

【圖文詳解】python基礎爬蟲實戰——5分鐘做個圖片自動下載器



我想要(下)的,我現在就要
Python爬蟲實戰——圖片自動下載器
之前介紹了那么多基本知識【Python爬蟲】入門知識(沒看的趕緊去看)大家也估計手癢了。想要實際做個小東西來看看,畢竟:
talk is cheap show me the code!
這個小工程的代碼都在github上,感興趣的自己去下載:
https://github.com/hk029/Pickup
制作爬蟲的基本步驟
順便通過這個小例子,可以掌握一些有關制作爬蟲的基本的步驟。
一般來說,制作一個爬蟲需要分以下幾個步驟:
-
分析需求(對,需求分析非常重要,不要告訴我你老師沒教你)
-
分析網頁源代碼,配合F12(沒有F12那么亂的網頁源代碼,你想看死我?)
-
編寫正則表達式或者XPath表達式(就是前面說的那個神器)
-
正式編寫Python爬蟲代碼
效果
運行:

恩,讓我輸入關鍵詞,讓我想想,輸入什么好呢?好像有點暴露愛好了。

回車

好像開始下載了!好贊!,我看看下載的圖片,哇瞬間我感覺我又補充了好多表情包....
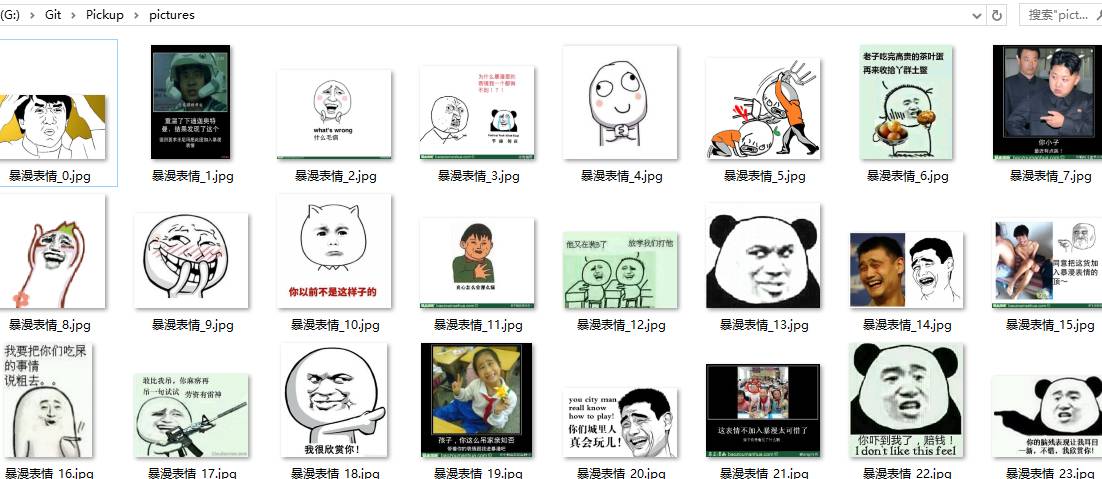
好了,差不多就是這么個東西。
需求分析
"我想要圖片,我又不想上網搜“
"最好還能自動下載"
……
這就是需求,好了,我們開始分析需求,至少要實現兩個功能,一是搜索圖片,二是自動下載。
首先,搜索圖片,最容易想到的就是爬百度圖片的結果,好,那我們就上百度圖片看看
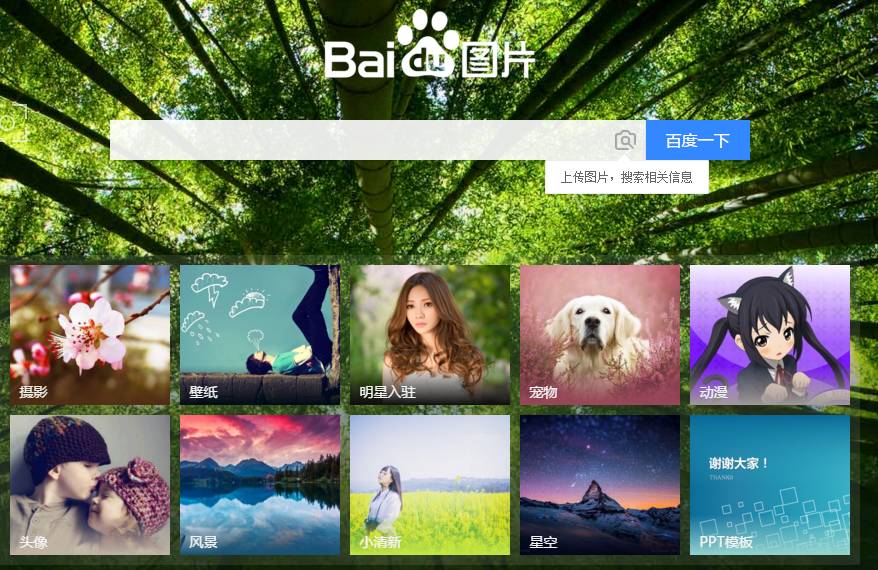
基本就是這樣,還挺漂亮的。
我們試著搜一個東西,我打一個暴字,出來一系列搜索結果,這說明什么....
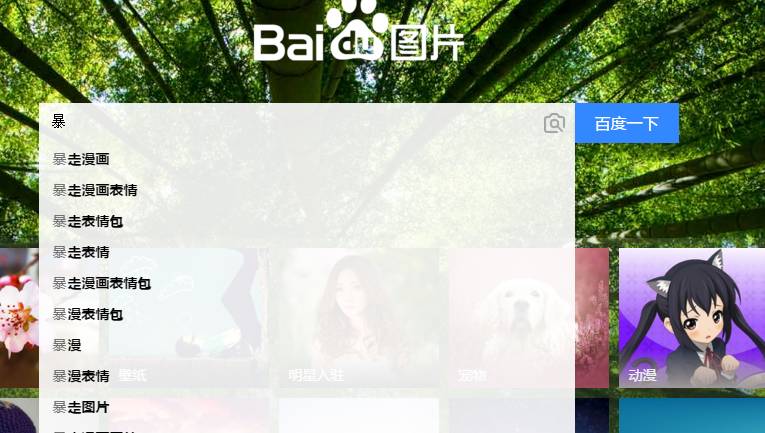
隨便找一個回車
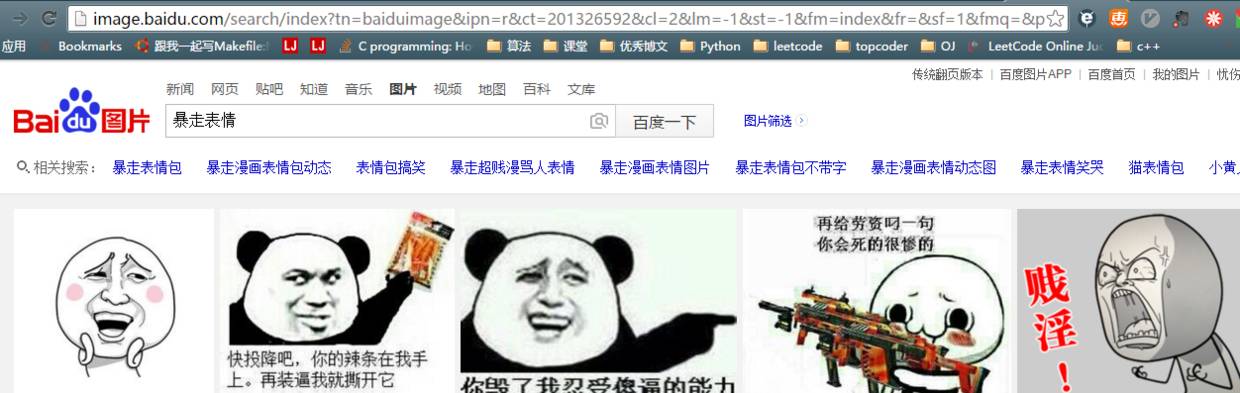
好了,我們已經看到了很多圖片了,如果我們能把這里面的圖片都爬下來就好了。我們看見網址里有關鍵詞信息

我們試著在網址直接換下關鍵詞,跳轉了有沒有!
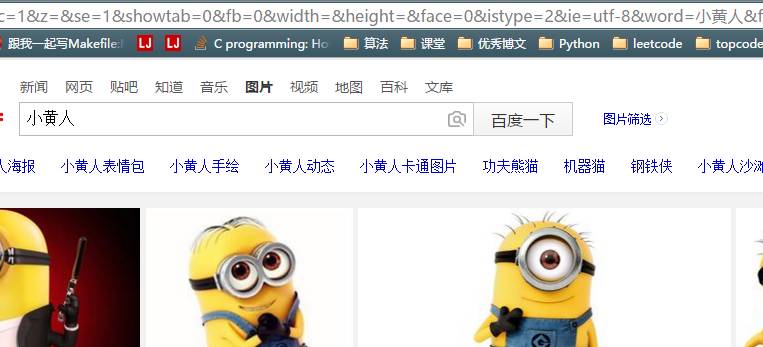
這樣,可以通過這個網址查找特定的關鍵詞的圖片,所以理論上,我們可以不用打開網頁就能搜索特定的圖片了。下個問題就是如何實現自動下載,其實利用之前的知識,我們知道可以用request,獲取圖片的網址,然后把它爬下來,保存成.jpg就行了。
所以這個項目就應該可以完成了。
分析網頁
好了,我們開始做下一步,分析網頁源代碼。這里 我先切換回傳統頁面,為什么這樣做,因為目前百度圖片采用的是瀑布流模式,動態加載圖片,處理起來很麻煩,傳統的翻頁界面就好很多了。

這里還一個技巧,就是:能爬手機版就不要爬電腦版,因為手機版的代碼很清晰,很容易獲取需要的內容。
好了,切換回傳統版本了,還是有頁碼的看的舒服。
我們點擊右鍵,查看源代碼
這都是什么鬼,怎么可能看清!!

這個時候,就要用F12了,開發者工具!我們回到上一頁面,按F12,出來下面這個工具欄,我們需要用的就是左上角那個東西,一個是鼠標跟隨,一個是切換手機版本,都對我們很有用。我們這里用第一個

然后選擇你想看源代碼的地方,就可以發現,下面的代碼區自動定位到了這個位置,是不是很NB!
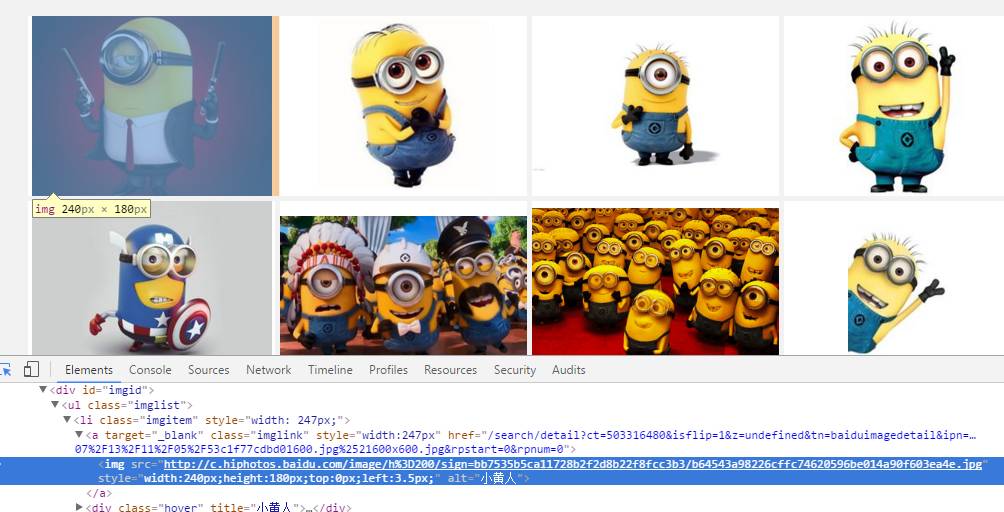
我們復制這個地址

然后到剛才的亂七八糟的源代碼里搜索一下,發現它的位置了!(小樣!我還找不到你!)但是這里我們又疑惑了,這個圖片怎么有這么多地址,到底用哪個呢?我們可以看到有thumbURL,middleURL,hoverURL,objURL

通過分析可以知道,前面兩個是縮小的版本,hover是鼠標移動過后顯示的版本,objURL應該是我們需要的,不信可以打開這幾個網址看看,發現obj那個最大最清晰。
好了,找到了圖片位置,我們就開始分析它的代碼。我看看是不是所有的objURL全是圖片
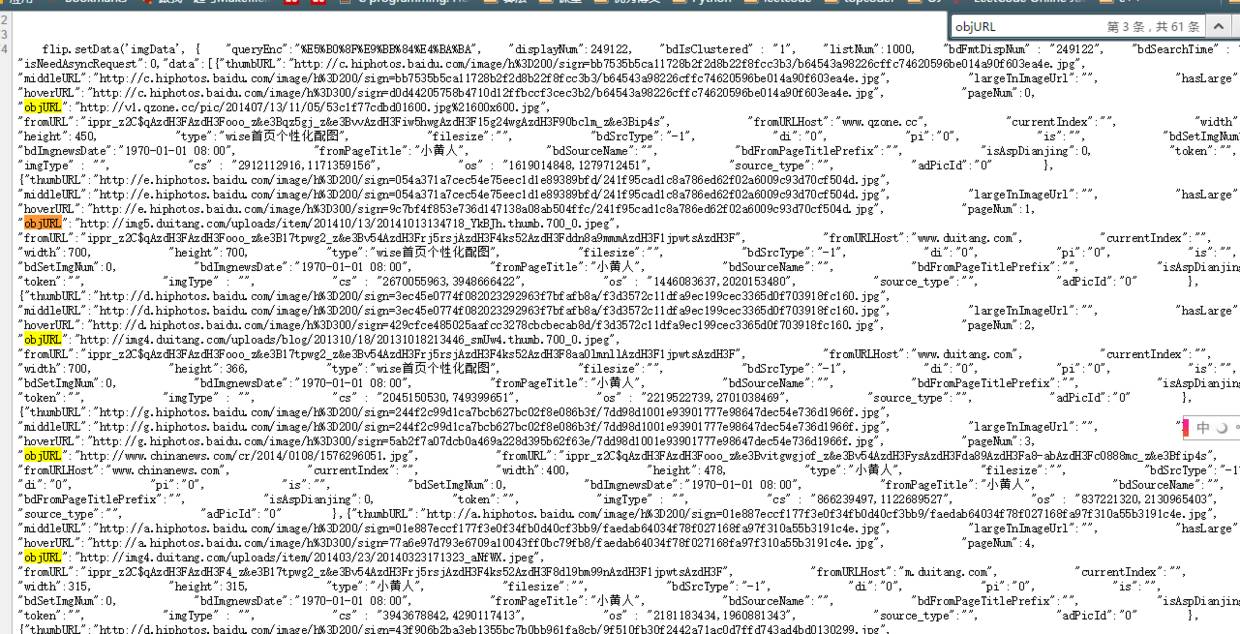
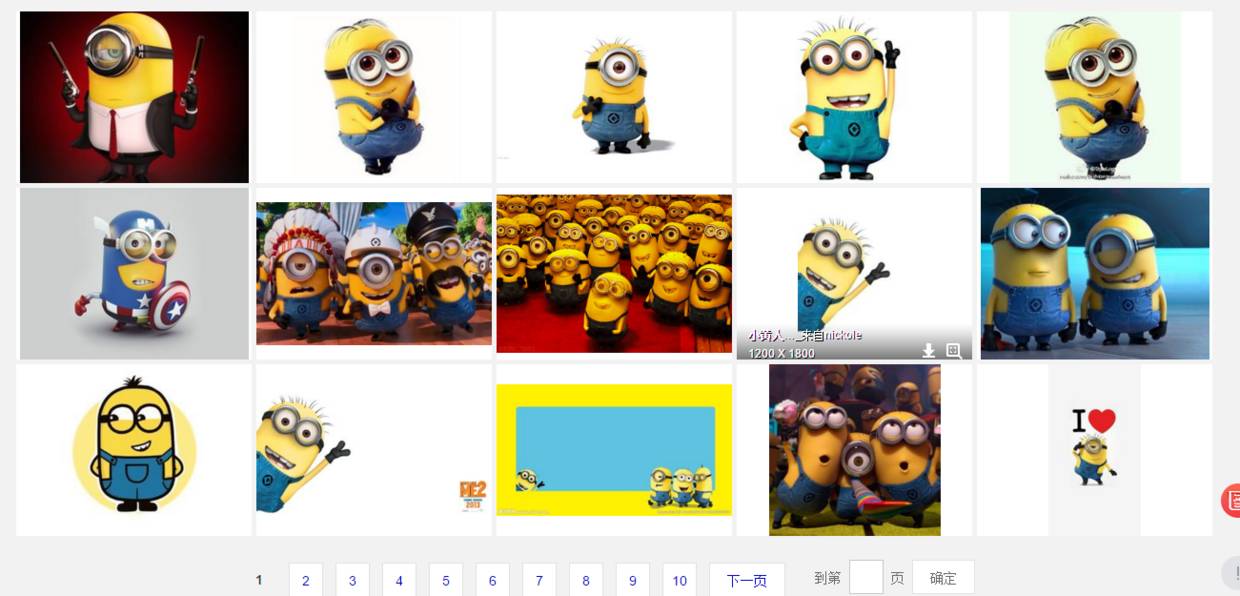
貌似都是以.jpg格式結尾的,那應該跑不了了,我們可以看到搜索出61條,說明應該有61個圖片
編寫正則表達式
通過前面的學習,寫出如下的一條正則表達式不難把?

編寫爬蟲代碼
好了,正式開始編寫爬蟲代碼了。這里我們就用了2個包,一個是正則,一個是requests包,之前也介紹過了,沒看的回去看!

然后我們把剛才的網址粘過來,傳入requests,然后把正則表達式寫好

理論有很多圖片,所以要循環,我們打印出結果來看看,然后用request獲取網址,這里由于有些圖片可能存在網址打不開的情況,加個5秒超時控制。

好了,再就是把網址保存下來,我們在事先在當前目錄建立一個picture目錄,把圖片都放進去,命名的時候,用數字命名把

整個代碼就是這樣:

我們運行一下,看效果
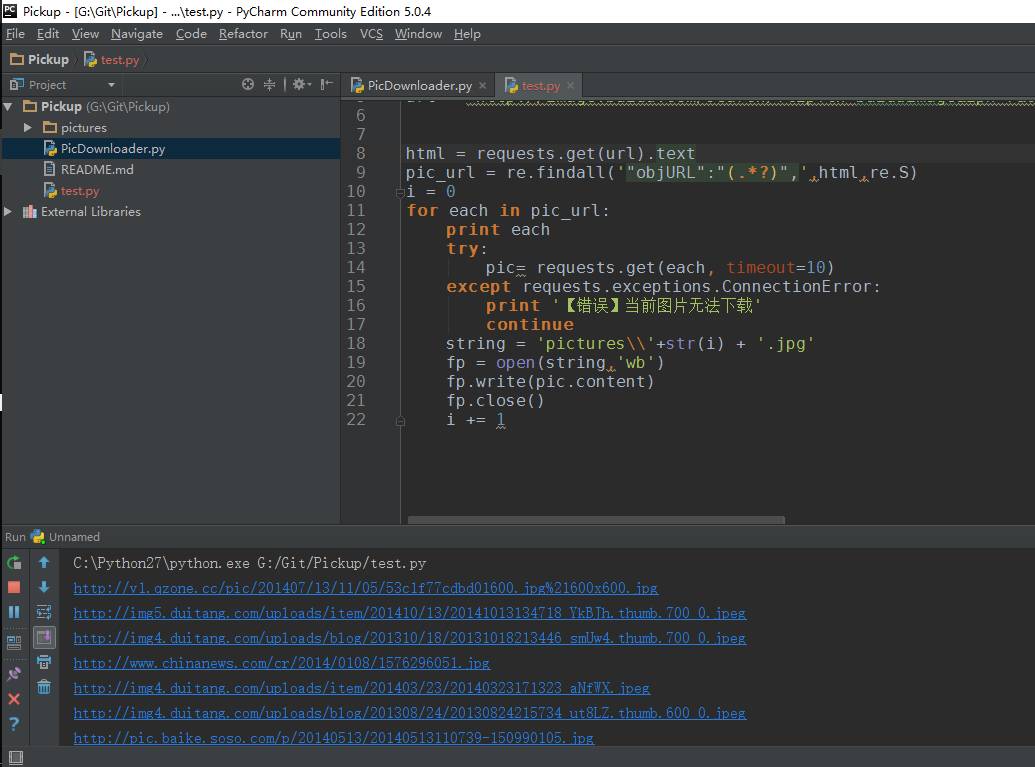
好了我們下載了58個圖片,咦剛才不是應該是61個嗎?
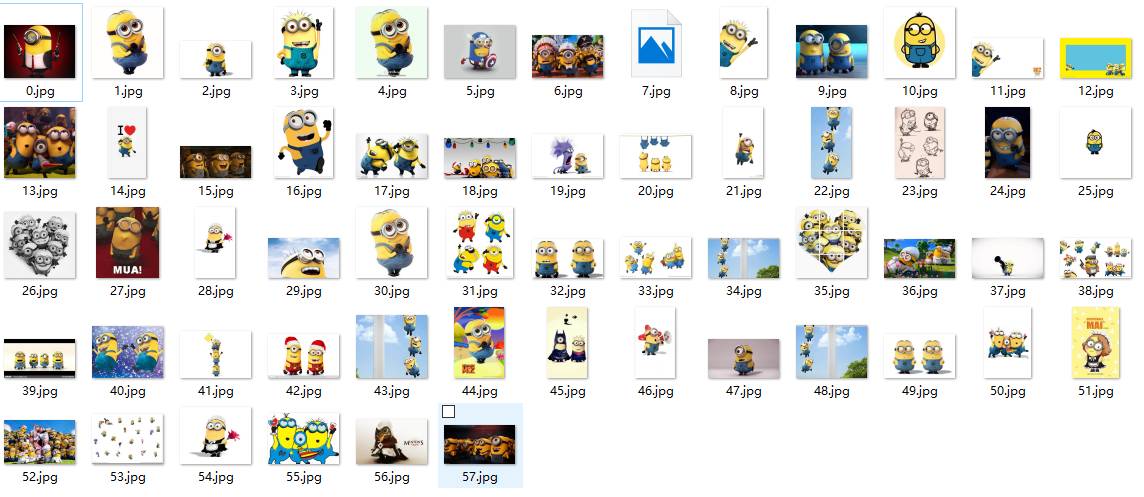
我們看,運行中出現了有一些圖片下載不了
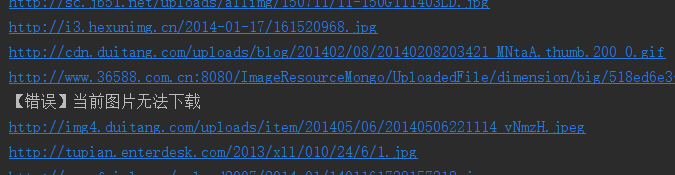
我們還看到有圖片沒顯示出來,打開網址看,發現確實沒了。
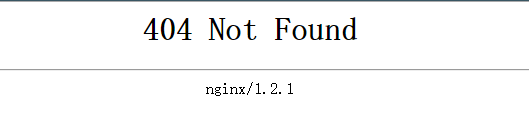
所以,百度有些圖片它緩存到了自己的機器上,所以你還能看見,但是實際連接已經失效
好了,現在自動下載問題解決了,那根據關鍵詞搜索圖片呢?只要改url就行了,我這里把代碼寫下來了

好了,享受你第一個圖片下載爬蟲吧!!當然不只能下載百度的圖片拉,依葫蘆畫瓢,你現在應該做很多事情了,比如爬取頭像,爬淘寶展示圖,或是...美女圖片,捂臉。一切都憑客官你的想象了,當然,作為爬蟲的第一個實例,雖然純用request已經能解決很多問題了,但是效率還是不夠高,如果想要高效爬取大量數據,還是用scrapy吧。
這個小工程的代碼都在github上,感興趣的自己去下載:
https://github.com/hk029/Pickup
作者:voidsky_很有趣兒
來源:http://www.jianshu.com/p/19c846daccb3
————廣告時間————
馬哥教育2017年Python自動化運維開發實戰班,馬哥聯合BAT、豆瓣等一線互聯網Python開發達人,根據目前企業需求的Python開發人才進行了深度定制,加入了大量一線互聯網公司:大眾點評、餓了么、騰訊等生產環境真是項目,課程由淺入深,從Python基礎到Python高級,讓你融匯貫通Python基礎理論,手把手教學讓你具備Python自動化開發需要的前端界面開發、Web框架、大監控系統、CMDB系統、認證堡壘機、自動化流程平臺六大實戰能力,讓你從0開始蛻變成Hold住年薪20萬的Python自動化開發人才。
掃描二維碼和更多小伙伴組團學習


