID一樣,用來區(qū)分不同進程的TLB表項。這樣在進程切換的時候就不需要flush TLB。但是仍然需要軟件管理和分配ASID。
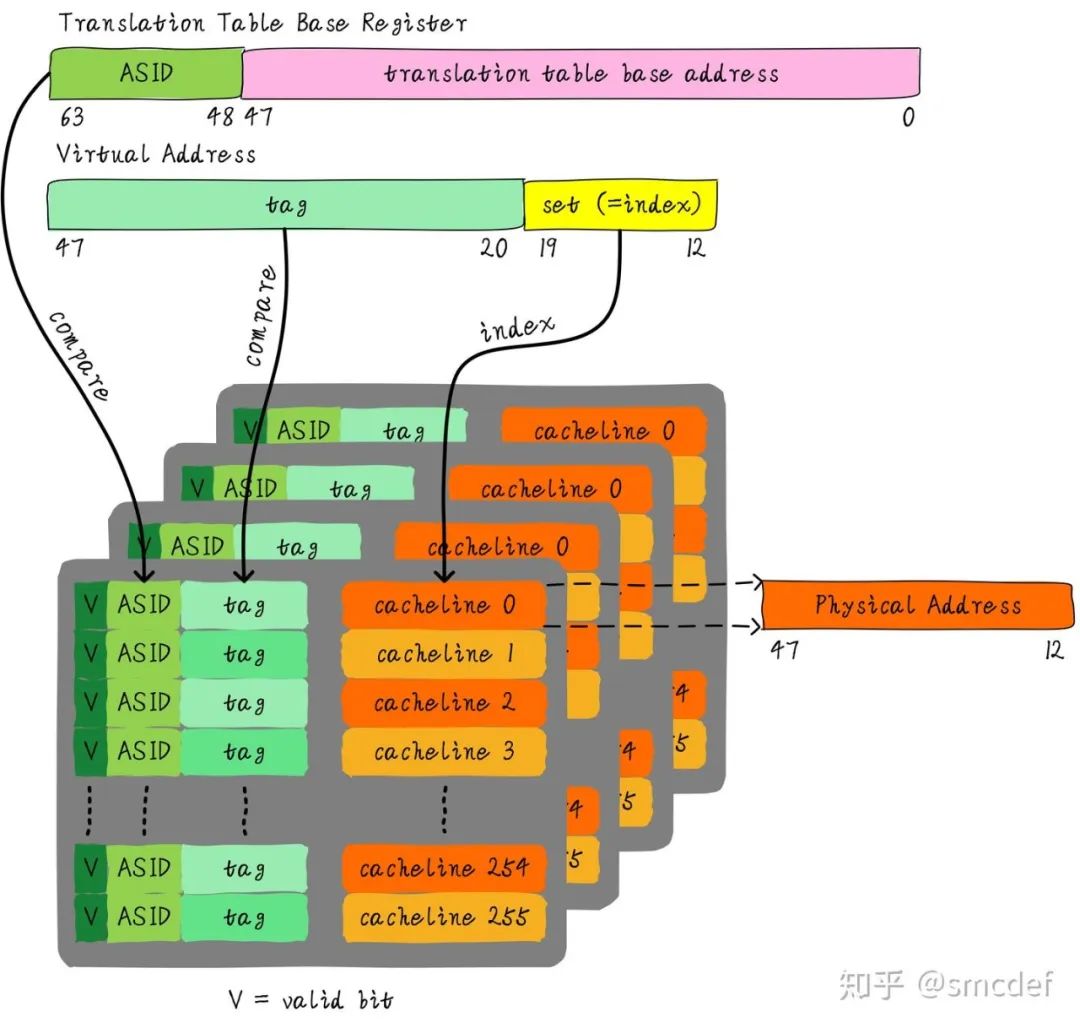
如何管理ASID
ASID和進程ID肯定是不一樣的,別混淆二者。進程ID取值范圍很大。但是ASID一般是8或16 bit。所以只能區(qū)分256或65536個進程。我們的例子就以8位ASID說明。所以我們不可能將進程ID和ASID一一對應(yīng),我們必須為每個進程分配一個ASID,進程ID和每個進程的ASID一般是不相等的。每創(chuàng)建一個新進程,就為之分配一個新的ASID。當(dāng)ASID分配完后,flush所有TLB,重新分配ASID。
所以,如果想完全避免flush TLB的話,理想情況下,運行的進程數(shù)目必須小于等于256。然而事實并非如此,因此管理ASID上需要軟硬結(jié)合。Linux kernel為了管理每個進程會有個task_struct結(jié)構(gòu)體,我們可以把分配給當(dāng)前進程的ASID存儲在這里。頁表基地址寄存器有空閑位也可以用來存儲ASID。當(dāng)進程切換時,可以將頁表基地址和ASID(可以從task_struct獲得)共同存儲在頁表基地址寄存器中。當(dāng)查找TLB時,硬件可以對比tag以及ASID是否相等(對比頁表基地址寄存器存儲的ASID和TLB表項存儲的ASID)。如果都相等,代表TLB hit。否則TLB miss。當(dāng)TLB miss時,需要多級遍歷頁表,查找物理地址。然后緩存到TLB中,同時緩存當(dāng)前的ASID。
多個進程共享
我們知道內(nèi)核空間和用戶空間是分開的,并且內(nèi)核空間是所有進程共享。既然內(nèi)核空間是共享的,進程A切換進程B的時候,如果進程B訪問的地址位于內(nèi)核空間,完全可以使用進程A緩存的TLB。但是現(xiàn)在由于ASID不一樣,導(dǎo)致TLB miss。
我們針對內(nèi)核空間這種全局共享的映射關(guān)系稱之為global映射。針對每個進程的映射稱之為non-global映射。所以,我們在最后一級頁表中引入一個bit(non-global (nG) bit)代表是不是global映射。當(dāng)虛擬地址映射物理地址關(guān)系緩存到TLB時,將nG bit也存儲下來。當(dāng)判斷是否命中TLB時,當(dāng)比較tag相等時,再判斷是不是global映射,如果是的話,直接判斷TLB hit,無需比較ASID。當(dāng)不是global映射時,最后比較ASID判斷是否TLB hit。
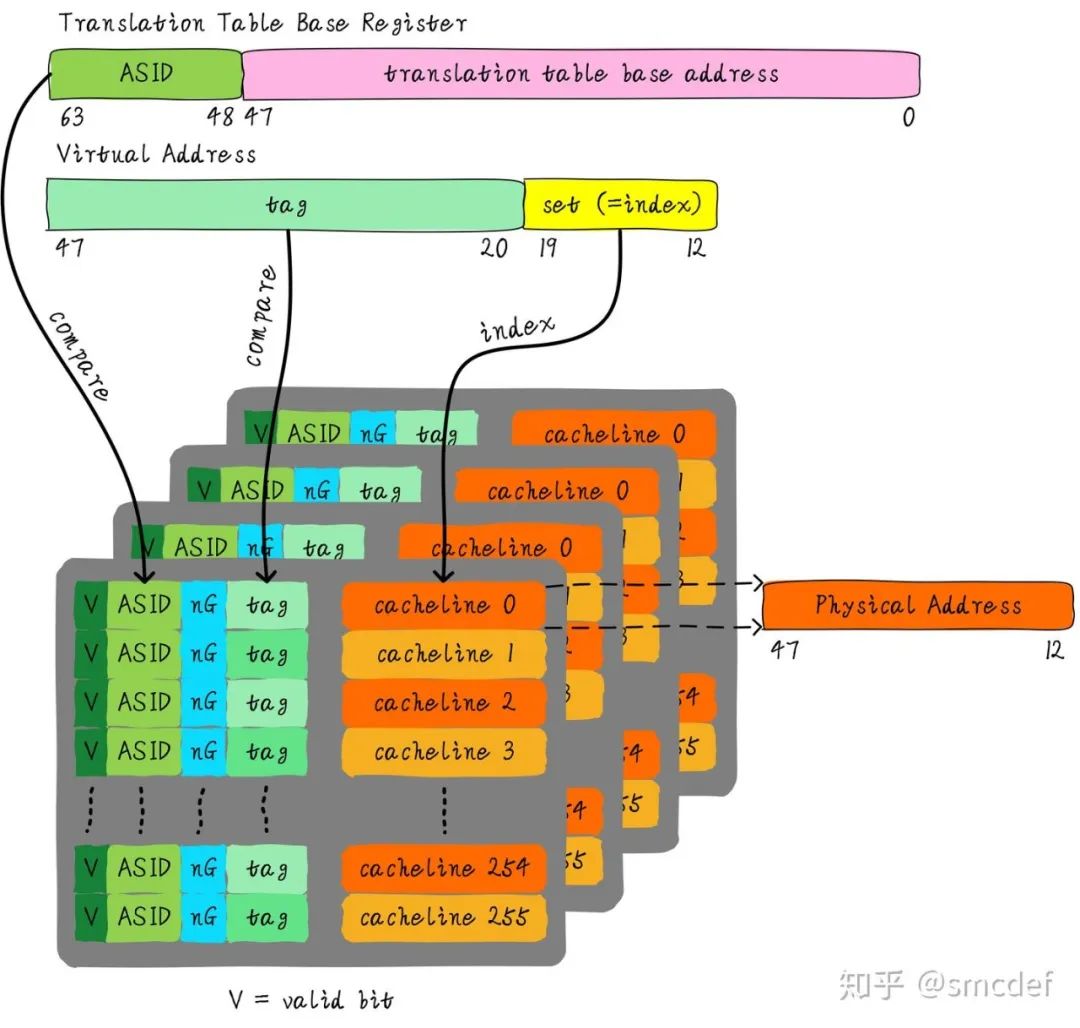
什么時候應(yīng)該flush TLB
我們再來最后的總結(jié),什么時候應(yīng)該flush TLB。
- 當(dāng)ASID分配完的時候,需要flush全部TLB,ASID的管理可以使用bitmap管理,flush TLB后clear整個bitmap。
- 當(dāng)我們建立頁表映射的時候,就需要flush虛擬地址對應(yīng)的TLB表項。
第一印象可能是修改頁表映射的時候才需要flush TLB,但是實際情況是只要建立映射就需要flush TLB。原因是,建立映射時你并不知道之前是否存在映射,例如,建立虛擬地址A到物理地址B的映射,我們并不知道之前是否存在虛擬地址A到物理地址C的映射情況,所以就統(tǒng)一在建立映射關(guān)系的時候flush TLB。
鏈接:https://zhuanlan.zhihu.com/p/108425561
(版權(quán)歸原作者所有,侵刪)