

Python 多線程居然是 —— 假的?
最近有位讀者提問:
Python 的多線程真是假的嗎?
一下子點到了 Python 長期被人們喜憂參半的特性 —— GIL 上了。
到底是怎么回事呢?今天我們來聊一聊。
十全十美
我們知道 Python 之所以靈活和強大,是因為它是一個解釋性語言,邊解釋邊執行,實現這種特性的標準實現叫作 CPython。
它分兩步來運行 Python 程序:
-
首先解析源代碼文本,并將其編譯為字節碼(bytecode)[1] -
然后采用基于棧的解釋器來運行字節碼 -
不斷循環這個過程,直到程序結束或者被終止
靈活性有了,但是為了保證程序執行的穩定性,也付出了巨大的代價:
引入了?全局解釋器鎖?GIL(global interpreter lock)[2]
以保證同一時間只有一個字節碼在運行,這樣就不會因為沒用事先編譯,而引發資源爭奪和狀態混亂的問題了。
看似 “十全十美” ,但,這樣做,就意味著多線程執行時,會被 GIL 變為單線程,無法充分利用硬件資源。
來看代碼:
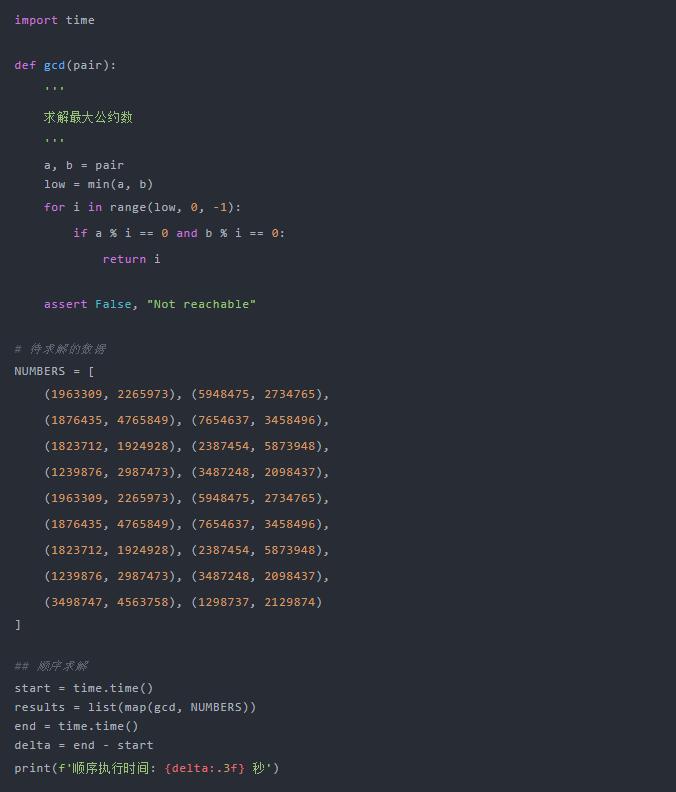

-
函數? gcd?用于求解最大公約數,用來模擬一個數據操作 -
NUMBERS?為待求解的數據 -
求解方式利用? map?方法,傳入處理函數 gcd, 和待求解數據,將返回一個結果數列,最后轉化為?list -
將執行過程的耗時計算并打印出來
在筆者的電腦上(4核,16G)執行時間為 2.043 秒。
如何換成多線程呢?
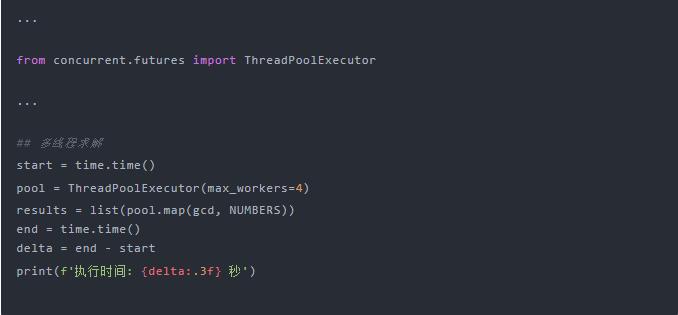
-
這里引入了? concurrent.futures?模塊中的線程池,用線程池實現起來比較方便 -
設置線程池為 4,主要是為了和 CPU 的核數匹配 -
線程池? pool?提供了多線程版的?map,所以參數不變
看看運行效果:


并行執行的時間竟然更長了!
連續執行多次,結果都是一樣的,也就是說在 GIL 的限制下,多線程是無效的,而且因為線程調度還多損耗了些時間。
戴著鐐銬跳舞
難道 Python 里的多線程真的沒用嗎?
其實也并不是,雖然了因為 GIL,無法實現真正意義上的多線程,但,多線程機制,還是為我們提供了兩個重要的特性。
一:多線程寫法可以讓某些程序更好寫
怎么理解呢?
如果要解決一個需要同時維護多種狀態的程序,用單線程是實現是很困難的。
比如要檢索一個文本文件中的數據,為了提高檢索效率,可以將文件分成小段的來處理,最先在那段中找到了,就結束處理過程。
用單線程的話,很難實現同時兼顧多個分段的情況,只能順序,或者用二分法執行檢索任務。
而采用多線程,可以將每個分段交給每個線程,會輪流執行,相當于同時推薦檢索任務,處理起來,效率會比順序查找大大提高。
二:處理阻塞型 I/O 任務效率更高
阻塞型 I/O 的意思是,當系統需要與文件系統(也包括網絡和終端顯示)交互時,由于文件系統相比于 CPU 的處理速度慢得多,所以程序會被設置為阻塞狀態,即,不再被分配計算資源。
直到文件系統的結果返回,才會被激活,將有機會再次被分配計算資源。
也就是說,處于阻塞狀態的程序,會一直等著。
那么如果一個程序是需要不斷地從文件系統讀取數據,處理后在寫入,單線程的話就需要等等讀取后,才能處理,等待處理完才能寫入,于是處理過程就成了一個個的等待。
而用多線程,當一個處理過程被阻塞之后,就會立即被 GIL 切走,將計算資源分配給其他可以執行的過程,從而提示執行效率。
有了這兩個特性,就說明 Python 的多線程并非一無是處,如果能根據情況編寫好,效率會大大提高,只不過對于計算密集型的任務,多線程特性愛莫能助。
曲線救國
那么有沒有辦法,真正的利用計算資源,而不受 GIL 的束縛呢?
當然有,而且還不止一個。
先介紹一個簡單易用的方式。
回顧下前面的計算最大公約數的程序,我們用了線程池來處理,不過沒用效果,而且比不用更糟糕。
這是因為這個程序是計算密集型的,主要依賴于 CPU,顯然會受到 GIL 的約束。
現在我們將程序稍作修改:
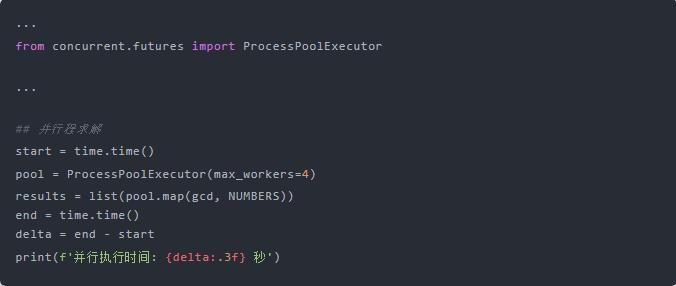
看看效果:

并行執行提升了將近 3 倍!什么情況?
仔細看下,主要是將多線程中的?ThreadPoolExecutor?換成了?ProcessPoolExecutor,即進程池執行器。
在同一個進程里的 Python 程序,會受到 GIL 的限制,但不同的進程之間就不會了,因為每個進程中的 GIL 是獨立的。
是不是很神奇?這里,多虧了?concurrent.futures?模塊將實現進程池的復雜度封裝起來了,留給我們簡潔優雅的接口。
這里需要注意的是,ProcessPoolExecutor?并非萬能的,它比較適合于?數據關聯性低,且是?計算密集型?的場景。
如果數據關聯性強,就會出現進程間 “通信” 的情況,可能使好不容易換來的性能提升化為烏有。
處理進程池,還有什么方法呢?那就是:
用 C 語言重寫一遍需要提升性能的部分
不要驚愕,Python 里已經留好了針對 C 擴展的 API。
但這樣做需要付出更多的代價,為此還可以借助于?SWIG[3]?以及?CLIF[4]?等工具,將 python 代碼轉為 C。
有興趣的讀者可以研究一下。
自強不息
了解到 Python 多線程的問題和解決方案,對于鐘愛 Python 的我們,何去何從呢?
有句話用在這里很合適:
求人不如求己
哪怕再怎么厲害的工具或者武器,都無法解決所有的問題,而問題之所以能被解決,主要是因為我們的主觀能動性。
對情況進行分析判斷,選擇合適的解決方案,不就是需要我們做的么?
對于 Python 中 多線程的詬病,我們更多的是看到它陽光和美的一面,而對于需要提升速度的地方,采取合適的方式。這里簡單總結一下:
-
I/O 密集型的任務,采用 Python 的多線程完全沒用問題,可以大幅度提高執行效率 -
對于計算密集型任務,要看數據依賴性是否低,如果低,采用? ProcessPoolExecutor?代替多線程處理,可以充分利用硬件資源 -
如果數據依賴性高,可以考慮將關鍵的地方改用 C 來實現,一方面 C 本身比 Python 更快,另一方面,C 可以之間使用更底層的多線程機制,而完全不用擔心受 GIL 的影響 -
大部分情況下,對于只能用多線程處理的任務,不用太多考慮,之間利用 Python 的多線程機制就好了,不用考慮太多
總結
沒用十全十美的解決方案,如果有,也只能是在某個具體的條件之下,就像軟件工程中,沒用銀彈一樣。
面對真實的世界,只有我們自己是可以依靠的,我們通過學習了解更多,通過實踐,感受更多,通過總結復盤,收獲更多,通過思考反思,解決更多。這就是我們人類不斷發展前行的原動力。
為了我們美好的明天,為了人類美好的明天,加油!
比心!