

梳理消息隊列 MQ/JMS/Kafka
是不是平常聽到說消息隊列啊,JMS啊,MQ啊 、kafka啊巴啦啦的一堆術語,聽不懂?關系混亂?今天就讓我們來一起來看看他們都是什么吧。
1消息隊列介紹
首先舉個收快遞的栗子,傳統的收快遞,快遞小哥把我們的快遞送到我們的手里。他需要什么條件嗯?
- 快遞小哥有時間送,
- 我們有時間取,
- 快遞小哥和我們約定一個時間地點。
但是嗯。快遞小哥有那么多的快遞需要送,可能送我快遞的時候,我不在家,可能我在家的時候,快遞小哥送其他的地方的快遞。所以嗯,這個時候,要么就是坐在家里等快遞,要么就只能從新約個時間點在送。那怎么辦去避免這個情況嗯?
于是嗯快遞柜出現了。快遞小哥不用關心我什么時候在家,因為快遞小哥有時間了,就把快遞放快遞柜,而我有時間了,我就去快遞柜取我的快遞。
那么快遞柜所起到的作用就是我們今天要收的消息隊列。我們可以把消息隊列比作是一個存放快遞的的快遞柜,當我們需要獲取我們快遞的時候就可以從快遞柜里面拿到屬于我們的快遞。
1.1什么是消息隊列
我們可以把消息隊列比作是一個存放消息的容器,當我們需要使用消息的時候可以取出消息供自己使用。我們看看維基百科上的描述:在計算機科學中,消息隊列(Message queue)是一種進程間通信或同一進程的不同線程間的通信方式,軟件的貯列用來處理一系列的輸入,通常是來自用戶。
是不是很難理解,我們換個說法來理解
我們可以把消息隊列比作是一個存放消息的容器,當我們需要使用消息的時候可以取出消息供自己使用。
1.2消息隊列(Message queue)有什么用?
消息隊列是分布式系統中重要的組件,使用消息隊列主要是為了通過異步處理提高系統性能和削峰、降低系統耦合性。
通過異步處理提高系統性能(削峰、減少響應所需時間)
舉個例子:我們在某個網站進行注冊賬號,我們需要做如下四件事:
- 填寫我們的注冊信息;
- 提交我們的注冊信息;
- 我們的郵箱收到注冊信息;
- 我們的短信收到注冊信息。
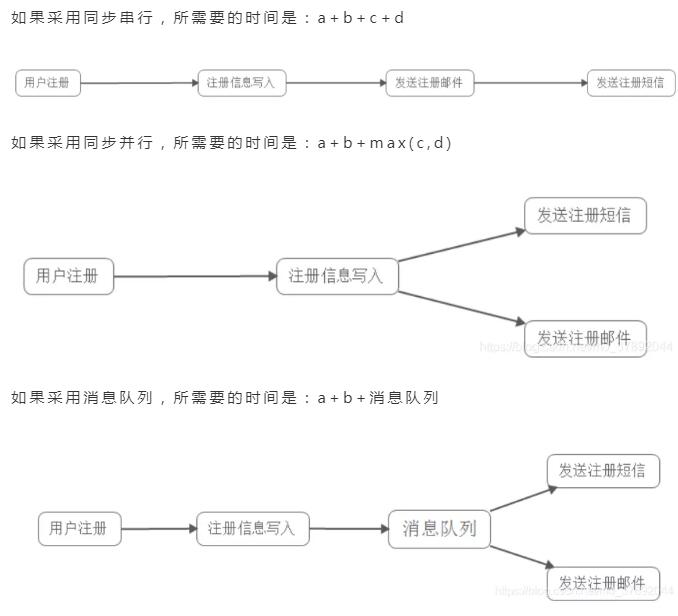

降低系統耦合性
舉個例子,A公司做了某個系統,B公司覺得A公司的某個功能很好,于是B公司和A公司的系統進行了集成。這時C公司也覺得A公司的這個功能很好,于是,C公司也和A公司的系統進行了集成。以后還有D公司…。
介于這種情況,A公司的系統和其他公司的耦合度都很高,每集成一個公司的系統,A公司都需要修改自己的系統。如果采用消息隊列,則變成了如下:
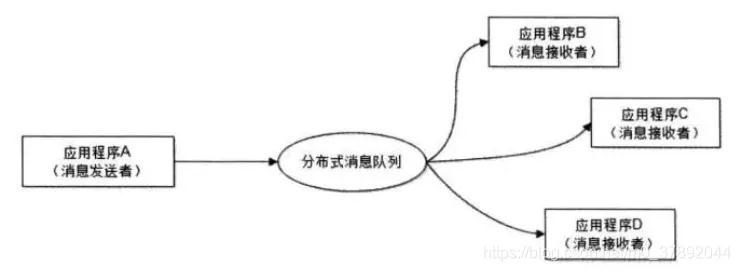
不管以后還有多少公司的應用程序想要用A公司的程序,都不需要和A公司進行集成,誰需要這個功能,誰就去消息隊列里面獲取。
1.3消息隊列的兩種模式
點對點模式
應用程序由:消息隊列,發送方,接收方組成。
每個消息都被發送到一個特定的隊列,接收者從隊列中獲取消息。隊列保留著消息,直到他們被消費或超時。
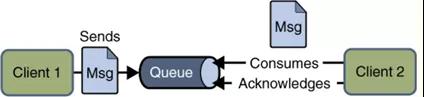
發布訂閱模式
應用程序由:角色主題(Topic)、發布者(Publisher)、訂閱者(Subscriber)構成。
發布者發布一個消息,該消息通過topic傳遞給所有的客戶端。該模式下,發布者與訂閱者都是匿名的,即發布者與訂閱者都不知道對方是誰。并且可以動態的發布與訂閱Topic。Topic主要用于保存和傳遞消息,且會一直保存消息直到消息被傳遞給客戶端。
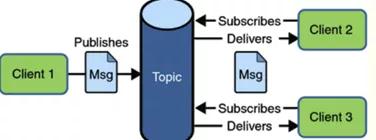
介紹完了消息隊列,接著我們介紹JMS
2JMS介紹
JMS即Java消息服務(Java Message Service)應用程序接口,是一個Java平臺中關于面向消息中間件(MOM)的API,類似于JDBC。用于在兩個應用程序之間,或分布式系統中發送消息,進行異步通信。它提供創建、發送、接收、讀取消息的服務。由Sun公司和它的合作伙伴設計的應用程序接口和相應語法,使得Java程序能夠和其他消息組件進行通信。
JMS是一個消息服務的標準或者說是規范,允許應用程序組件基于JavaEE平臺創建、發送、接收和讀取消息。它使分布式通信耦合度更低,消息服務更加可靠以及異步性。
介紹到這里,應該明白了消息隊列和JMS的區別了吧?
- 消息隊列:計算機科學中,A和B進行通信的一種方式。
- JMS:java平臺之間分布式通信的一種標準或者規范。
換句話說,JMS就是java對于消息隊列的一種實現方式。
2.1JSM消息模型
點對點,發布訂閱,消息隊列中已經說的很清楚了,這里就不重復說了。
2.2JMS消費
- 同步(Synchronous)
訂閱者/接收方通過調用 receive()來接收消息。在receive()方法中,線程會阻塞直到消息到達或者到指定時間后消息仍未到達。
- 異步(Asynchronous)
消息訂閱者需注冊一個消息監聽者,類似于事件監聽器,只要消息到達,JMS服務提供者會通過調用監聽器的onMessage()遞送消息。
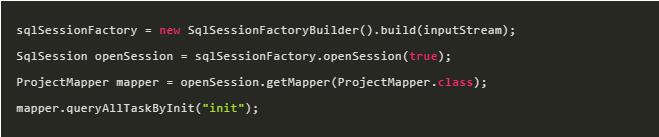
2.3JMS編程模型
JMS編程模型非常類似于JDBC。回憶一下,我們之前講到的MyBatis。
- SqlSessionFactoryBuilder去構造SqlSessionFactory會話工廠;
- SqlSessionFactory會話工廠給我們打開SqlSession會話;
- SqlSession幫我們去連接數據庫,接著我們就可以執行增刪查改。
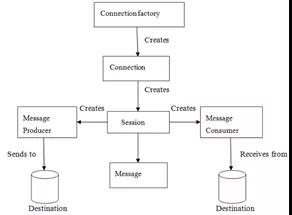
JMS模型如下
- Connection Factory給我創建Connection連接;
- Connection連接給我們創建了Session會話;
- Session會話給我們創建消費者和生產者;
- 生產者生成消息;
- 消費者消費消息;
3MQ介紹
上文中,我們說到了,JMS他并不是一種真正意義的技術,而是一種接口,一種規范。就想JDBC一樣,無論是mybatis、hibernate,還是springJPA,不管你是那種技術實現,反正你得遵守JDBC的規范。
在Java中,目前基于JMS實現的消息隊列常見技術有ActiveMQ、RabbitMQ、RocketMQ。值得注意的是,RocketMQ并沒有完全遵守JMS規范,并且Kafka不是JMS的實現。
3.1AMQP協議
這里我們以RabbitMQ為例介紹MQ,首先介紹下AMQP
AMQP協議(Advanced Message Queuing Protocol,高級消息隊列協議)是一個進程間傳遞異步消息的網絡協議。
AMQP模型
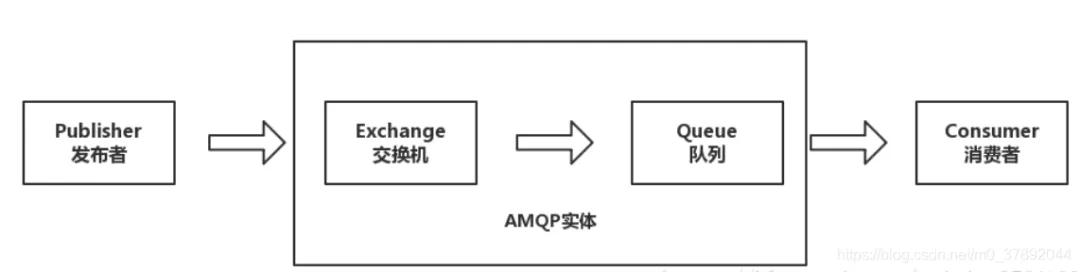
AMQP工作過程
發布者(Publisher)發布消息(Message),經由交換機(Exchange)。
交換機根據路由規則將收到的消息分發給與該交換機綁定的隊列、(Queue)。
最后 AMQP 代理會將消息投遞給訂閱了此隊列的消費者,或者消費者按照需求自行獲取。
RabbitMQ是MQ產品的典型代表,是一款基于AMQP協議可復用的企業消息系統
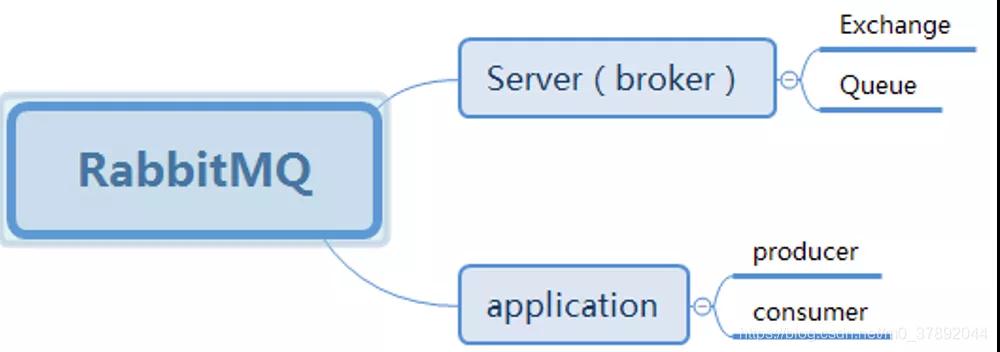
3.2RabbitMQ模型
RabbitMQ由兩部分組成,分別是服務端和應用端;
- 服務端包括:隊列和交換機。
- 客戶端包括:生產者和消費者。
在rabbitmq server上可以創建多個虛擬的message broker。每一個broker本質上是一個mini-rabbitmq server,分別管理各自的exchange,和bindings。
broker相當于物理的server,可以為不同app提供邊界隔離,使得應用安全的運行在不同的broker實例上,相互之間不會干擾。producer和consumer連接rabbit server需要指定一個broker。
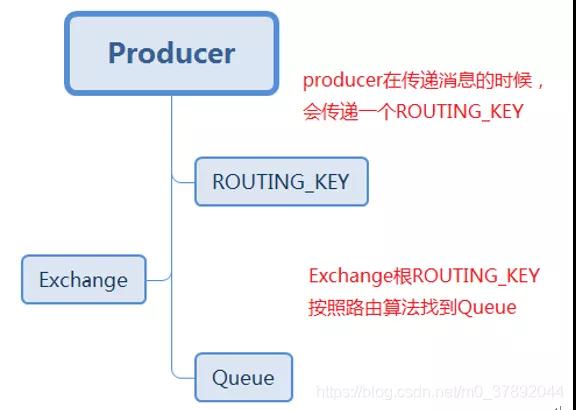
Exchange有4種類型:direct(默認),fanout, topic, 和headers
- Direct:直接交換器,工作方式類似于單播,Exchange會將消息發送完全匹配ROUTING_KEY的Queue。
- Fanout:廣播是式交換器,不管消息的ROUTING_KEY設置為什么,Exchange都會將消息轉發給所有綁定的Queue(所謂綁定就是將一個特定的 Exchange 和一個特定的 Queue 綁定起來。Exchange 和Queue的綁定可以是多對多的關系)。
- Topic:主題交換器,工作方式類似于組播,Exchange會將消息轉發和ROUTING_KEY匹配模式相同的所有隊列,比如,ROUTING_KEY為user.stock的Message會轉發給綁定匹配模式為 * .stock,user.stock, * . * 和#.user.stock.#的隊列。( * 表是匹配一個任意詞組,#表示匹配0個或多個詞組)。
至于如何在代碼中使用RabbitMQ,這里我們先不擼代碼,本文目前只介紹理論梳理知識點。
4Kafka
上完中我們提到過,kafka不是JMS的實現,因此在MQ章節中,我們沒有提及到它。現在我們開始學習kafka吧。
先來放張kafka的原理圖,相信你看到這個圖片時,內心是奔潰的。我草,啥玩意。接下來我們就一點一點的消化吧。
4.1kafka原理圖
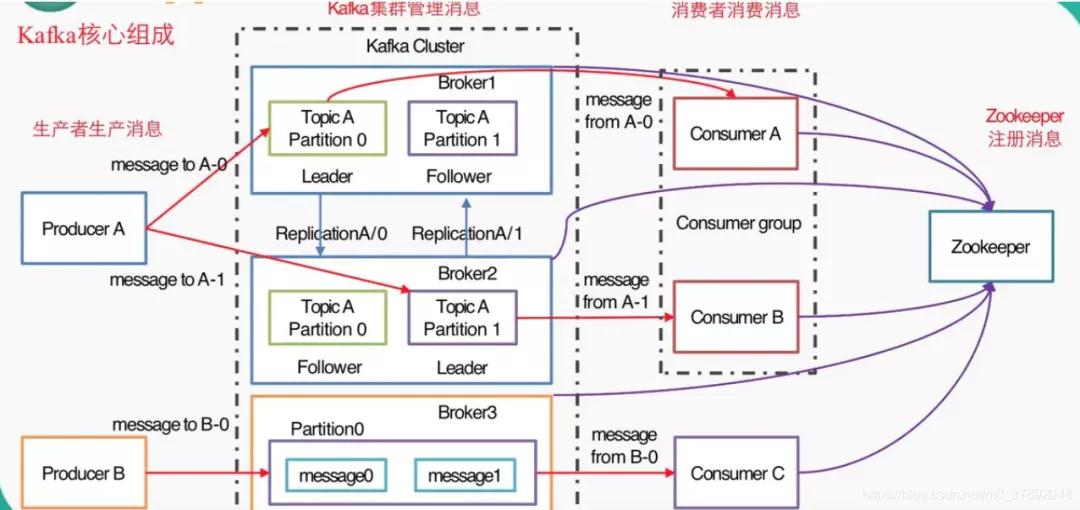
先介紹上圖中的術語。
- Producer :消息生產者,就是向kafka broker發消息的客戶端。
- Consumer :消息消費者,向kafka broker取消息的客戶端。
- Topic :kafka給消息提供的分類方式。broker用來存儲不同topic的消息數據。一個Topic可以認為是一類消息,每個topic將被分成多個partition(區),每個partition在存儲層面是append log文件。任何發布到此partition的消息都會被直接追加到log文件的尾部,每條消息在文件中的位置稱為offset(偏移量),offset為一個long型數字,它是唯一標記一條消息。它唯一的標記一條消息。kafka并沒有提供其他額外的索引機制來存儲offset,因為在kafka中幾乎不允許對消息進行“隨機讀寫”。
- broker:中間件的kafka cluster,存儲消息,是由多個server組成的集群。
- Partition:為了實現擴展性,一個非常大的topic可以分布到多個broker(即服務器)上,一個topic可以分為多個partition,每個partition是一個有序的隊列。partition中的每條消息都會被分配一個有序的id(offset)。kafka只保證按一個partition中的順序將消息發給consumer,不保證一個topic的整體(多個partition間)的順序。
- Offset:kafka的存儲文件都是按照offset.kafka來命名,例如你想找位于2049的位置,只要找到2048.kafka的文件即可。當然the first offset就是00000000000.kafka。
類似于JMS的特性,但不是JMS規范的實現。kafka對消息保存時根據Topic進行歸類,發送消息者成為Producer,消息接受者成為Consumer,此外kafka集群有多個kafka實例組成,每個實例(server)成為broker。無論是kafka集群,還是producer和consumer都依賴于zookeeper來保證系統可用性集群保存信息。
kafka基于文件存儲。通過分區,可以將日志內容分散到多個server上,來避免文件尺寸達到單機磁盤的上限,每個partiton都會被當前server(kafka實例)保存;可以將一個topic切分多任意多個partitions,來消息保存/消費的效率.此外越多的partitions意味著可以容納更多的consumer,有效提升并發消費的能力。
kafka和JMS不同的是:即使消息被消費,消息仍然不會被立即刪除。日志文件將會根據broker中的配置要求,保留一定的時間之后刪除。
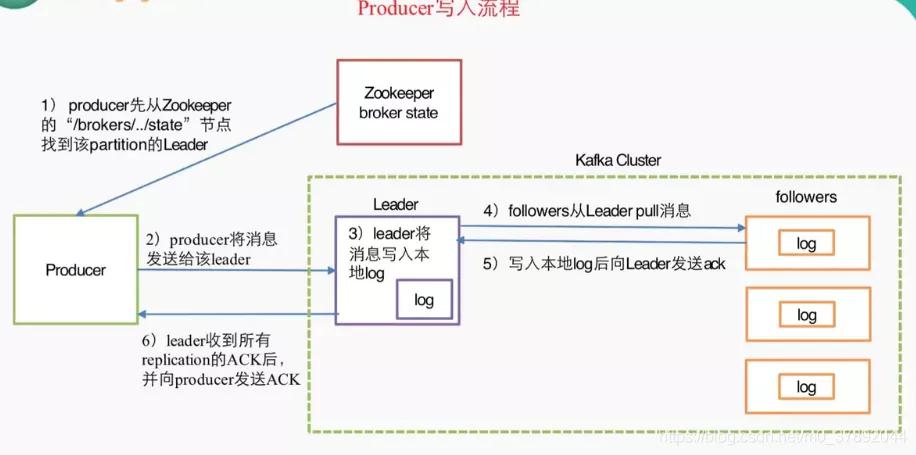
Kafka高可用機制
- 多個broker組成,每個broker是一個節點;
- 你創建一個topic,這個topic可以劃分為多個partition,每個partition可以存在于不同的broker上,每個partition就放一部分數據。
- 采用replica副本機制,每個partition的數據都會同步到其他機器上,形成多個replica副本。
- 所有replica會選舉一個leader出來,那么生產和消費都跟這個leader打交道,然后其他replica就是follower。
- 讀數據時,從leader讀取,寫數據時,leader把數據同步到所有follower上去。如果某個broker宕機了,這個broker在其他的broker還保留副本,假設這個broker上面存在leader,那么就重新選一個leader。
內容有點多,需要結合圖片一點一點消化
4.2生產者結構圖
至此,雖然看的云里霧里,不過相信你們還是能區分了吧?
整理一下:
- 消息隊列:指計算機領域中,A和B通信的一種通信方式;
- JMS:Java中對于消息隊列的接口規范;
- ActiveMQ/RabbitMQ:JMS接口規范具體實現的一種技術;
- RocketMQ:不完全是JMS接口規范具體實現的一種技術;
-
Kafka:非JMS接口規范具體實現的一種技術;
文章轉載:性能與架構
(版權歸原作者所有,侵刪)