

60道Python常見面試題,做對80% Offer任你挑!
資源專區;Python面試題匯總(150+道)


經典python面試題匯總,共計150+道。掃描文末二維碼免費領取!
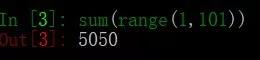
1、一行代碼實現1--100之和
利用sum()函數求和
2、如何在一個函數內部修改全局變量
函數內部global聲明 修改全局變量

3、列出5個python標準庫
os:提供了不少與操作系統相關聯的函數
sys: ? 通常用于命令行參數
re: ? 正則匹配
math: 數學運算
datetime:處理日期時間
4、字典如何刪除鍵和合并兩個字典
del和update方法

5、談下python的GIL
GIL 是python的全局解釋器鎖,同一進程中假如有多個線程運行,一個線程在運行python程序的時候會霸占python解釋器(加了一把鎖即GIL),使該進程內的其他線程無法運行,等該線程運行完后其他線程才能運行。如果線程運行過程中遇到耗時操作,則解釋器鎖解開,使其他線程運行。所以在多線程中,線程的運行仍是有先后順序的,并不是同時進行。
多進程中因為每個進程都能被系統分配資源,相當于每個進程有了一個python解釋器,所以多進程可以實現多個進程的同時運行,缺點是進程系統資源開銷大
6、python實現列表去重的方法
先通過集合去重,在轉列表:

7、fun(*args,**kwargs)中的*args,**kwargs什么意思?

8、python2和python3的range(100)的區別
python2返回列表,python3返回迭代器,節約內存
9、一句話解釋什么樣的語言能夠用裝飾器?
函數可以作為參數傳遞的語言,可以使用裝飾器
10、python內建數據類型有哪些
整型--int
布爾型--bool
字符串--str
列表--list
元組--tuple
字典--dict
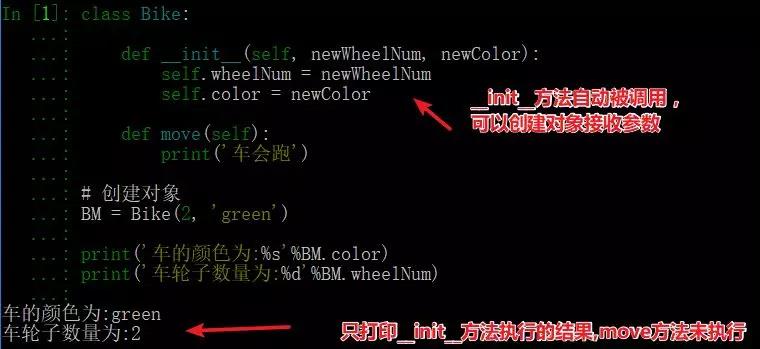
11、簡述面向對象中__new__和__init__區別
__init__是初始化方法,創建對象后,就立刻被默認調用了,可接收參數,如圖
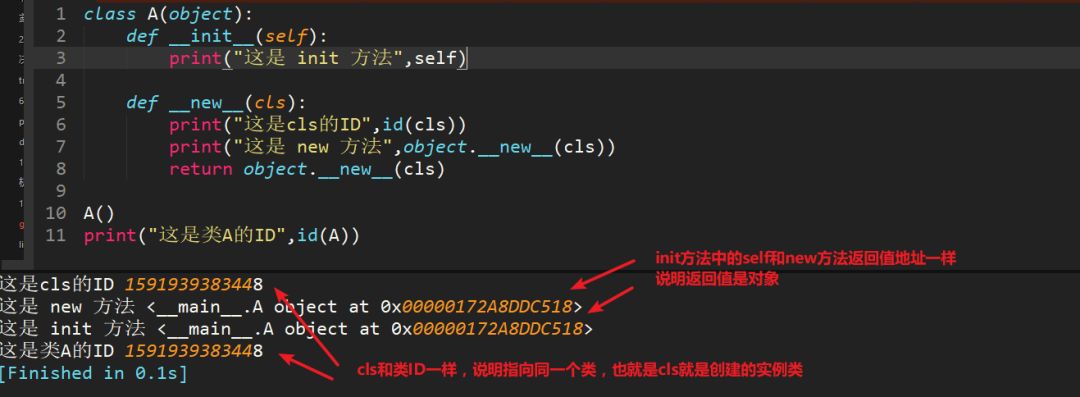
1、__new__至少要有一個參數cls,代表當前類,此參數在實例化時由Python解釋器自動識別
2、__new__必須要有返回值,返回實例化出來的實例,這點在自己實現__new__時要特別注意,可以return父類(通過super(當前類名, cls))__new__出來的實例,或者直接是object的__new__出來的實例
3、__init__有一個參數self,就是這個__new__返回的實例,__init__在__new__的基礎上可以完成一些其它初始化的動作,__init__不需要返回值
4、如果__new__創建的是當前類的實例,會自動調用__init__函數,通過return語句里面調用的__new__函數的第一個參數是cls來保證是當前類實例,如果是其他類的類名,;那么實際創建返回的就是其他類的實例,其實就不會調用當前類的__init__函數,也不會調用其他類的__init__函數。
12、簡述with方法打開處理文件幫我我們做了什么?
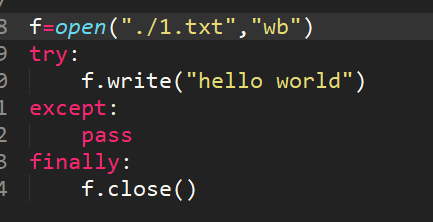
打開文件在進行讀寫的時候可能會出現一些異常狀況,如果按照常規的f.open
寫法,我們需要try,except,finally,做異常判斷,并且文件最終不管遇到什么情況,都要執行finally f.close()關閉文件,with方法幫我們實現了finally中f.close
(當然還有其他自定義功能,有興趣可以研究with方法源碼)
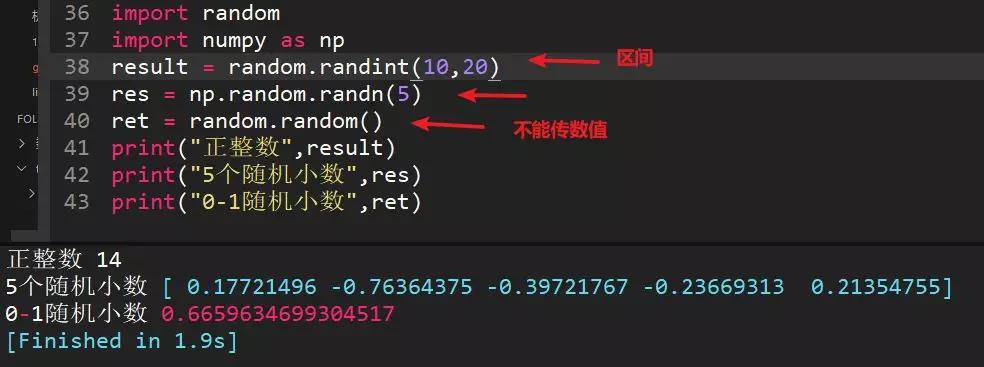
13、python中生成隨機整數、隨機小數、0--1之間小數方法
隨機整數:random.randint(a,b),生成區間內的整數
隨機小數:習慣用numpy庫,利用np.random.randn(5)生成5個隨機小數
0-1隨機小數:random.random(),括號中不傳參
14、避免轉義給字符串加哪個字母表示原始字符串?
r , 表示需要原始字符串,不轉義特殊字符
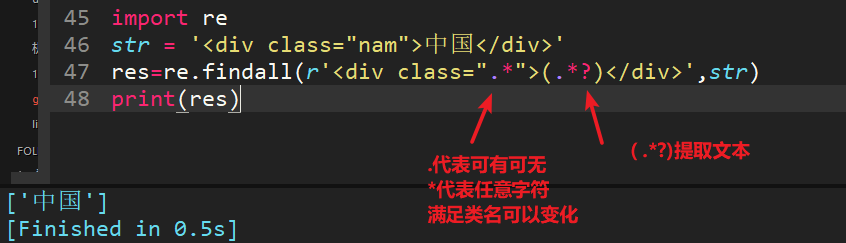
15、<div class="nam">中國</div>,用正則匹配出標簽里面的內容(“中國”),其中class的類名是不確定的
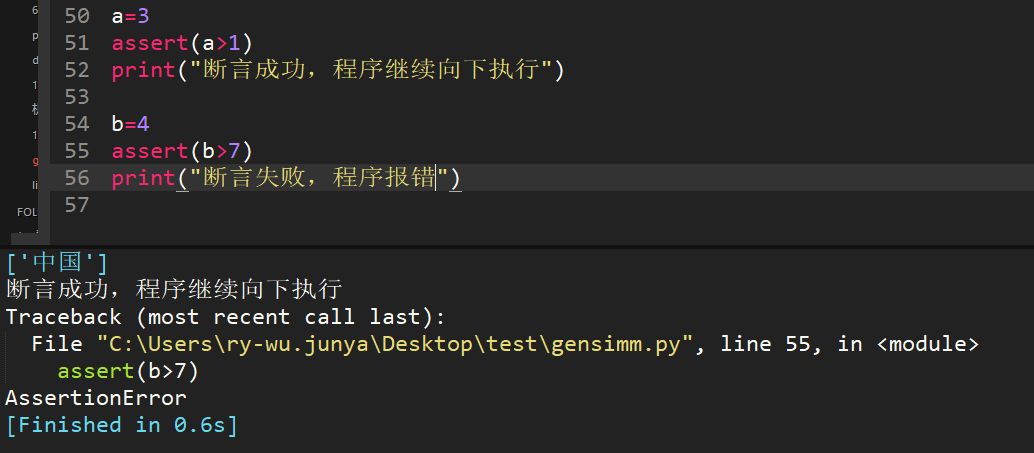
16、python中斷言方法舉例
assert()方法,斷言成功,則程序繼續執行,斷言失敗,則程序報錯
17、python2和python3區別?列舉5個
1、Python3 使用 print 必須要以小括號包裹打印內容,比如?print('hi')
Python2 既可以使用帶小括號的方式,也可以使用一個空格來分隔打印內容,比如?print 'hi'
2、python2 range(1,10)返回列表,python3中返回迭代器,節約內存
3、python2中使用ascii編碼,python中使用utf-8編碼
4、python2中unicode表示字符串序列,str表示字節序列
python3中str表示字符串序列,byte表示字節序列
5、python2中為正常顯示中文,引入coding聲明,python3中不需要
6、python2中是raw_input()函數,python3中是input()函數
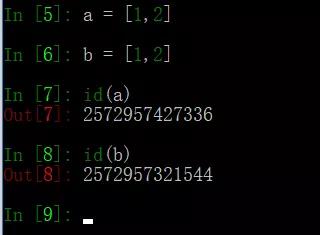
18、列出python中可變數據類型和不可變數據類型,并簡述原理
不可變數據類型:數值型、字符串型string和元組tuple
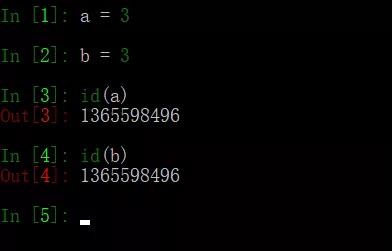
不允許變量的值發生變化,如果改變了變量的值,相當于是新建了一個對象,而對于相同的值的對象,在內存中則只有一個對象(一個地址),如下圖用id()方法可以打印對象的id
可變數據類型:列表list和字典dict;
允許變量的值發生變化,即如果對變量進行append、+=等這種操作后,只是改變了變量的值,而不會新建一個對象,變量引用的對象的地址也不會變化,不過對于相同的值的不同對象,在內存中則會存在不同的對象,即每個對象都有自己的地址,相當于內存中對于同值的對象保存了多份,這里不存在引用計數,是實實在在的對象。
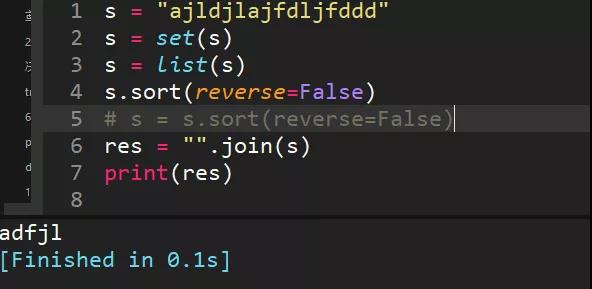
19、s = "ajldjlajfdljfddd",去重并從小到大排序輸出"adfjl"
set去重,去重轉成list,利用sort方法排序,reeverse=False是從小到大排
list是不?變數據類型,s.sort時候沒有返回值,所以注釋的代碼寫法不正確
20、用lambda函數實現兩個數相乘

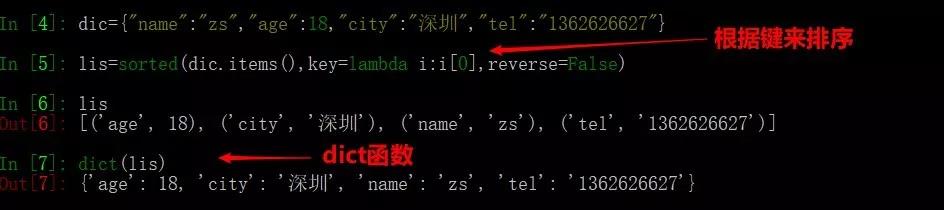
21、字典根據鍵從小到大排序
dic={"name":"zs","age":18,"city":"深圳","tel":"1362626627"}
22、利用collections庫的Counter方法統計字符串每個單詞出現的次數"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"
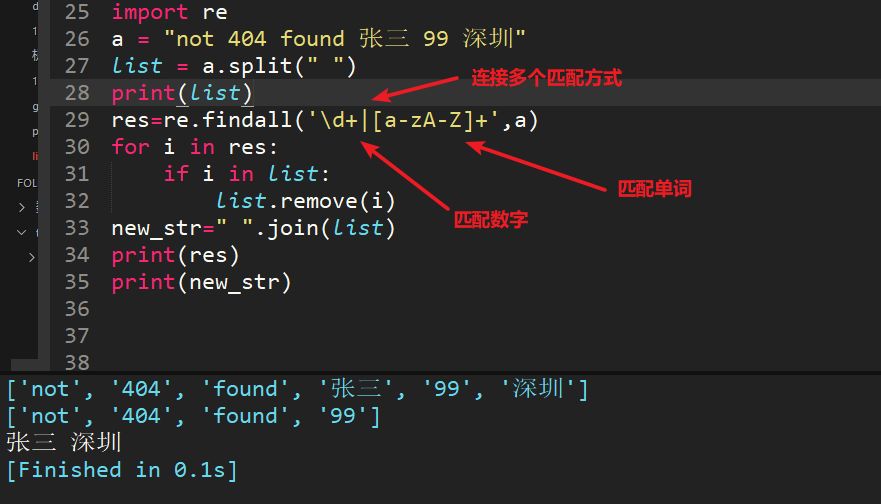
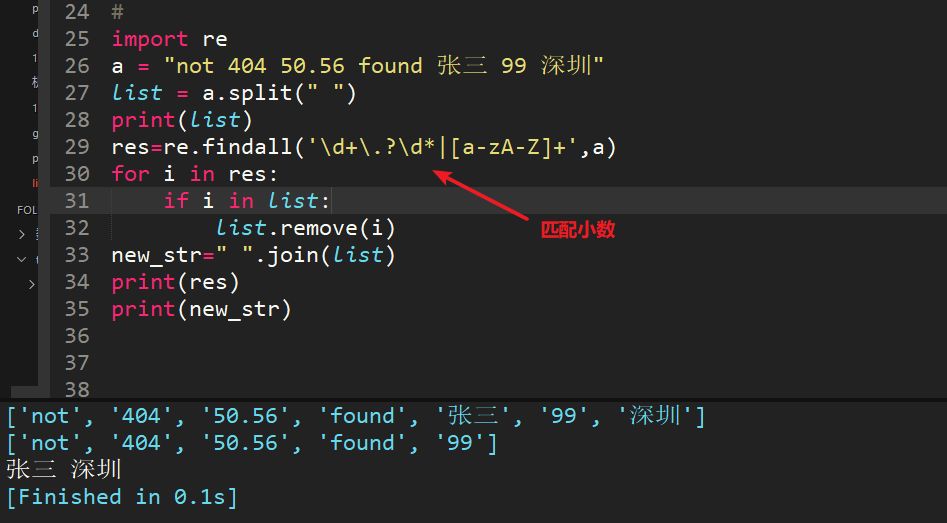
 23、字符串a = "not 404 found 張三 99 深圳",每個詞中間是空格,用正則過濾掉英文和數字,最終輸出 "張三 ?深圳"
23、字符串a = "not 404 found 張三 99 深圳",每個詞中間是空格,用正則過濾掉英文和數字,最終輸出 "張三 ?深圳"
 順便貼上匹配小數的代碼,雖然能匹配,但是健壯性有待進一步確認
順便貼上匹配小數的代碼,雖然能匹配,但是健壯性有待進一步確認
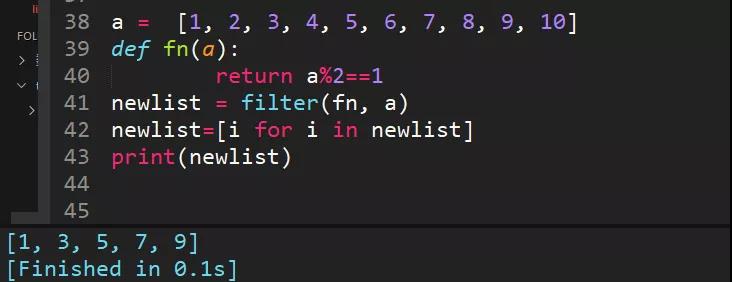
24、filter方法求出列表所有奇數并構造新列表,a = ?[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
filter()?函數用于過濾序列,過濾掉不符合條件的元素,返回由符合條件元素組成的新列表。該接收兩個參數,第一個為函數,第二個為序列,序列的每個元素作為參數傳遞給函數進行判,然后返回 True 或 False,最后將返回 True 的元素放到新列表
25、列表推導式求列表所有奇數并構造新列表,a = ?[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
26、正則re.complie作用
re.compile是將正則表達式編譯成一個對象,加快速度,并重復使用。
27、a=(1,)b=(1),c=("1") 分別是什么類型的數據?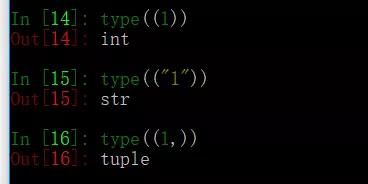
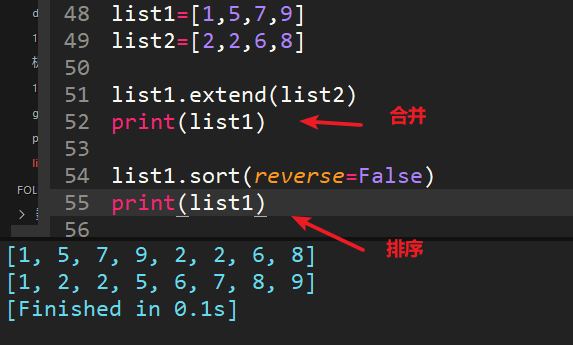
28、兩個列表[1,5,7,9]和[2,2,6,8]合并為[1,2,2,3,6,7,8,9]
extend可以將另一個集合中的元素逐一添加到列表中,區別于append整體添加。
29、log日志中,我們需要用時間戳記錄error,warning等的發生時間,請用datetime模塊打印當前時間戳 “2018-04-01 11:38:54”
順便把星期的代碼也貼上了。

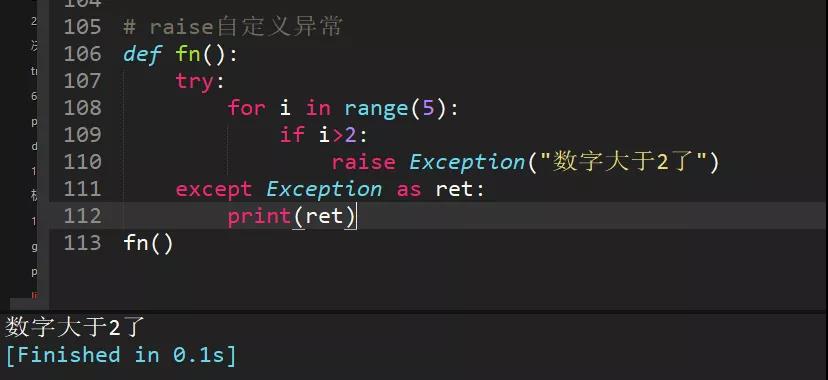
30、寫一段自定義異常代碼
自定義異常用raise拋出異常。
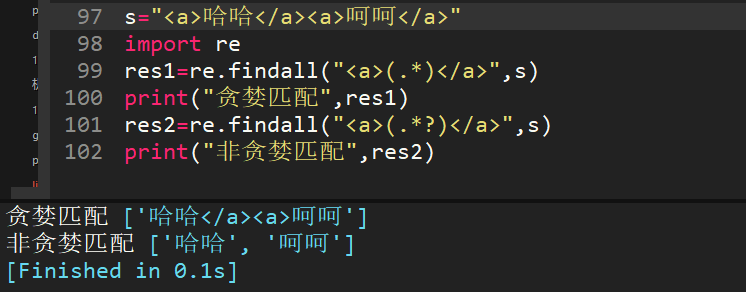
31、正則表達式匹配中,(.*)和(.*?)匹配區別?
(.*)是貪婪匹配,會把滿足正則的盡可能多的往后匹配。
(.*?)是非貪婪匹配,會把滿足正則的盡可能少匹配。
32、簡述Django的orm
ORM,全拼Object-Relation Mapping,意為對象-關系映射。
實現了數據模型與數據庫的解耦,通過簡單的配置就可以輕松更換數據庫,而不需要修改代碼只需要面向對象編程,orm操作本質上會根據對接的數據庫引擎,翻譯成對應的sql語句,所有使用Django開發的項目無需關心程序底層使用的是MySQL、Oracle、sqlite....,如果數據庫遷移,只需要更換Django的數據庫引擎即可。
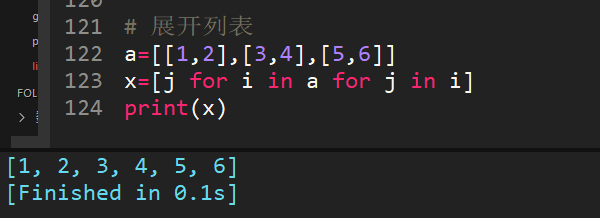
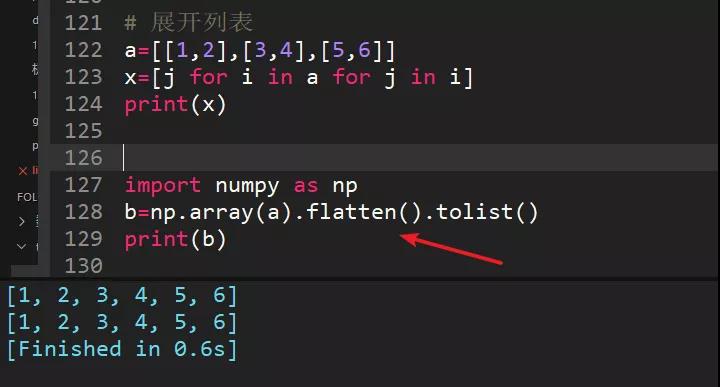
33、[[1,2],[3,4],[5,6]]一行代碼展開該列表,得出[1,2,3,4,5,6]
列表推導式的騷操作。
運行過程:for i in a ,每個i是【1,2】,【3,4】,【5,6】,for j in i,每個j就是1,2,3,4,5,6,合并后就是結果。
還有更騷的方法,將列表轉成numpy矩陣,通過numpy的flatten()方法,代碼永遠是只有更騷,沒有最騷。
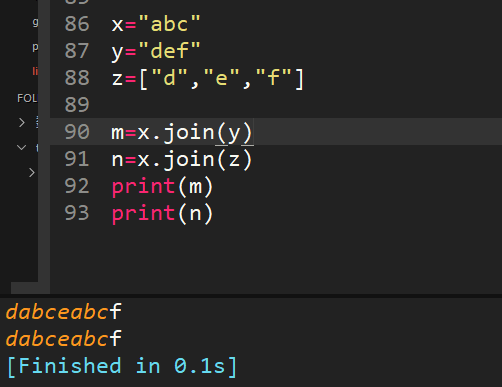
34、x="abc",y="def",z=["d","e","f"],分別求出x.join(y)和x.join(z)返回的結果
join()括號里面的是可迭代對象,x插入可迭代對象中間,形成字符串,結果一致,有沒有突然感覺字符串的常見操作都不會玩了。
順便建議大家學下os.path.join()方法,拼接路徑經常用到,也用到了join,和字符串操作中的join有什么區別,該問題大家可以查閱相關文檔,后期會有答案。
35、舉例說明異常模塊中try except else finally的相關意義
try..except..else沒有捕獲到異常,執行else語句。
try..except..finally不管是否捕獲到異常,都執行finally語句。

36、舉例說明zip()函數用法
zip()函數在運算時,會以一個或多個序列(可迭代對象)做為參數,返回一個元組的列表。同時將這些序列中并排的元素配對。
zip()參數可以接受任何類型的序列,同時也可以有兩個以上的參數;當傳入參數的長度不同時,zip能自動以最短序列長度為準進行截取,獲得元組。
37、a="張明 98分",用re.sub,將98替換為100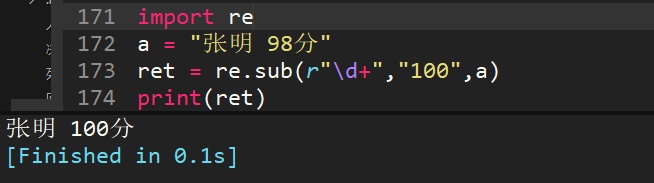
38、a="hello"和b="你好"編碼成bytes類型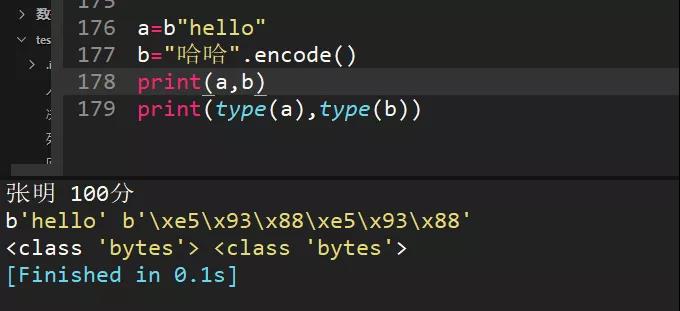
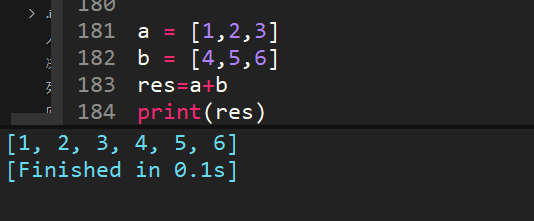
39、[1,2,3]+[4,5,6]的結果是多少?
兩個列表相加,等價于extend。
40、提高python運行效率的方法
1、使用生成器,因為可以節約大量內存;
2、循環代碼優化,避免過多重復代碼的執行;
3、核心模塊用Cython ?PyPy等,提高效率;
4、多進程、多線程、協程;
5、多個if elif條件判斷,可以把最有可能先發生的條件放到前面寫,這樣可以減少程序判斷的次數,提高效率。
41、遇到bug如何處理
1、細節上的錯誤,通過print()打印,能執行到print()說明一般上面的代碼沒有問題,分段檢測程序是否有問題,如果是js的話可以alert或console.log
2、如果涉及一些第三方框架,會去查官方文檔或者一些技術博客。
3、對于bug的管理與歸類總結,一般測試將測試出的bug用teambin等bug管理工具進行記錄,然后我們會一條一條進行修改,修改的過程也是理解業務邏輯和提高自己編程邏輯縝密性的方法,我也都會收藏做一些筆記記錄。
4、導包問題、城市定位多音字造成的顯示錯誤問題。
42、正則匹配,匹配日期2018-03-20
url='https://sycm.taobao.com/bda/tradinganaly/overview/get_summary.json?dateRange=2018-03-20%7C2018-03-20&dateType=recent1&device=1&token=ff25b109b&_=1521595613462'
仍有同學問正則,其實匹配并不難,提取一段特征語句,用(.*?)匹配即可。

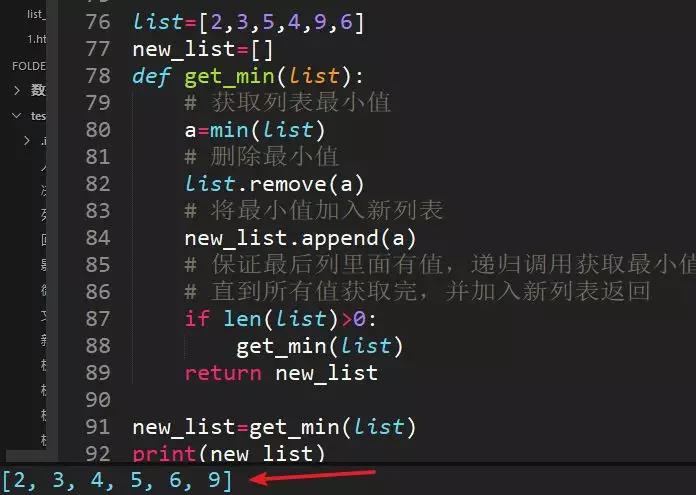
43、list=[2,3,5,4,9,6],從小到大排序,不許用sort,輸出[2,3,4,5,6,9]
利用min()方法求出最小值,原列表刪除最小值,新列表加入最小值,遞歸調用獲取最小值的函數,反復操作。
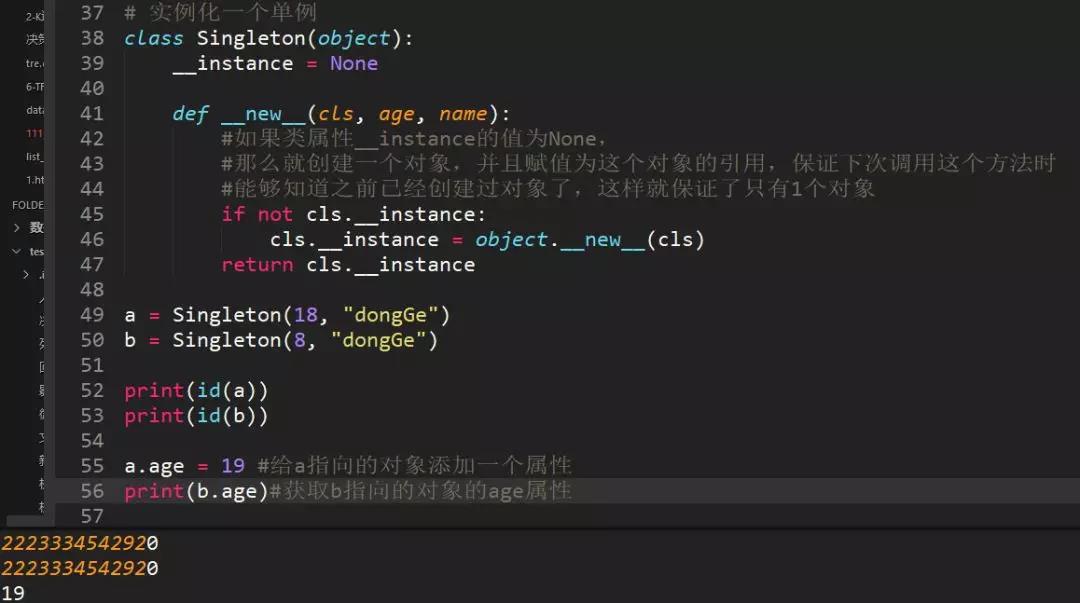
44、寫一個單列模式
因為創建對象時__new__方法執行,并且必須return 返回實例化出來的對象所cls.__instance是否存在,不存在的話就創建對象,存在的話就返回該對象,來保證只有一個實例對象存在(單列),打印ID,值一樣,說明對象同一個。
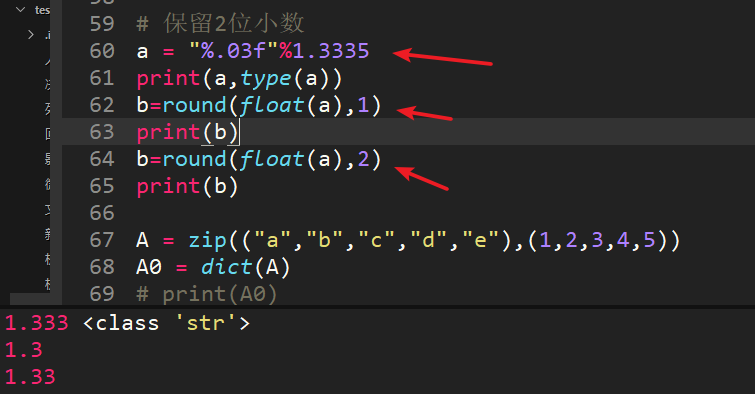
45、保留兩位小數
題目本身只有a="%.03f"%1.3335,讓計算a的結果,為了擴充保留小數的思路,提供round方法(數值,保留位數)。
46、求三個方法打印結果
fn("one",1)直接將鍵值對傳給字典。
fn("two",2)因為字典在內存中是可變數據類型,所以指向同一個地址,傳了新的額參數后,會相當于給字典增加鍵值對。
fn("three",3,{})因為傳了一個新字典,所以不再是原先默認參數的字典。
47、分別從前端、后端、數據庫闡述web項目的性能優化
該題目網上有很多方法,我不想截圖網上的長串文字,看的頭疼,按我自己的理解說幾點。
前端優化:
1、減少http請求、例如制作精靈圖;
2、html和CSS放在頁面上部,javascript放在頁面下面,因為js加載比HTML和Css加載慢,所以要優先加載html和css,以防頁面顯示不全,性能差,也影響用戶體驗差。
后端優化:
1、緩存存儲讀寫次數高,變化少的數據,比如網站首頁的信息、商品的信息等。應用程序讀取數據時,一般是先從緩存中讀取,如果讀取不到或數據已失效,再訪問磁盤數據庫,并將數據再次寫入緩存;
2、異步方式,如果有耗時操作,可以采用異步,比如celery;
3、代碼優化,避免循環和判斷次數太多,如果多個if else判斷,優先判斷最有可能先發生的情況。
數據庫優化:
1、如有條件,數據可以存放于redis,讀取速度快;
2、建立索引、外鍵等。
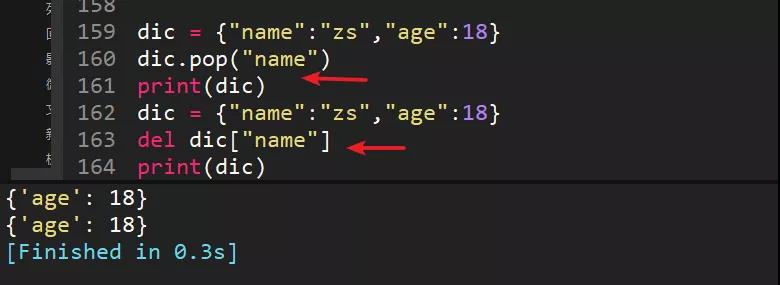
48、使用pop和del刪除字典中的"name"字段,dic={"name":"zs","age":18}
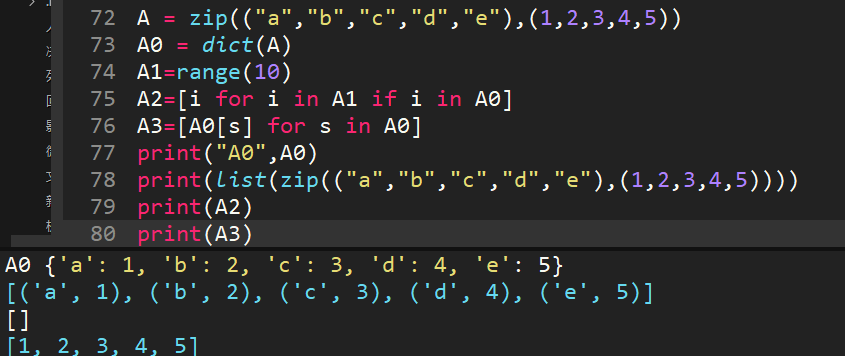
dict()創建字典新方法。
50、簡述同源策略
同源策略需要同時滿足以下三點要求:
1)協議相同
2)域名相同
3)端口相同
http:www.test.com與https:www.test.com 不同源——協議不同
http:www.test.com與http:www.admin.com 不同源——域名不同
http:www.test.com與http:www.test.com:8081 不同源——端口不同
只要不滿足其中任意一個要求,就不符合同源策略,就會出現“跨域”。
51、簡述cookie和session的區別
1,session 在服務器端,cookie 在客戶端(瀏覽器);
2、session 的運行依賴 session id,而 session id 是存在 cookie 中的,也就是說,如果瀏覽器禁用了 cookie ,同時 session 也會失效,存儲Session時,鍵與Cookie中的sessionid相同,值是開發人員設置的鍵值對信息,進行了base64編碼,過期時間由開發人員設置;
3、cookie安全性比session差。
52、簡述多線程、多進程
進程:
1、操作系統進行資源分配和調度的基本單位,多個進程之間相互獨立;
2、穩定性好,如果一個進程崩潰,不影響其他進程,但是進程消耗資源大,開啟的進程數量有限制。
線程:
1、CPU進行資源分配和調度的基本單位,線程是進程的一部分,是比進程更小的能獨立運行的基本單位,一個進程下的多個線程可以共享該進程的所有資源;
2、如果IO操作密集,則可以多線程運行效率高,缺點是如果一個線程崩潰,都會造成進程的崩潰。
應用:
1、IO密集的用多線程,在用戶輸入,sleep 時候,可以切換到其他線程執行,減少等待的時間;
2、CPU密集的用多進程,因為假如IO操作少,用多線程的話,因為線程共享一個全局解釋器鎖,當前運行的線程會霸占GIL,其他線程沒有GIL,就不能充分利用多核CPU的優勢。
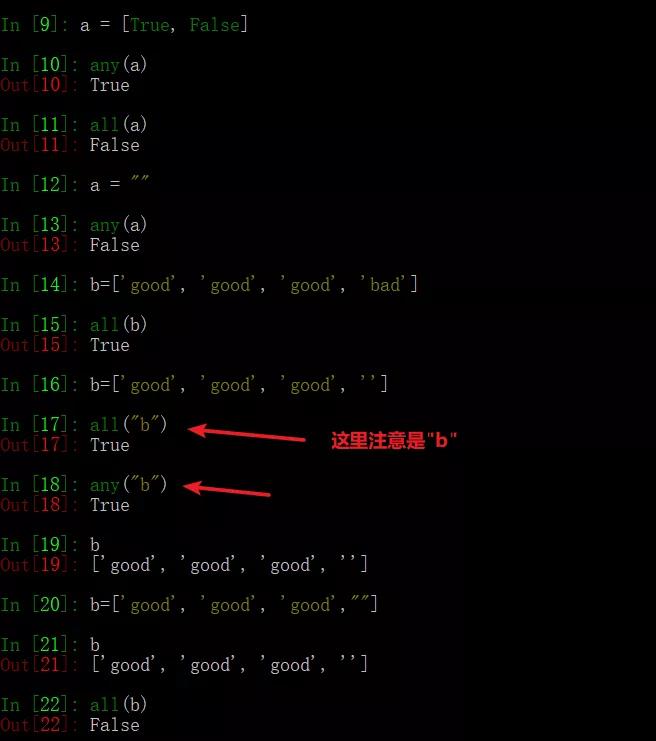
53、簡述any()和all()方法
any():只要迭代器中有一個元素為真就為真。
all():迭代器中所有的判斷項返回都是真,結果才為真。
python中什么元素為假?
答案:(0,空字符串,空列表、空字典、空元組、None, False)
測試all()和any()方法。
54、IOError、AttributeError、ImportError、IndentationError、IndexError、KeyError、SyntaxError、NameError分別代表什么異常
IOError:輸入輸出異常。
AttributeError:試圖訪問一個對象沒有的屬性。
ImportError:無法引入模塊或包,基本是路徑問題。
IndentationError:語法錯誤,代碼沒有正確的對齊。
IndexError:下標索引超出序列邊界。
KeyError:試圖訪問你字典里不存在的鍵。
SyntaxError:Python代碼邏輯語法出錯,不能執行。
NameError:使用一個還未賦予對象的變量。
55、python中copy和deepcopy區別
1、復制不可變數據類型,不管copy還是deepcopy,都是同一個地址當淺復制的值是不可變對象(數值,字符串,元組)時和=“賦值”的情況一樣,對象的id值與淺復制原來的值相同。
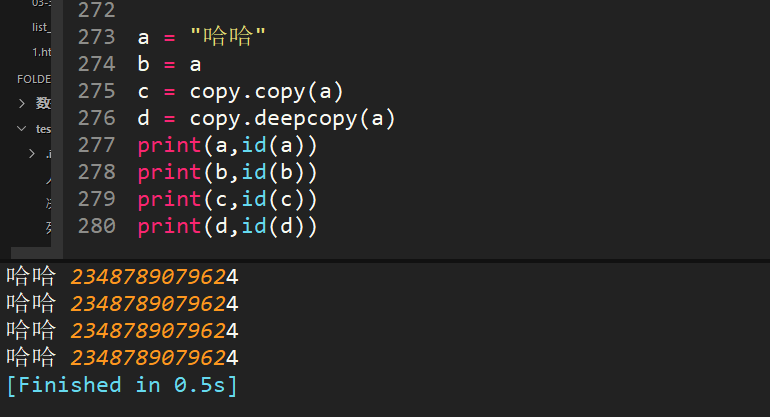
2、復制的值是可變對象(列表和字典)
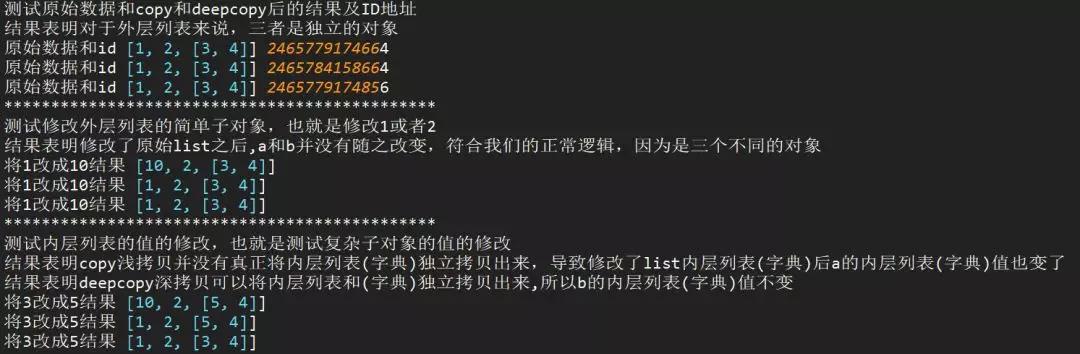
淺拷貝copy有兩種情況:
第一種情況:復制的?對象中無 復雜 子對象,原來值的改變并不會影響淺復制的值,同時淺復制的值改變也并不會影響原來的值。原來值的id值與淺復制原來的值不同。
第二種情況:復制的對象中有 復雜 子對象?(例如列表中的一個子元素是一個列表),?改變原來的值 中的復雜子對象的值??,會影響淺復制的值。
深拷貝deepcopy:完全復制獨立,包括內層列表和字典。
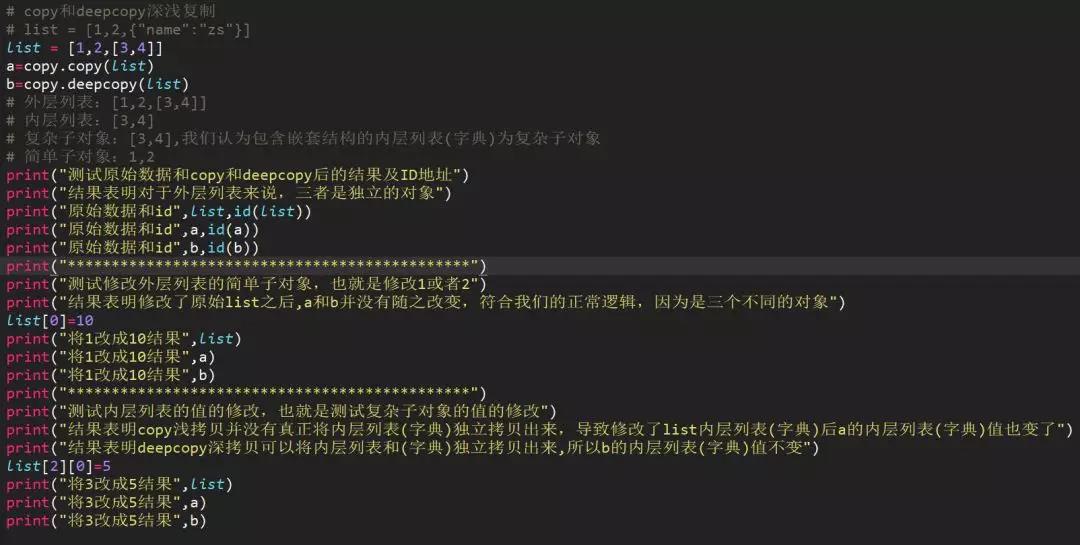
56、列出幾種魔法方法并簡要介紹用途
__init__:對象初始化方法
__new__:創建對象時候執行的方法,單列模式會用到
__str__:當使用print輸出對象的時候,只要自己定義了__str__(self)方法,那么就會打印從在這個方法中return的數據
__del__:刪除對象執行的方法
57、C:\Users\ry-wu.junya\Desktop>python 1.py 22 33命令行啟動程序并傳參,print(sys.argv)會輸出什么數據?
文件名和參數構成的列表。
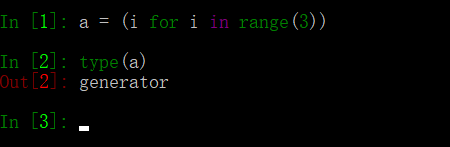
58、請將[i for i in range(3)]改成生成器
生成器是特殊的迭代器:
1、列表表達式的【】改為()即可變成生成器;
2、函數在返回值得時候出現yield就變成生成器,而不是函數了。
中括號換成小括號即可,有沒有驚呆了
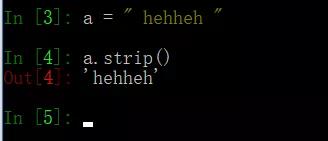
59、a = " ?hehheh ?",去除收尾空格
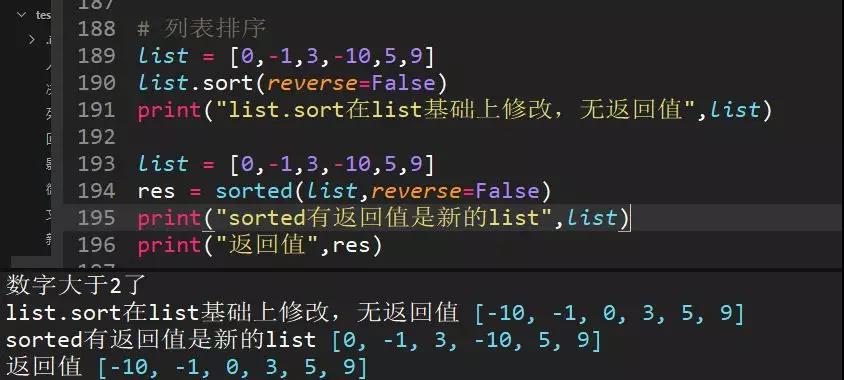
60、舉例sort和sorted對列表排序,list=[0,-1,3,-10,5,9]
經典python面試題匯總,共計150+道。掃描下方二維碼免費領取!

文章來源于網絡,侵刪!