

協程,又稱微線程,纖程。英文名Coroutine。一句話說明什么是線程:協程是一種用戶態的輕量級線程。(其實并沒有說明白~)
那么這么來理解協程比較容易:
線程是系統級別的,它們是由操作系統調度;協程是程序級別的,由程序員根據需要自己調度。我們把一個線程中的一個個函數叫做子程序,那么子程序在執行過程中可以中斷去執行別的子程序;別的子程序也可以中斷回來繼續執行之前的子程序,這就是協程。也就是說同一線程下的一段代碼執行著執行著就可以中斷,然后跳去執行另一段代碼,當再次回來執行代碼塊的時候,接著從之前中斷的地方開始執行。
比較專業的理解是:
協程擁有自己的寄存器上下文和棧。協程調度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧。因此:協程能保留上一次調用時的狀態(即所有局部狀態的一個特定組合),每次過程重入時,就相當于進入上一次調用的狀態,換種說法:進入上一次離開時所處邏輯流的位置。
協程的優點:
-
無需線程上下文切換的開銷,協程避免了無意義的調度,由此可以提高性能(但也因此,程序員必須自己承擔調度的責任,同時,協程也失去了標準線程使用多CPU的能力)
-
無需原子操作鎖定及同步的開銷
-
方便切換控制流,簡化編程模型
-
高并發+高擴展性+低成本:一個CPU支持上萬的協程都不是問題。所以很適合用于高并發處理。
協程的缺點:
-
無法利用多核資源:協程的本質是個單線程,它不能同時將 單個CPU 的多個核用上,協程需要和進程配合才能運行在多CPU上.當然我們日常所編寫的絕大部分應用都沒有這個必要,除非是cpu密集型應用。
-
進行阻塞(Blocking)操作(如IO時)會阻塞掉整個程序
前文所述“子程序(函數)在執行過程中可以中斷去執行別的子程序;別的子程序也可以中斷回來繼續執行之前的子程序”,那么很容易想到Python的yield,顯然yield是可以實現這種切換的。

執行結果:
由執行結果可以證明g現在就是生成器函數。
用的是yield的表達式形式,要先運行next(),讓函數初始化并停在yield,然后再send() ,send會在觸發下一次代碼的執行時,給yield賦值
next()和send() 都是讓函數在上次暫停的位置繼續運行,
執行結果:
需要注意的是每次都需要先運行next()函數,讓程序停留在yield位置。
如果有多個這樣的函數都需要執行next()函數,讓程序停留在yield位置。為了防止忘記初始化next操作,需要用到裝飾器來解決此問題
執行結果:
請給Tom投喂食物
執行結果:
實現Linux中"grep -rl error <目錄>"命令,過濾一個文件下的子文件、字文件夾的內容中的相應的內容的功能程序。
首先了解一個OS模塊中的walk方法,能夠把參數中的路徑下的文件夾打開并返回一個元組:
返回的是一個元組,第一個元素是文件的路徑,第二個是文件夾,第三個是該路徑下的文件
這里需要用到一個寫程序的思想:面向過程編程
面向過程:核心是過程二字,過程及即解決問題的步驟,基于面向過程設計程序就是一條工業流水線,是一種機械式的思維方式。流水線式的編程思想,在設計程序時,需要把整個流程設計出來
優點:
1:體系結構更加清晰
2:簡化程序的復雜度
缺點:
可擴展性極其的差,所以說面向過程的應用場景是:不需要經常變化的軟件,如:Linux內核,httpd,git等軟件
下面就根據面向過程的思想完成協程函數應用中的功能
目錄結構:
程序流程
第一階段:找到所有文件的絕對路徑
第二階段:打開文件
第三階段:循環讀取每一行
第四階段:過濾“error”
第五階段:打印該行屬于的文件名
g是一個生成器,就能夠用next()執行,每次next就是運行一次,這里的運行結果是依次打開文件的路徑
我們在打開文件的時候需要找到文件的絕對路徑,現在可以通過字符串拼接的方法把第一部分和第三部分進行拼接
用循環打開:
結果:
將查詢出來的文件和路徑進行拼接,拼接成絕對路徑
執行結果:
用函數實現:
為了把結果返回給下一流程



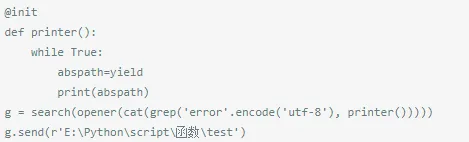
執行結果:
作者:炫維
來源:http://xuanwei.blog.51cto.com/11489734/1953449

