

使用Kubernetes兩年的經(jīng)驗教訓(xùn)
大約兩年前,我們決定放棄基于Ansible的安裝配置方式,以便在EC2上部署應(yīng)用程序的方式,并轉(zhuǎn)向使用Kubernetes實現(xiàn)應(yīng)用程序的容器化和編排。我們已經(jīng)將大部分基礎(chǔ)設(shè)施遷移到了Kubernetes。這是一項艱巨的任務(wù)以及挑戰(zhàn)——從混合部署方式直到大部分遷移完成,再到培訓(xùn)整個團隊學(xué)習全新的操作范式等等。


在這篇文章中,我們想回顧一下我們的經(jīng)驗,并與你分享我們在這段旅程中所學(xué)到的東西,以幫助你做出更好的決策,增加成功的機會。
清楚你遷移到Kubernetes的原因
無服務(wù)和容器化是很好的概念。如果你正在創(chuàng)建一個新的業(yè)務(wù)并從頭開始構(gòu)建所有東西,那么一定要使用容器部署應(yīng)用程序,如果你有信心(或者可能沒有,請繼續(xù)閱讀)和技術(shù)能力來配置和操作Kubernetes,以及在Kubernetes上部署應(yīng)用程序,那么就請使用Kubernetes來部署應(yīng)用程序。
即使你使用托管的Kubernetes服務(wù),如EKS、GKE或AKS,在Kubernetes上正確部署和操作應(yīng)用程序也有它的學(xué)習曲線。你的開發(fā)團隊應(yīng)該準備好迎接挑戰(zhàn)。只有當你的團隊遵循DevOps理念,團隊才能從中獲益。如果你讓專門的運維團隊為開發(fā)團隊編寫應(yīng)用程序清單,那么從DevOps的角度來看,我們個人認為你將從Kubernetes中獲益較少。當然,選擇Kubernetes還有很多其他的好處,例如成本、更快的實驗、更快的自動伸縮性、彈性等等。
如果你已經(jīng)在云虛擬機或其他PaaS平臺上部署應(yīng)用程序,請認真考慮你為什么還要遷移到Kubernetes?你相信Kubernetes是解決問題的唯一方法嗎?你必須清楚自己的動機,因為將現(xiàn)有基礎(chǔ)設(shè)施遷移到Kubernetes是一項艱巨的任務(wù)。
我們在這方面犯了一些錯誤。我們遷移到Kubernetes的主要原因是構(gòu)建一個持續(xù)集成平臺。在這些年中,我們的應(yīng)用程序累積了大量的技術(shù)債務(wù),我們希望Kubernetes可以幫助我們快速地重新構(gòu)建我們的微服務(wù)。大部分的新功能開發(fā)都需要修改多處的代碼才能完成,這嚴重拖慢了我們新特性的開發(fā)速度。我們覺得有必要為每個開發(fā)人員和每個變更提供一個集成環(huán)境,以幫助加快開發(fā)和測試周期,而不需要協(xié)調(diào),在同一套環(huán)境上進行開發(fā)。
下圖是我們的持續(xù)集成管道之一,它提供了一個新的集成環(huán)境和所有的微服務(wù),并運行自動化測試。
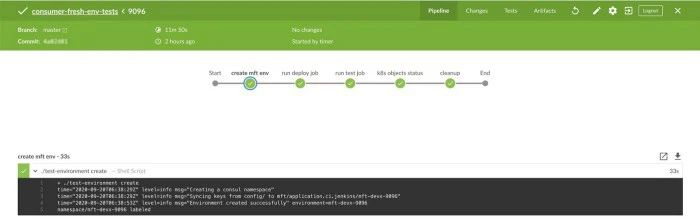
我們現(xiàn)在做得很好。我們今天在Kubernetes上,可以在8分鐘內(nèi)部署一個具有21個微服務(wù)的集成環(huán)境。任何開發(fā)人員都可以使用我們自己開發(fā)的工具來實現(xiàn)這一點。針對每個pull request我們亦可創(chuàng)建一個集成環(huán)境。整個測試周期(部署環(huán)境、配置環(huán)境以及運行測試)不到12分鐘。你可能覺得12分鐘很長,但它確實幫助我們有效驗證了每一次發(fā)布變更。
下圖為持續(xù)集成管道的執(zhí)行報告。
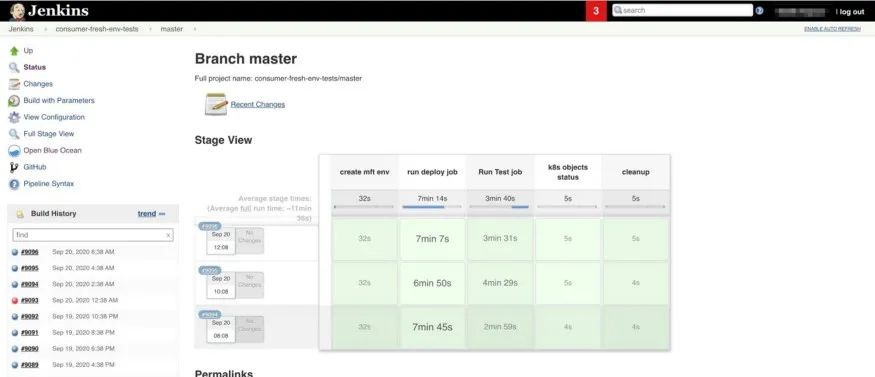
太好了!我們怎么做到的?我們花了將近1年半的時間來完成這一切。值得嗎?
我們花了將近1年半的時間,通過構(gòu)建額外的工具、自動化和重構(gòu)每個應(yīng)用程序來穩(wěn)定這個復(fù)雜的持續(xù)集成。為了實現(xiàn)開發(fā)環(huán)境和生產(chǎn)環(huán)境的一致性,我們必須將所有微服務(wù)部署到生產(chǎn)環(huán)境中,否則,基礎(chǔ)設(shè)施和部署設(shè)置之間的偏差將使開發(fā)人員難以理解和操作應(yīng)用程序。
我們對這個話題有著復(fù)雜的感情。回顧過去,我們認為我們讓解決持續(xù)集成的問題變得更糟,因為將所有微服務(wù)推到生產(chǎn)環(huán)境中以實現(xiàn)開發(fā)環(huán)境和生產(chǎn)環(huán)境的一致性,這使持續(xù)集成變得更復(fù)雜和困難,也大大降低了持續(xù)集成的速度。在Kubernetes之前,我們使用Ansible,Hashicorp Consul和Vault進行基礎(chǔ)設(shè)施部署以及配置。它慢嗎?是的,當然慢。但我們認為我們可以引入Consul服務(wù)發(fā)現(xiàn),并對Ansible部署進行優(yōu)化,以便在較短的時間內(nèi)接近我們的目標。
我們應(yīng)該遷移到Kubernetes嗎?是的,當然。使用Kubernetes有幾個好處——服務(wù)發(fā)現(xiàn)、更好的成本管理、彈性、治理、云基礎(chǔ)設(shè)施等等。我們今天也收獲了所有這些好處。但這并不是我們剛開始時的主要目標,我們自己強加給我們的壓力和付出的痛苦也許是不必要的。
“對我們來說,一個重大的教訓(xùn)是,我們本可以采取一種不同的、阻力較小的方式來采用Kubernetes。但我們被Kubernetes收購了,Kubernetes是我們唯一的選擇,甚至不需要去評估其他解決方案。
在這篇文章中,我們將看到Kubernetes上的遷移和操作與部署在云上或裸機上是不一樣的。你的工程師團隊會有一個學(xué)校曲線。讓你的團隊經(jīng)歷一下也許是值得的。但問題是你現(xiàn)在需要這么做嗎?你一定要想清楚。
開箱即用的Kubernetes對任何人來說都是遠遠不夠的
很多人會把Kubernetes當作PaaS解決方案——它不是PaaS解決方案。它是構(gòu)建PaaS解決方案的平臺。例如OpenShift就是一個基于Kubernetes的PaaS的平臺。
開箱即用的Kubernetes對幾乎任何人來說都是遠遠不夠的。這是一個學(xué)習和探索的好地方。但是,你很可能需要更多的基礎(chǔ)設(shè)施組件,并將它們作為應(yīng)用程序的一部分,有機的結(jié)合在一起,使其對你的開發(fā)人員更有意義。通常這種帶有附加基礎(chǔ)設(shè)施組件和策略的Kubernetes平臺,我們稱其為“Internal Kubernetes Platform[1]”。有幾種方法可以擴展Kubernetes平臺[2]。
在度量指標監(jiān)控、日志、服務(wù)發(fā)現(xiàn)、分布式鏈路追蹤、配置和秘鑰管理、CI/CD、本地開發(fā)經(jīng)驗、自動伸縮等方面,我們都需要考慮和作出決策。以上這些只是我們能想到的。當然還有更多的決策要做,更多的基礎(chǔ)設(shè)施需要建立。一個重要的方面是你的開發(fā)人員將如何使用Kubernetes資源和清單,在稍后的文章中我們將對此進行詳細介紹。
以下是我們的作出的一些決策和理由。
度量指標監(jiān)控(Metrics)
我們最終決定使用Prometheus。在度量指標監(jiān)控方面,Prometheus幾乎是一個事實標準。CNCF和Kubernetes非常喜歡它。它在Grafana生態(tài)系統(tǒng)中非常有效。我們也很喜歡Grafana!我們唯一的問題是以前用的是InfluxDB。我們決定離開InfluxDB,完全投入Prometheus。
日志
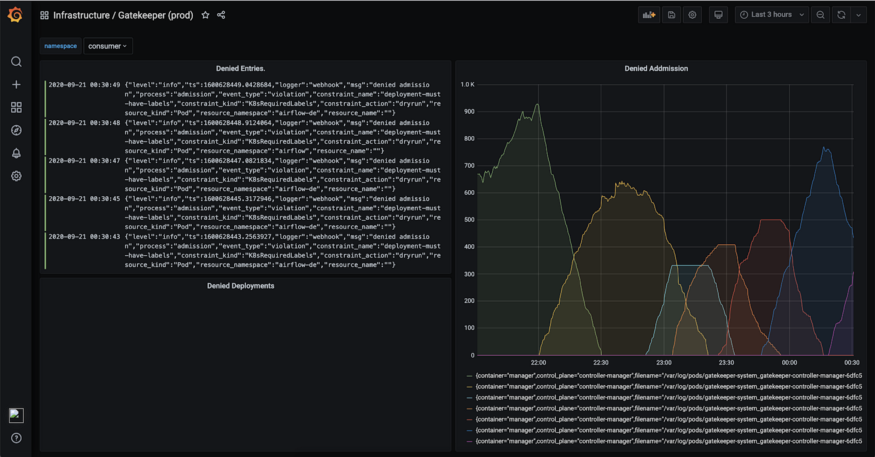
日志一直是我們的大問題。我們一直在努力使用ELK創(chuàng)建一個穩(wěn)定的日志記錄平臺。我們發(fā)現(xiàn)在ELK中充滿了對我們團隊沒有實際使用的功能。這些功能是有代價的。另外,我們認為在日志中使用Elasticsearch存在固有的挑戰(zhàn),這使得它成為一個昂貴的日志解決方案。我們最后決定使用Loki。它很簡單,具有滿足我們團隊需要的必要功能。最重要的是,它的查詢語言與PromQL非常相似,具有良好的用戶體驗。而且,它與Grafana配合得很好。更可以將整個度量指標監(jiān)控和日志記錄平臺集中在一個用戶界面中。
下圖是Grafana儀表板的一個示例,它可以同時顯示度量指標和相應(yīng)的日志。
配置管理和秘鑰管理
在Kubernetes中,你會發(fā)現(xiàn)大多數(shù)文章使用ConfigMap和Secret對象。我們的經(jīng)驗是它們可以滿足你的基本需求。在現(xiàn)有服務(wù)中使用ConfigMap是要付出一定代價的。ConfigMap可以以某種方式掛載到Pod中,使用環(huán)境變量是最常見的方式。如果你有大量的遺留微服務(wù),從配置管理工具(如Puppet、Chef或Ansible)中讀取配置文件,則必須重構(gòu)現(xiàn)有的代碼,以便從環(huán)境變量中讀取。我們沒有找到足夠的理由去做這件事。另外,配置文件的更改意味著您必須重啟服務(wù)。
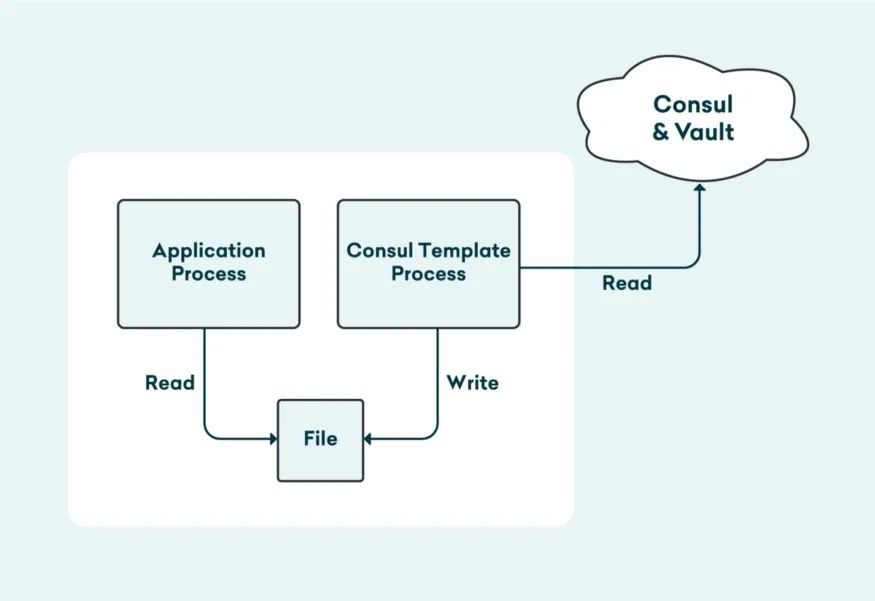
為了避免這一切,我們決定使用Consul、Vault和Consul Template進行配置管理和秘鑰管理。我們將Consul Template作為init容器運行,并在Pod中添加一個sidecar容器,以便它可以監(jiān)視Consul Template中的配置更改,刷新Vault中過期的秘鑰信息,并優(yōu)雅地重新加載應(yīng)用程序進程。
CI/CD
在遷移到Kubernetes之前,我們使用Jenkins做CI/CD。遷移到Kubernetes之后,我們決定依然使用Jenkins。到目前為止,我們的經(jīng)驗是,Jenkins并不是云場景下的最佳解決方案。我們用Python、Bash、Docker和腳本化/聲明性的Jenkins管道做了大量的工作,使CI/CD可以工作。編寫和維護這些工具和管道開始變得很昂貴。我們現(xiàn)在正在探索Tekton和Argo Workflows工作流作為我們新的CI/CD平臺。你也有其他更多的選擇,如Jenkins X,Screwdriver,Keptn等。
開發(fā)經(jīng)驗
在開發(fā)中,有很多種方法使用Kubernetes。我們主要集中在兩個選項上——Telepresence.io和Skaffold。Skaffold能夠監(jiān)視你的本地更改,并不斷地將它們部署到Kubernetes集群中。另一方面,Telepresence允許你在本地運行服務(wù),同時使用Kubernetes集群設(shè)置一個透明的網(wǎng)絡(luò)代理,以便你的本地服務(wù)可以像部署在集群中一樣與Kubernetes中的其他服務(wù)通信。這是個人意見和喜好的問題。很難決定哪一種工具更好。我們現(xiàn)在主要是在嘗試Telepresence,但我們沒有放棄Skaffold 成為更好工具的可能性。只有時間會告訴我們到底使用,或者兩者同時使用。當然還有其他的解決方案,比如Draft。
分布式鏈路追蹤
我們還沒有實現(xiàn)分布式鏈路追蹤。不過,我們已經(jīng)在計劃中。與日志一樣,我們希望也能將分布式鏈路追蹤集成在Grafana中,以便為我們的開發(fā)團隊提供更佳的可觀察性體驗。
應(yīng)用程序打包、部署和工具
Kubernetes的一個重要方面是考慮開發(fā)人員將如何與集群交互并部署他們的工作負載。我們想讓事情變得簡單,易于擴展。我們正在嘗試Kustomize,Skaffold和一些自行開發(fā)的CRDs,作為開發(fā)人員部署和管理應(yīng)用程序的方式。盡管如此,任何團隊都可以自由地使用他們想使用的任何工具來與集群交互,只要他們是開源的,并且構(gòu)建在開放標準之上。
操作Kubernetes集群很困難
圖片
我們的業(yè)務(wù)主要在新加坡地區(qū)運營。在我們開始Kubernetes的旅程時,EKS還沒有在新加坡地區(qū)提供服務(wù)。所以我們不得不在EC2上使用kops建立自己的Kubernetes集群。
建立一個開箱即用的集群也許沒有那么困難。我們能夠在一周內(nèi)啟動我們的第一個集群。大多數(shù)問題發(fā)生在開始部署工作負載時。如何將集群調(diào)整到最佳狀態(tài),自動擴縮容該如何設(shè)置,網(wǎng)絡(luò)該怎么配置?你必須自己進行研究和配置。默認值在大多數(shù)情況下都不適用于生產(chǎn)(或者至少對我們不起作用)。
“經(jīng)過兩年的生產(chǎn)經(jīng)驗,我們認為操作Kubernetes是很復(fù)雜的。Kubernetes有很多組件組成。你更關(guān)心的是你的核心業(yè)務(wù),而不是如果操作Kubernetes,盡可能地將這些事情交給云服務(wù)提供商,比如EKS、GKE、AKS等。你不能從操作Kubernetes中獲得任何價值。
你還得考慮升級
Kubernetes非常復(fù)雜,即使你使用的是托管服務(wù),升級也不會一帆風順。
即使使用了托管Kubernetes服務(wù),也應(yīng)盡早將災(zāi)難恢復(fù)和升級的過程自動化,能夠在災(zāi)難面臨前快速做出反應(yīng)。
如果你愿意,你可以嘗試GitOps理念。如果不能做到這一點,那么將手動步驟減少到最低限度也是一個很好的開始。我們使用eksctl、terraform和我們的集群配置清單(包括平臺服務(wù)的清單)組合來建立我們的Kubernetes平臺 ——“Grofers Kubernetes Platform”。為了使部署和配置過程更簡單和可重復(fù),我們構(gòu)建了一個自動化管道來設(shè)置新的集群并將更改部署到現(xiàn)有集群中。
資源請求和限制
圖片
在開始遷移之后,我們發(fā)現(xiàn)集群中由于配置不正確而出現(xiàn)了許多性能和功能問題。其效果之一是在資源請求和限制中添加了大量的緩沖區(qū),以消除資源限制作為性能降低的可能性。
最初的現(xiàn)象是由于節(jié)點內(nèi)存不足而導(dǎo)致Pod被迫逐出。原因是與Pod的資源請求相比,資源限制過高。隨著流量的激增,內(nèi)存消耗的增加可能會導(dǎo)致節(jié)點上的內(nèi)存飽和,進而導(dǎo)致Pod被迫逐出。
“經(jīng)過兩年的生產(chǎn)經(jīng)驗,我們認為保持資源請求足夠高,但不要太高,以防止在低流量時間浪費資源,并將資源限制相對接近資源請求,以便為尖峰流量提供一些喘息空間,而不會因節(jié)點內(nèi)存壓力而導(dǎo)致Pod被迫逐出。資源限制與資源請求的具體數(shù)值取決于你的流量模式。
但以上經(jīng)驗并不適用于非生產(chǎn)環(huán)境,如開發(fā)環(huán)境。這些環(huán)境下的流量不會出現(xiàn)任何峰值。理論上,如果將CPU請求設(shè)置為零,并為容器設(shè)置足夠高的CPU限制,則可以運行無限的容器。如果你的容器開始大量使用CPU,它們將被限制。對于內(nèi)存請求和限制也可以這樣做。然而,達到內(nèi)存限制的行為與CPU不同。如果使用的內(nèi)存超過了設(shè)置的內(nèi)存限制,那么容器就會被殺死并重新啟動。如果內(nèi)存限制異常高(假設(shè)高于節(jié)點的容量),則可以繼續(xù)使用內(nèi)存,最終當節(jié)點的可用內(nèi)存不足時,調(diào)度程序?qū)㈤_始逐出Pod。
在非生產(chǎn)環(huán)境中,我們通過保持資源請求極低而限制極高,來盡可能安全地過度提交資源。在這種情況下,限制因素是內(nèi)存,也就是說,無論內(nèi)存請求有多低,內(nèi)存限制有多高,Pod逐出,都是一個節(jié)點上所有容器使用的內(nèi)存總和的函數(shù)。
安全與治理
圖片
Kubernetes旨在為開發(fā)者打造一個云平臺,使他們更加獨立,并推動DevOps文化。向開發(fā)人員開放平臺,減少云工程師團隊(或系統(tǒng)管理員)的干預(yù),使開發(fā)團隊更獨立,應(yīng)該是重要目標之一。
有時這種獨立性可能帶來嚴重的風險。例如,在EKS中使用LoadBalancer類型的服務(wù),默認情況下提供面向公共網(wǎng)絡(luò)的ELB。添加某個注釋,確保創(chuàng)建的是內(nèi)部ELB,而不是面向公共網(wǎng)絡(luò)的。我們很早就犯了這些錯誤。
“我們使用Open Policy Agent來降低這些安全風險,以及與成本、安全和技術(shù)債務(wù)相關(guān)的風險。
使用Open Policy Agent來構(gòu)建正確的自動化變更管理過程,并為我們的開發(fā)人員構(gòu)建正確的安全網(wǎng)。使用Open Policy Agent,我們可以限制服務(wù)對象的創(chuàng)建,除非出現(xiàn)正確的注釋,這樣開發(fā)人員就不會意外地創(chuàng)建面向公共網(wǎng)絡(luò)的ELB。
成本
圖片
我們在遷移后看到了巨大的成本效益。然而,并不是所有的好處都是立竿見影的。我們正在整理一份關(guān)于成本效益的更詳細的帖子。
更好地利用資源容量
這是最明顯的一個。我們使用了更少的計算、內(nèi)存和存儲資源,提供了和以前一樣的基礎(chǔ)設(shè)施能力。除了因為容器和流程變得更好了,我們更好地利用了我們的共享服務(wù),比如可觀察性流程(度量指標監(jiān)控和日志)。
然而,最初我們在遷移的時候浪費了大量的資源。由于我們無法以正確的方式優(yōu)化自我管理的Kubernetes集群,這導(dǎo)致了大量的性能問題,我們最終在Pod中添加了大量的資源請求作為緩沖,更像是保險,以減少由于計算或內(nèi)存不足而導(dǎo)致的停機或性能問題的可能性。
“由于大量的資源緩沖,基礎(chǔ)設(shè)施成本高是一個大問題。由于Kubernetes的原因,我們并沒有意識到Kubernetes帶來的產(chǎn)能好處。在遷移到EKS之后,Kubernetes的穩(wěn)定性幫助我們變得更加自信,幫助我們采取必要的步驟來糾正資源請求,并大幅減少資源浪費。
Spot實例
在Kubernetes中使用Spot實例會變得容易得多。在使用Spot實例時,Spot實例隨時可能被回收,對于一般應(yīng)用程序而言,如何確保應(yīng)用程序一直正常運行,這可能會變得更復(fù)雜。但對于Kubernetes來說,對于中斷的容器,可以被快速的重新調(diào)度。
“Spot實例同時幫助我們節(jié)省了大量資金。今天,我們的測試集群運行在Spot實例上。
對我們來說,下一步優(yōu)化是如何將生產(chǎn)集群運行在Spot實例上。在另一篇博文中有更多關(guān)于這個主題的文章。
ELB合并
我們使用Ingress來整合測試環(huán)境中的ELB,并大幅降低ELB的支出成本。為了避免在代碼中,實現(xiàn)開發(fā)與測試/生產(chǎn)環(huán)境的差異,我們決定實現(xiàn)一個控制器,它將LoadBalancer類型的服務(wù)與測試/生產(chǎn)環(huán)境中的一個Ingres對象一起變更為NodePort類型的服務(wù)。
對于我們來說,遷移到Nginx ingress相對簡單,由于我們的控制器方法,不需要太多更改。如果我們在生產(chǎn)中也使用Ingress,可以節(jié)省更多的成本。這不是一個簡單的改變。在以正確的方式為生產(chǎn)環(huán)境配置Ingress時,必須考慮幾個問題,并且需要從安全性和API管理的角度來考慮。這是我們打算在不久的將來開展工作的領(lǐng)域。
增加跨AZ數(shù)據(jù)傳輸
雖然我們節(jié)省了大量的基礎(chǔ)設(shè)施開支,但有一個基礎(chǔ)設(shè)施領(lǐng)域的成本會增加——跨AZ數(shù)據(jù)傳輸。
Pod可以被分配到任何節(jié)點。即使你控制了Pod在集群中的分配方式,也沒有簡單的方法來控制服務(wù)如何發(fā)現(xiàn)彼此,即一個服務(wù)的Pod與同一AZ中的另一個服務(wù)的Pod進行通信,以減少跨AZ的數(shù)據(jù)傳輸。
在與其他公司的同行進行了大量的研究和交談之后,我們了解到,通過引入服務(wù)網(wǎng)格來控制從一個Pod到另一個Pod的流量是如何路由的,這是可以實現(xiàn)的。我們還沒有準備好僅僅為了節(jié)省跨AZ數(shù)據(jù)傳輸?shù)某杀径约撼袚僮鞣?wù)網(wǎng)格的復(fù)雜性。
CRD、Operators和控制器——簡化操作
圖片
每個組織都有自己的工作流程和運維挑戰(zhàn)。我們也有我們的。
“在兩年的Kubernetes之旅中,我們了解到Kubernetes很棒,當你使用它的功能,如控制器、Operators和CRD,來簡化日常操作,并為開發(fā)人員提供更集成的體驗時,它簡直太棒了。
我們已經(jīng)開始投資創(chuàng)建一系列Operators和CRD。例如,LoadBalancer服務(wù)類型到Ingress的轉(zhuǎn)換是一個控制器操作。類似地,每當部署新服務(wù)時,我們使用控制器在DNS服務(wù)器中自動創(chuàng)建CNAME記錄。這是幾個例子。我們還有5個單獨的用例,我們依賴內(nèi)部控制器來簡化日常操作并減少工作量。
我們還建造了一些CRD。其中一種被廣泛用于在Grafana上生成監(jiān)控儀表板,聲明性地指定應(yīng)該使用什么樣的監(jiān)控儀表板。這使得開發(fā)人員可以在應(yīng)用程序代碼庫旁邊簽入監(jiān)視儀表板,并使用相同的工作流kubectl apply -f ... 部署所有內(nèi)容。
我們看到了控制器和CRD的巨大優(yōu)勢。當我們與云供應(yīng)商AWS密切合作以簡化集群基礎(chǔ)設(shè)施操作時,我們將更多精力放在構(gòu)建“the Grofers Kubernetes platform”上,該平臺架構(gòu)的宗旨是以最佳方式支持我們的開發(fā)團隊。
相關(guān)鏈接:
-
https://itnext.io/why-everyone-builds-internal-kubernetes-platforms-284c2cf76226 -
https://speakerdeck.com/gianarb/cloud-native-ambassador-day-extending-kubernetes
原文鏈接:https://lambda.grofers.com/learnings-from-two-years-of-kubernetes-in-production-b0ec21aa2814
文章轉(zhuǎn)載:?分布式實驗室
(版權(quán)歸原作者所有,侵刪)